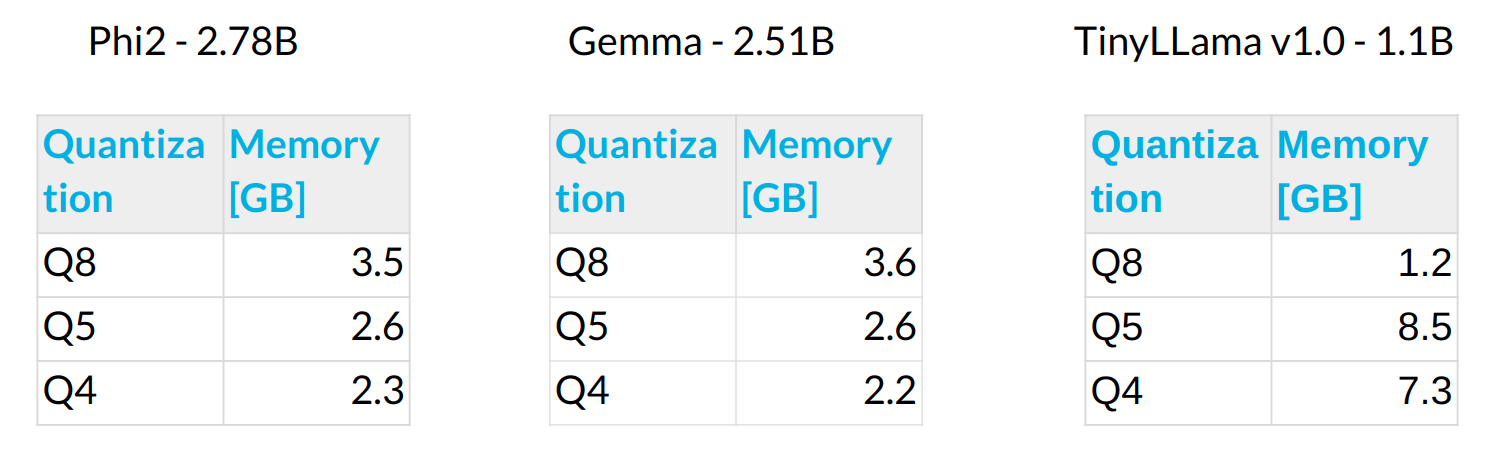
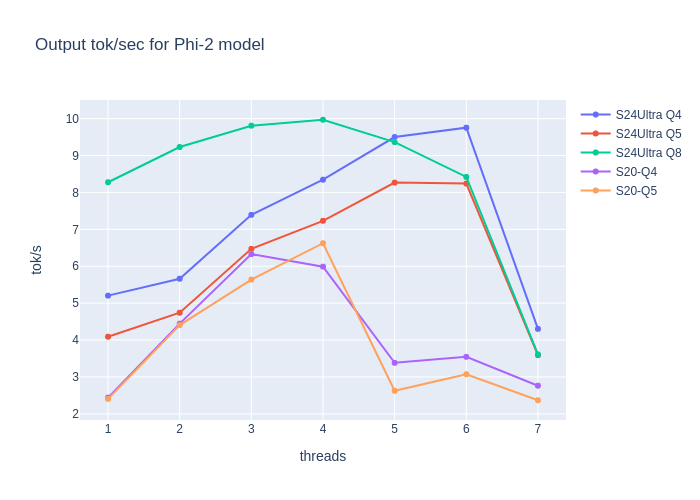
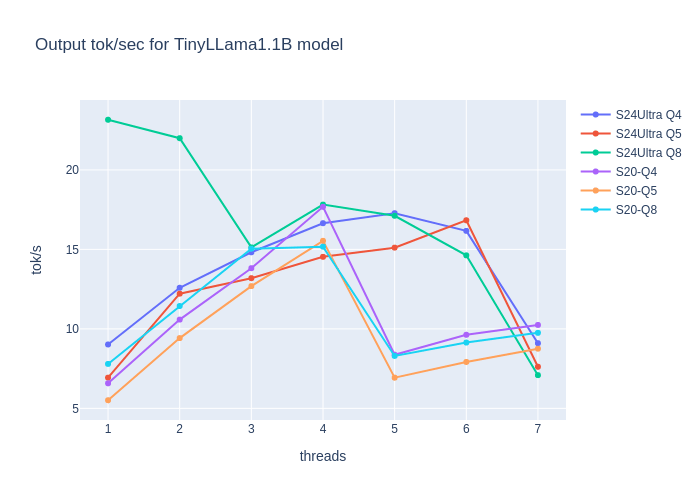
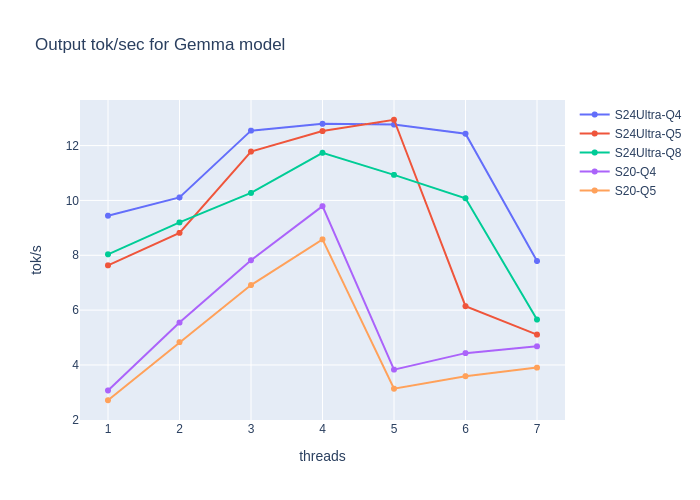
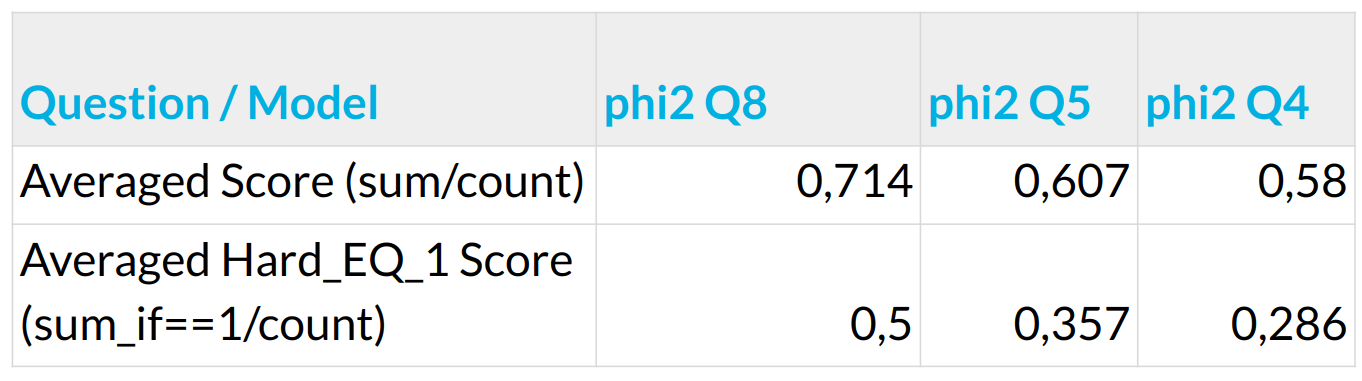
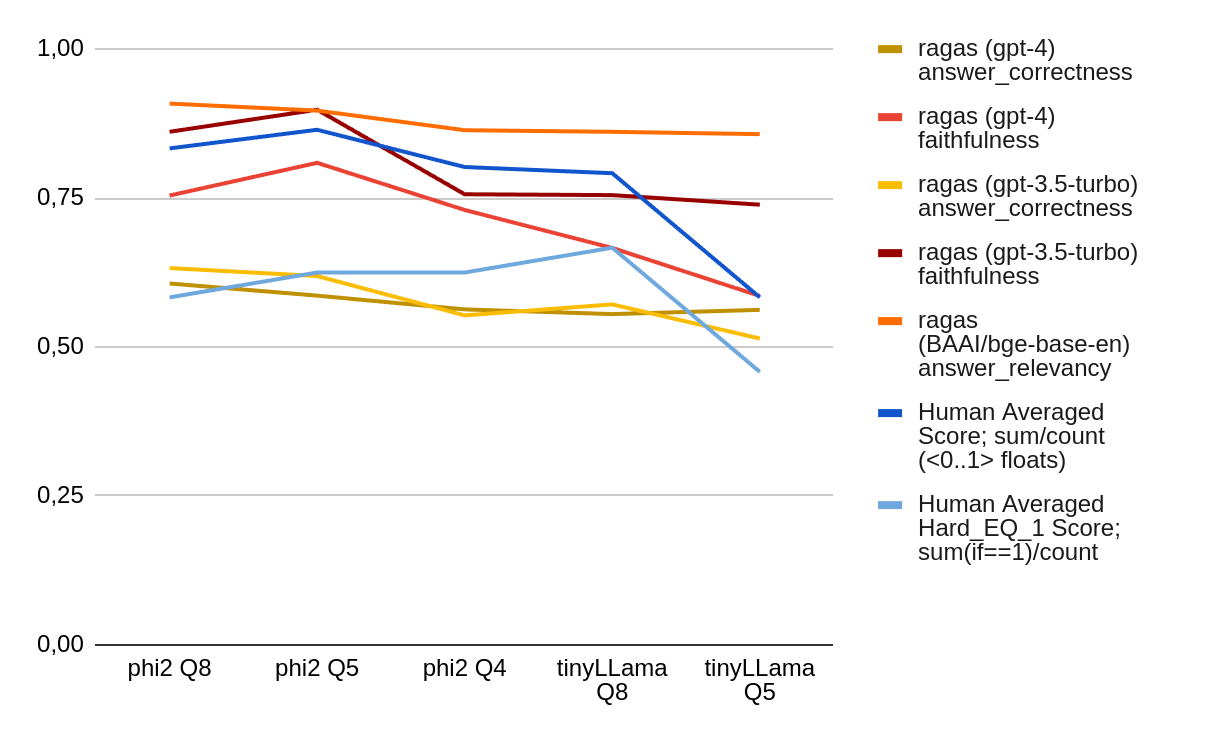
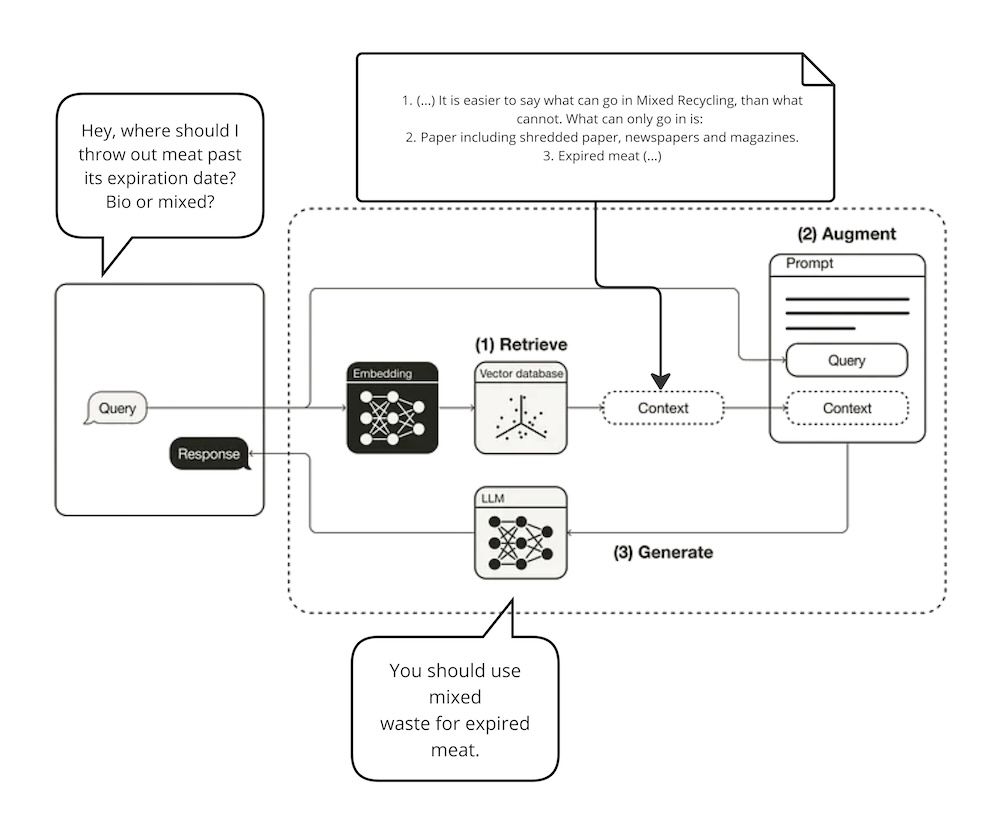
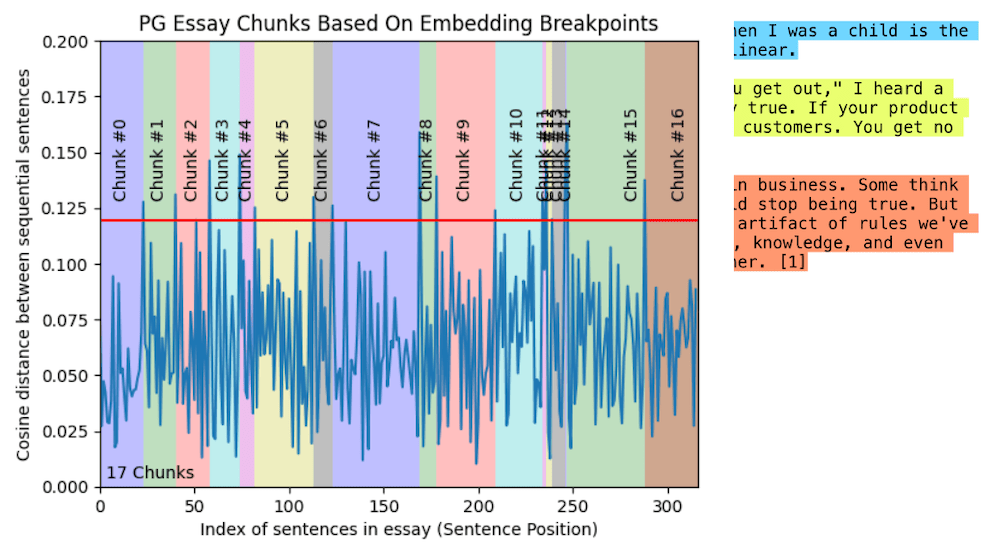
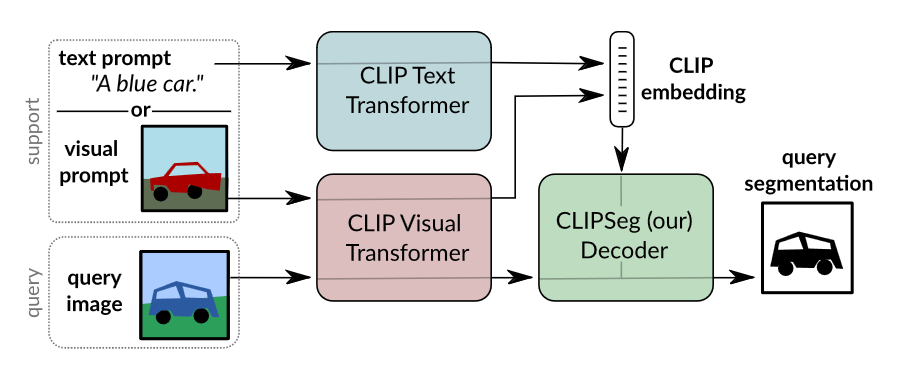
Optimizing Computational Resources for Machine Learning and Data Science Projects: A Practical Approach
Every computation requires computing resources. Sure, sometimes a regular calculator, a piece of paper, and a pencil are sufficient. However, in machine learning, powerful computing resources are necessary:
- The model needs to be fed with a massive amount of data.
- Appropriate calculations must be performed for each data point to process it into a pattern.
- Some parameters must be adjusted to teach the model the correct mappings, necessitating further recalculations and computational resources.
Your teammates also need to train models. Ultimately, the amount of computational resources is always insufficient. Nevertheless, there are ways to
- Reduce this deficit.
- Increase the utilization of available resources.
- Gain more freedom in developing your research or building a startup
This article may provide useful insights if you have encountered a similar situation.
Challenges of Computational Resource Allocation
At deepsense.ai, we specialize in addressing machine learning and data science challenges with custom solutions tailored to our client’s specific needs. With clients spanning various industries, we encounter diverse problems that demand adaptability and versatility. Our in-house computational resources are utilized for developing and testing these solutions. While cloud computing is trendy, it may not always be practical due to cost, availability of on-demand GPUs, or data confidentiality concerns.
When working on client projects, we often encounter a situation where multiple Machine Learning Engineers or Data Scientists need to share limited computational resources for their training sessions. Allocating these resources efficiently is challenging, especially during the solution design stage when we need to experiment with various parameters and models. Establishing a fixed schedule for resource usage is not feasible as we can’t always estimate the time required for computations.
