Five AI trends 2020 to keep an eye on
While making predictions may be easy, delivering accurate ones is an altogether different story. That’s why in this column we won’t just be looking at the most important trends of 2020, but we’ll also look at how the ideas we highlighted last year have developed.
In summarizing the trends of 2020, one conclusion we’ve come to is that society is getting increasingly interested in AI technology, in terms of both the threats it poses and common knowledge about other problems that need to be addressed.
AI trends 2019 in review – how accurate were our predictions?

In our AI Trends 2019 blogpost we chronicled last year’s most important trends and directions of development to watch. It was shortly after launching the AI Monthly Digest, a monthly summary of the most significant and exciting machine learning news. Here’s a short summary of what we were right and wrong about in our predictions.
- Chatbots and virtual assistants – powered by a focus on the development of Natural Language Processing (NLP), our prediction was accurate–the growth in this market would be robust. The chatbot market was worth $2.6 billion in 2019 and is predicted to reach up to $9.4 billion by 2024.
- the time needed for training would fall – the trend gets reflected by larger neural networks being trained in a feasible time, with GPT-2 being the best example.
- Autonomous vehicles are on the rise – the best proof is in our own contribution to the matter in a joint-venture with Volkswagen.
- Machine learning and artificial intelligence are being democratized and productionized – According to Gartner, 37% of organizations have implemented AI in some form. That’s a 270% increase over the last four years.
- AI and ML responsibility and transparency – the trend encompasses the delivering unbiased models and tools. The story of Amazon using an AI-based recruiting tool that turned out to be biased against female applicants made enough waves to highlight the need for further human control and supervision over automated solutions.
Apparently, deepsense.ai’s data science team was up to date and well-informed on these matters.
“It is difficult to make predictions, especially about the future.”
-Niels Bohr
The world is far from slowing down and Artificial Intelligence (AI) appears to be one of the most dominant technologies at work today. The demand for AI talents has doubled in the last two years with technology and the financial sector absorbing 60% of talented employees on the market.
The Artificial Intelligence market itself is predicted to reach $390.9 billion by 2025, mainly by primarily by automating dull and repetitive tasks. It is predicted that AI will resolve around 20% of unmet healthcare demands.
Considering the impact of AI on people’s daily lives, spotting the right trends to follow is even more important. AI is arguably the most important technology trend of 2020, so enjoy our list!
Natural language processing (NLP) – further development

Whether the world was ready for it or not, GPT-2 was released last year, with balance between safety and progress a guiding motif. Initially, OpenAI refused to make the model and dataset public due to the risk of the technology being used for malicious ends.
The organization released versions of the model throughout 2019, with each confirmed to be “hardened against malicious usage”. The model was considered cutting edge, though like most things in tech, another force soon prevailed. At the end of January 2020, Google Brain took the wraps off of Meena, a 2.6-billion parameter end-to-end neural conversational model trained on 341 GB of online text.
The convenience of NLP solutions is enjoyed by users who have embraced virtual assistants like Google Assistant, Alexa or Siri. According to Adroit Market Research, the market of Intelligent Virtual Assistants is predicted to grow at 33% compound annual growth rate between now and 2025. The market was valued at $2.1 billion in 2019. The increasing use of smartphones and other wearable intelligent devices, among other trends, is predicted to be a driver of the growth.
Started with a consumer-centric approach, virtual assistants are predicted to get more involved in business operations, further automating processes as well as tedious and repetitive tasks. According to Computerworld, approximately 40% of business representatives are planning to implement voice technology within 24 months – that is, no later than in 2021. NLP is shaping up to be a major trend not only this year, but well into the future.
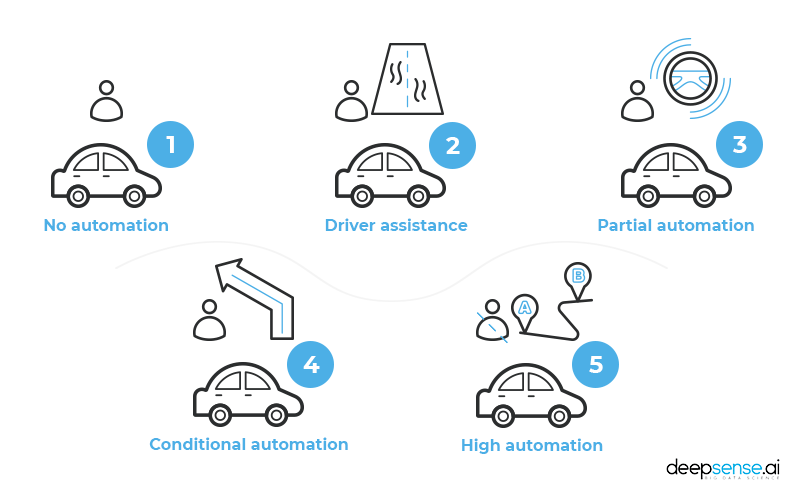
Autonomous vehicles