Existing Solutions and Their Implications
It has become apparent that this issue is not unique to us, and that others have also encountered and addressed it. Solutions exist that may not fully resolve the problem, but can certainly mitigate it significantly. This challenge prompted the development of supercomputers and computing clusters, and we can draw upon their expertise. Furthermore, we can apply this knowledge to cloud resources, provided the need arises and opportunities arise.
Adopting SLURM for Efficient Resource Management
We have established our cluster using SLURM (formerly known as Simple Linux Utility for Resource Management). Our decision is based on several factors. First, SLURM supports all required resources, including CPU, RAM, and GPU. Second, it is compatible with the Linux operating system, Python, and other AI tools and models we commonly use. Third, SLURM is a stable and widely used solution. It is estimated that approximately 60% of the supercomputers on the Top500 list run on SLURM, and some of our staff have encountered it during their academic work.
How SLURM Enhances Resource Efficiency
This way, we have a tool that lets us “request” the resources needed to carry out a planned task. If the required resources are not available, the task will be queued and launched as soon as the resources become available. The workload manager will handle this without requiring the special involvement of an engineer at this stage. The engineer who submitted the task will receive email notifications when the task starts and ends. Since computing resources operate 24/7, this queuing method allows for more efficient use of resources, as tasks can be carried out outside of regular working hours. Additionally, with different types of resources available, one can “request” specific resource models or just a “type” of resource, which enhances the flexibility of this solution.
User Interaction with the SLURM Cluster
From the user’s perspective, we communicate with the cluster through a login node. This node is where tasks are prepared and configured before queuing and running. The controller, which knows the states of all compute nodes, then allocates the appropriate resources by assigning them to subsequent tasks in the queue.

Simplyfied schema of SLURM components. Icons source: draw.io
Optimizing SLURM Implementation for Machine Learning Workloads
When setting up our SLURM implementation, we carefully considered the available computing hardware, storage options, and data access performance and security requirements. The key conclusions we reached during this phase, and upon revisiting it after implementation, were as follows:
- Network: The cluster should have a fast internal network connection of at least 10Gbit. AI model training often involves large datasets that must reach the compute node(s) where the job will be run. Even if the node can quickly handle the task, it won’t be efficient if downloading data for computations significantly slows it down. Ideally, such a network should be redundant to avoid a single point of failure that could bring the entire cluster out of service.
- Data storage: Data should be easily accessible to each compute node, fast to read and write (since computation results need to be saved), and secure. A possible node failure should not affect the data on the node. NAS servers and distributed network file systems like Ceph can fulfill these requirements.
- Operating system unification. All compute nodes should run under the control of the same operating system version. The available system and programming libraries should also be identical on each node. We cannot allow a situation where the programmed task code cannot run because a node lacks a required library. We base our systems on Ubuntu, which allows us to create code on Ubuntu desktops and then run it on an Ubuntu cluster. This consistency makes it easier and faster for us to design and develop solutions.
- Computational libraries. The development of external libraries and models progresses every day. We need to work with different versions of libraries due to varying requirements. Given the number and variety of projects our engineers work on, each Machine Learning Engineer requires considerable disk space. Adding up the needs of all engineers only increases the complexity. We implemented a general library store using a network file system and LMOD to address this. This allows us to maintain only one copy of a given library (in a given version), available at any time on any node. Engineers can enable the libraries they need, disable the ones they don’t, or experiment with different library versions. This approach reduces the need to clean up environments of excess libraries.
- Temporary data. According to the architecture of such a cluster, users can only submit jobs through the access node and cannot select a specific compute node on which the job will run. Therefore, all necessary elements, such as code or temporary data, must be available on each compute node. Users upload the required files through the access node, and the compute nodes have immediate access to them. Distributed network file systems are ideal for this purpose. Examples include Ceph and Lustre. For data downloaded from NFS, we use FS-Cache, which works very well for frequently used files.
Example of Cluster Configuration
Let’s use the example of our test cluster, consisting of one access node, two compute nodes without GPUs, and two compute nodes with four GPUs each. If we develop the solution well, we can scale it quite freely (by adding more nodes) and implement it (or help with implementation) on the client’s infrastructure or in the cloud.
The backbone is a 2 x 10Gbps Ethernet network based on redundant switches, enabling speeds up to 20Gbps. This technology is reasonable in our case as it does not expose us to additional costs and offers good performance.
Data Management and Efficiency
For data storage, we will use a NAS array and a network FS (file system) built with the help of Ceph. At this particular moment, “data” should be understood as everything needed for work that must be saved on disk and available on each compute node: input data for calculations (mostly customer data), libraries, models, repositories, code, temporary data, etc. This setup will also allow us to react flexibly and distribute data properly depending on the quantity and type of projects we are working on. Additionally, Ceph allows us to manage engineers’ temporary data, such as models reasonably. If one engineer needs to use model X, this model is downloaded and saved in the temporary cache. If another engineer wants to use model X, he does not have to download it again because this model is already available in the cache. Over time, this workflow improvement will save disk space and enhance efficiency.
*A small off-topic here – we omit security issues such as data encryption, communication encryption, and permission management of who can see what, etc. These are beyond the scope of this article. However, they are considered, implemented, and practiced following industry standards.*
Efficient Library Management with LMOD
The next question was what we could do with the excess libraries needed by our engineers, downloaded and saved here and there. Perhaps some part (as it turned out – a significant one) could be shared by installing them once, in one place, and making them available “in one go” to all nodes. Drawing on the experience of others, we used LMOD, an environment modules system. It allows you to make both libraries and programs available as loadable modules. This, in turn, gives the ability to quickly and easily switch between different libraries or programs and between their versions. At the same time, we save space and time because one copy of the software is installed and made available for general use. From our point of view, it is important to switch easily between different versions of Python or CUDA and test different versions of AI-related libraries such as PyTorch, Numpy, TensorFlow, and many others.
Practical Configuration of a SLURM Cluster
Access Node and Cluster Controller
Our access node will also be the cluster controller, running two main cluster services: slurmctld and slurmdbd. If you have the option, separating these services and the access node into three independent machines is worth separating. This solution is more sensible in large environments (actual supercomputers, university labs, etc.). However, we are not building a supercomputer; we are effectively utilizing available hardware resources. Moreover, we have checked our needs and capabilities, and tests have shown that this solution fully meets our needs.
Node Authentication with Munge
SLURM uses Munge to authenticate communication between nodes. This service should be installed and launched with the same (secret) key on all nodes to communicate with each other. It’s important to have Munge working before starting SLURM.
Configuring slurmdbd Service
The slurmdbd service saves information about executed tasks to the database. This is useful for statistical and accounting purposes – we can verify how many resources a given project or type of task consumed, how many tasks individual users launched, etc. Its configuration is simple and comes down to specifying database connection parameters (MySQL or MariaDB). Example configuration files are well documented. The most important options to configure are:
AuthType=auth/munge AuthInfo=/run/munge/munge.socket.2
StorageType=accounting_storage/mysql DbdHost=db-host.example.com StorageLoc=slurm_DB StoragePass=ThePasswordThatShouldBeProtected StorageUser=slurm StorageHost=slurm-ctlr.example.com
So, the previously mentioned authentication using Munge and the access data for the database.
Configuring slurmctld Service
The main controller is the slurmctld service. It is responsible for queueing tasks, allocating resources, and monitoring the states of nodes. Its configuration can be divided into two parts: the configuration of the load and resource manager and the actual resources of the cluster. The manager configuration is very rich in options, and it is worth studying the documentation to set the appropriate options for yourself. Let’s define our cluster:
AuthType=auth/munge ClusterName=slurm-lab SlurmctldHost=slurm-ctrl.example.com GresTypes=gpu
As we already know, we use Munge for authentication. We name our cluster, specify the controller’s host, and define the GPU type resource (Gres means Generic RESource) as a resource that the controller is about to manage.
Scheduling and Resource Selection
SchedulerType=sched/backfill SelectType=select/cons_tres SelectTypeParameters=CR_CPU_Memory
Backfill is the default plugin for managing the schedule in SLURM. It results in better utilization of the entire cluster, e.g., lower-priority tasks will be run if they do not interfere with the (predicted) execution of higher-priority tasks. The select/cons_tres plugin (in conjunction with the OverSubscribe parameter set for partitions) determines the ability to share unused resources (as opposed to the select/linear plugin, which operates at the level of entire nodes). Finally, the CR_CPU_Memory parameter sets the “logical” processor and memory as the “units” that we operate on when allocating resources (as opposed to, for example, CR_Core or CR_Socket). We can also use the CR_CPU parameter – then RAM will not be tracked when allocating resources to tasks.