It is 2020 and driverless cars have yet to hit the streets. In hindsight, the Guardian’s prediction that there would be 10 million self-driving cars on the road by 2020 is all too easy to scoff at now.
On the other hand, tremendous progress has been made and with every month the autonomous car gets closer to rolling out.
deepsense.ai has also contributed to the progress, cooperating with Volkswagen on building a reinforcement learning-based model that, when transferred from a simulated to a real environment, managed to safely drive a car.
But deepsense.ai is far from being the only company bringing significant research about autonomous cars and developing the technology in this field. Also, it is a great difference between seeing an autonomous car on busy city streets and in the slightly less demanding highway environment, where we can expect the automation and semi-automation of driving to first get done.
According to the US Department of Transportation, 63.3% of the $1,139 billion of goods shipped in 2017 were moved on roads. Had autonomous vehicles been enlisted to do the hauling, the transport could have been organized more efficiently, and the need for human effort vastly diminished. Machines can drive for hours without losing concentration. Road freight is globally the largest producer of emissions and consumes more than 70% of all energy used for freight. Every optimization made to fuel usage and routes will improve both energy and time management.
AI getting popular – beneath the surface

There is a lot of buzz around how AI-powered solutions impact our daily lives. While the most obvious change may be NLP powering virtual assistants like Google Assistant, Siri or Alexa, the impact on our daily lives runs much deeper, even if it’s not all that visible at first glance. Artificial intelligence-powered solutions have a strong influence on manufacturing, impacting prices and supply chains of goods.
Here are a few applications being used without batting an eye:
- Demand forecasting – companies collect tremendous amounts of data on their customer relationships and transactional history. Also, with the e-commerce revolution humming along, retail companies have gained access to gargantuan amounts of data about customer service, products and services. deepsense.ai delivers demand forecasting tools that not only process such data but also combines it with external sources to deliver more accurate predictions than standard heuristics. Helping companies avoid overstocking while continuing to satisfy demand is one essential benefit demand forecasting promises.
- Quality control – harnessing the power of image recognition enables companies to deliver more accurate and reliable quality control automation tools. Because machines are domain-agnostic, the tools can be applied in various businesses, from fashion to construction to manufacturing. Any product that can be controlled using human sight can also be placed under the supervision of computer vision-powered tools.
- Manufacturing processes optimization – The big data revolution impacts all businesses, but with IoT and the building of intelligent solutions, companies get access to even more data to process. But it is not about gathering and endless processing in search of insights – the data is also the fuel for optimization, sometimes in surprising ways. Thanks solely to optimization, Google reduced its cooling bill by 40% without adding any new components to its system. Beyond cutting costs, companies also use process optimization to boost employee safety and reduce the number of accidents.
- Office processes optimization – AI-powered tools can also be used to augment the daily tasks done by various specialists, including lawyers or journalists. Ernst & Young is using an NLP tool to review contracts, enabling their specialists to use their time more efficiently. Reuters, a global media corporation and press agency, uses AI-powered video transcription tools to deliver time-coded speech-to-text tools that are compatible with 11 languages.
Thanks to the versatility and flexibility of such AI-powered solutions, business applications are possible even in the most surprising industries and companies. So even if a person were to completely abandon technology (right…), the services and products delivered to them would still be produced or augmented with AI, be they clothing, food or furniture.
AI getting mainstream in culture and society

The motif of AI is prevalent in the arts, though usually not in a good way. Isaac Asimov was among the first writers to hold that autonomous robots would need to follow a moral code in order not to become dangerous to humans. Of course, literature has offered a number of memorable examples of AI run amok, including Terminator and HAL 9000 from Space Odyssey.
The question of moral principles may once have been elusive and abstract, but autonomous cars have necessitated a legal framework ascribing responsibility for accidents. Amazon learned about the need to control AI models the hard way, albeit in a less mobile environment: a recruiting tool the company was using had to be scrapped due to a bias against women.
The impact of AI applications on people’s daily lives, choices and careers is building pressure to deliver legal regulations on model transparency as well as information not only about outcomes, but also the reasons behind them. Delivering AI in a black-box mode is not the most suitable way to operate, especially as the number of decisions made automatically by AI-powered solutions increases.
Automating the development of AI

Making AI mainstream is not only about making AI systems more common, but widening the availability of AI tools and their accessibility to less-skilled individuals. The number of models delivering solutions to power with the machine and deep learning will only increase.It should therefore come as no surprise that the people responsible for automating others’ jobs are keen to support their own jobs with automation.
Google enters the field with AutoML, a tool that simplifies the process of developing AI and making it available for a wider audience, one that, presumably, is not going to use ML algorithms in some especially non-standard ways. AutoML joins IBM’s autoAI, which supports data preparation.
Also, there are targeted cloud offerings for companies seeking to harness ready-to-use components in their daily jobs with a view to augmenting their standard procedures with machine learning.
Summary
While the 2020 AI Trends themselves are similar to those of 2019, the details have changed immensely, thus refreshing our perspective seemed worth our while. The world is changing, ML is advancing, and AI is ever more ubiquitous in our daily lives.