Many other parameters allow us to adjust the cluster’s operation to our needs. For example, we can specify programs that will be run before and/or after the actual computational tasks, parameters for accounting statistics (duration, allocated resources, projects, etc.), or power-saving management. The flexibility of configuration is high.
Defining Cluster Resources
It’s time to define our resources. In this part, we define nodes – they can differ in parameters such as the availability or not of GPUs, the type of GPUs, but also simply the amount of CPUs and RAM. Therefore, it is necessary to describe well what they have so that the controller knows how it can allocate tasks depending on the requested resources, e.g.:
NodeName=lab-gpu-01 RealMemory=122880 Sockets=2 CoresPerSocket=12 ThreadsPerCore=2 Feature="rtx4080" Gres=gpu:4
The lab-gpu-01 node has 120GB of RAM (the amount of memory we want to allocate for executing tasks assigned in the cluster), 2 processors with 12 cores each, and each core can execute two threads, along with 4 GPUs. By specifying the “Feature” parameter, you can introduce an additional level for the requested resources. For example, if there are different GPUs or CPUs in the nodes, you can request the execution of a task on a specific type of desired resource. If we don’t specify anything, the task will be launched on the first available resource (in the requested quantity). Additionally, in the gres.conf file, we define these generic resources (in our case, GPUs) more precisely, for example:
NodeName=lab-gpu-01 Name=gpu File=/dev/nvidia[0-3]
In this way, SLURM will know that the devices /dev/nvidia[0-3] are responsible for GPU-type resources, allowing it to allocate them (and block other tasks from using them).
Organizing Nodes into Partitions
Finally, we organize nodes into partitions, which are logical groups of nodes. A node can belong to more than one partition, but this should be carefully considered and probably tested in practice. The minimum is to create one partition and put all nodes into it, and the controller will handle organizing tasks according to the requested resources. However, we can (in our example) divide partitions based on resources. For example, one partition has nodes with GPUs, and another has nodes without GPUs. Example:
PartitionName=ml-cpu Nodes=lab-cpu-[01,02] Default=YES MaxTime=5-00:00:00 DefaultTime=04:00:00 State=UP AllowGroups=ml-users PartitionName=ml-gpu Nodes=lab-gpu-[01,02] MaxTime=5-00:00:00 DefaultTime=04:00:00 State=UP AllowGroups=ml-users
We have two partitions with two nodes each: one partition only with CPU nodes (and this is the default partition) and the other with GPU nodes. We also specify the maximum job duration for 5 days, the default for 4 hours, while AllowGroups tells us that only users in the ml-users group can use these partitions.
Please note that most of the above features/parameters are highly individual. Available resources are an obvious determinant, but the specifics (needs) of users and, finally, the type of projects (i.e., tasks being run) will significantly influence the final configuration.
Verifying Cluster Configuration
We can check the status of the configured cluster by executing the sinfo command on the controller, and the result should look as follows:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST ml-cpu* up 5-00:00:00 2 idle lab-cpu[01-02] ml-gpu up 5-00:00:00 2 idle lab-gpu[01-02]
Practical Experiences with Using SLURM
Accessing the Cluster
Time to start calculating our models. We gain access to the cluster via SSH through the login node, which in this case is the controller. It is on this node that we configure, prepare, and later run computational tasks. Therefore, we can upload the necessary input data for computations or code, or use SSH to download the code from a repository and prepare a virtual environment. Whatever we need. We should remember that because we are using network file systems shared between nodes, all our preparations will be immediately available on every compute node.
Tasks can be run in two modes:
- Interactive Mode: Use the srun or salloc commands. Remember that such tasks are run “here and now” (depending on resource availability). If our SSH session is interrupted, the running task will also be interrupted, and resources will be released.
- Batch Mode: Using the sbatch command along with the sbatch script. Such a task is put into the task schedule and will run (from our point of view) in the background. After starting it, you can immediately disconnect from the access node and, for example, wait for an email notification about its completion.
Interactive Task Example
Interactive tasks are useful for verifying if our computation preparations are working correctly, for example, if we have included all the necessary libraries, if the correct paths to data have been provided, and finally, if the code itself is invoked correctly. For example:
srun -p ml-gpu \ -N 1 \ --ntasks-per-node=1 \ --mem-per-cpu=10GB \ --gres=gpu:1 \ --constraint="rtx4080" \ --time=2:00:00 \ -A LAB-test \ --pty /bin/bash -l
We are launching a task on the (-p) ml-gpu partition, allocating one node (-N), one CPU core (—-ntasks-per-node), 10GB of memory (—-mem-per-cpu), and one GPU card (—-gres) of type rtx4080 (—-constraint), for a duration of 2 hours (—time) within the LAB-test project (-A). Finally, the task itself is to run a bash shell there.
This way, we get access to a compute node with the requested resources allocated. Then we load the necessary LMOD modules, e.g.:
module load apps/python/3.10 module load apps/cuda/11.7 module load libs/python/torch/1.13.1-cuda-11.7-python-3.10 module load libs/python/neptune-client/1.9.1-python-3.10
Thanks to LMOD, we immediately get access to the required Python version, CUDA libraries, and PyTorch, as well as the appropriate Neptune library, which allows us to save computation results for easy and efficient analysis later on. Assuming we have several available versions of such programs or libraries, switching between them is easy, making it easier to develop our code. Finally, we run the code itself, e.g.:
source ~/venv/bin/activate python ~/code/program.py --data=/path/to/source/data
If necessary, we make appropriate corrections – add libraries, fix the code, and upload additional data. When everything is working correctly, we end the interactive session with:
logout
Returning to the access node, and according to the above (tested) experience, we prepare an sbatch script with the following content:
#!/bin/bash -l ## Project name #SBATCH -A LAB-test ## Task name #SBATCH -J Experiment-01 ## E-mail notifications about job progress #SBATCH --mail-type=BEGIN,END,FAIL #SBATCH --mail-user=username@example.com ## Number of nodes #SBATCH -N 2 ## Tasks per node (by default it is amount of CPU cores per node) #SBATCH --ntasks-per-node=20 ## RAM amount per computing core #SBATCH --mem-per-cpu=5GB ## Maximum task duration (format D-HH:MM:SS) #SBATCH --time=1-00:00:00 ## Partition select (by default ml-cpu, according to SLURM config) #SBATCH -p ml-gpu ## Amount of GPU per node #SBATCH --gres=gpu:4 ## Save outpu logs to file #SBATCH --output="/home/username/slurm-logs/experiment-01.%j-%N.out.log" ## Save error logs to file #SBATCH --error="/home/username/slurm-logs/experiment-01.%j-%N.err.log" ## We may request specific feature - rtx4080 in this case #SBATCH --constraint="rtx42080" ## Now we repeat steps checked during interactive task ## which is: load necessary modules module load apps/python/3.10 module load apps/cuda/11.7 module load libs/python/torch/1.13.1-cuda-11.7-python-3.10 module load libs/python/neptune-client/1.9.1-python-3.10 ## activate v-env and launch job source ~/venv/bin/activate python ~/code/program.py --data=/path/to/source/data
Please note that in the sbatch script, all comments start with ##. On the other hand, #SBATCH indicates parameters passed to SLURM – these must be understandable and acceptable to it.
Running the Batch Job
This time, we want to run the task on 2 nodes from the ml-gpu partition. On each of them, we allocate 20 cores with 5GB of memory for each core (i.e., 100GB per node) and 4 GPUs. We additionally specify that these should be rtx4080 cards. The task should not take longer than 1 day.
The above parameters are an example. In practice, some tasks take several days to compute. But there are also (rarely) situations where we can use most (or even all) of our resources for one task—then, in turn, the task’s duration is significantly shortened. Of course, information on how to select parameters and time estimates comes with experience, but we already have some, and after all, we want to use our resources more efficiently.
Finally, we specify in which case (BEGIN, END, FAIL) and to which address notifications about the job status should be sent.
From now on, we can run as many such tasks as we need. If the requested resources are insufficient, the tasks will be queued. From there, they will be launched as resources become available. So, after a whole day of preparing code and calculations, we can safely queue them and go for a well-deserved rest, returning the next day to find the calculations in progress or even the results ready.
Conclusion
We wanted to effectively use our computing resources. We have a variety of hardware, both old and new. However, we can use each resource to the limits of its capabilities. Ultimately, this translates into our calm and efficient work and customer solutions. SLURM itself is great, flexible, and has enormous possibilities. Combined with network FS, LMOD, and thoughtfully designed resource partitioning, we have a tool that allows us not to (im)patiently wait for computing resources. Of course, these are always in short supply, but a cluster working 24/7 makes access to them easier for us.
Let us know if you need professional consultation, help with your SLURM configuration, or have questions about the above article!
Links: