Generative AI developer toolkit
A thrilling adventure in the world of next-gen programming awaits, powered not by replacing humans with AI, but by using AI to enhance human potential. In this blog post we will discuss the most interesting and powerful GenAI tools that you should know more about.
In recent times, the rapid advancement of AI technologies like ChatGPT and other Large Language Models (LLMs) have sparked growing panic among the software engineering community. Headlines warning of the looming robot takeover have fueled this unease, making developers question the future of their occupation. As technology evolves, it’s natural that we, as developers, feel apprehensive about the impact of AI on our careers. But worrying about robots taking over your job can only be harmful and hinder your development. Instead of dreaming up dystopian visions, it is better to know the possibilities that AI tools like GitHub Copilot or ChatGPT open up to complement and streamline your workflow. By embracing emerging generative AI, you can supercharge your efficiency and enrich your value in the ever-competitive job market, proving that you are adaptable and ready for whatever the future brings.
Don’t give up on being a developer
According to a 2019 report by the UK Office for National Statistics, software engineers face a 27.4% probability of their roles being replaced by robots. Yet this statistic is not exclusive to software engineers: many occupations across various sectors have seen a similar or higher figure projected. Despite being harbingers of fear, these statistics need to be understood in context. They certainly don’t consider the current limitations that AI possesses, nor its inability to replace key human skills.
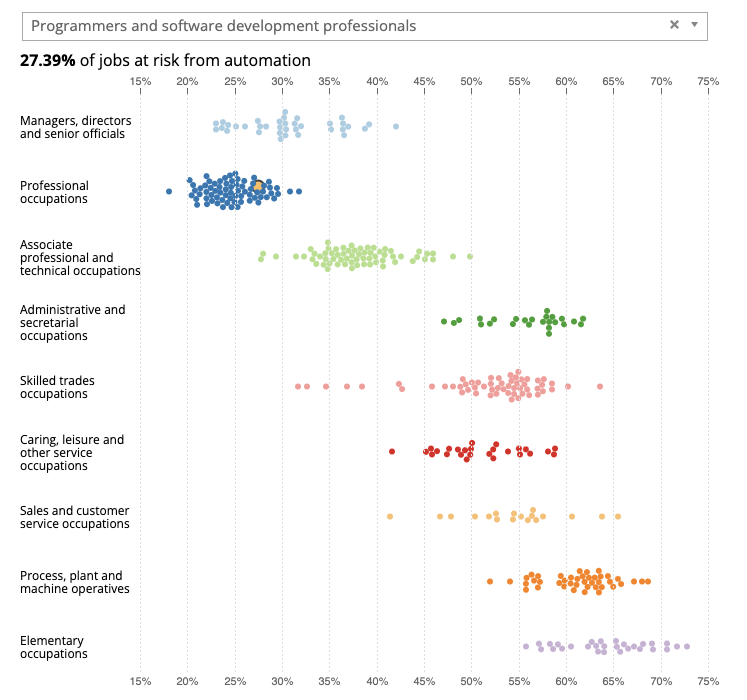
Chart 1 – Occupations at risk of being automated. The yellow dot represents programmers and software engineers. Source.
At present, for all its impressive capabilities, AI technology cannot replicate human creativity, intuition and critical thinking. ChatGPT or GitHub Copilot, while perfectly competent at suggesting individual lines or blocks of code, lack the intuitive semantic understanding that developers possess. The tools also understand neither the broader context nor intent of code nor the larger architectural design decisions. These are elements that are profoundly human and cannot be easily learned by current LLMs, even the best ones.
Finally, an important observation to bear in mind is that developers who resist embracing these new-age tools aren’t in danger of being replaced by robots, but rather by other developers who choose to adapt and evolve. There is an increased demand in the job market for developers who are capable of adopting AI tools and willing to do so, with employers valuing the higher efficiency and enriched skill set that these individuals bring to the table.
Understand what’s going on – the LLM tsunami
In the midst of the burgeoning LLM wave, burying your head in the sand is not a viable solution. Instead of retreating to a corner, take the proactive route to understanding how these developing tools work. Equip yourself with knowledge, dive into the mechanics, and prepare to ride the wave instead of being consumed by it.
First and foremost, acquaint yourself with the general architecture of LLM models. Just as if you were learning a new framework or library, it’s crucial to understand its underlying assumptions and considerations first. Remember, curiosity is your greatest ally. Understanding the datasets these models are trained on, the process of training, and most importantly their limitations, can give you a well-rounded perspective of the tools that are based on them.
You may worry that this sounds like it might require a data scientist’s level of expertise. Don’t worry – you don’t need to dive deep into the intricate matrix of machine learning algorithms and neural networks. A high-level overview of the concepts is all you need. You don’t need to become an expert overnight, but getting your hands dirty and exploring their different functionalities is a concrete step forward.
Now that you have laid the groundwork, it’s time to learn the art of crafting better prompts. A good prompt is instrumental in how helpful these AI tools will prove to be. There are many resources available to sharpen this skill, including free courses by deeplearning.ai that offer excellent training or customized workshops like those offered by deepsense.ai.
This newfound knowledge of generative AI tools will stand you in good stead in the dynamic landscape of software development. Think of it as a lifelong learning process, not a sprint to the finish line. By understanding the currents of the LLM tsunami, you can learn to navigate them and utilize these AI tools to supercharge your workflow and provide the edge you need in a continually evolving job market.
Play with in-editor code generators
The journey of code generation spans a significant timeline. Some may recall the tools that produced Java classes from UML diagrams. Contemporary Integrated Development Environments (IDEs) can create standard code segments utilizing template systems, streamlining the development process by facilitating actions such as method extraction, renaming, and other refactoring techniques.
However, today’s code generation tools have evolved to be much more advanced and resourceful, courtesy of Large Language Models (LLMs). These models, trained on millions of lines of code, possess the capacity to comprehend the essential context, language syntax, and rules, and most impressively, they can independently craft the desired code.
The fundamental workflow of these tools is to propose code snippets as you type. Let’s begin with GitHub Copilot.
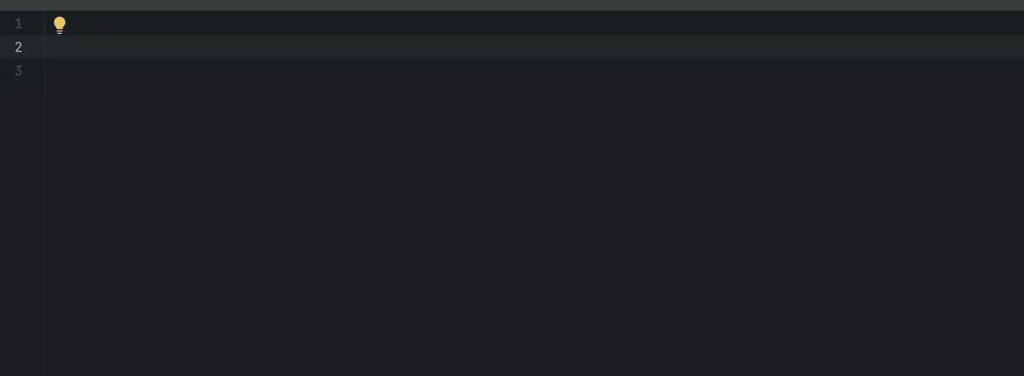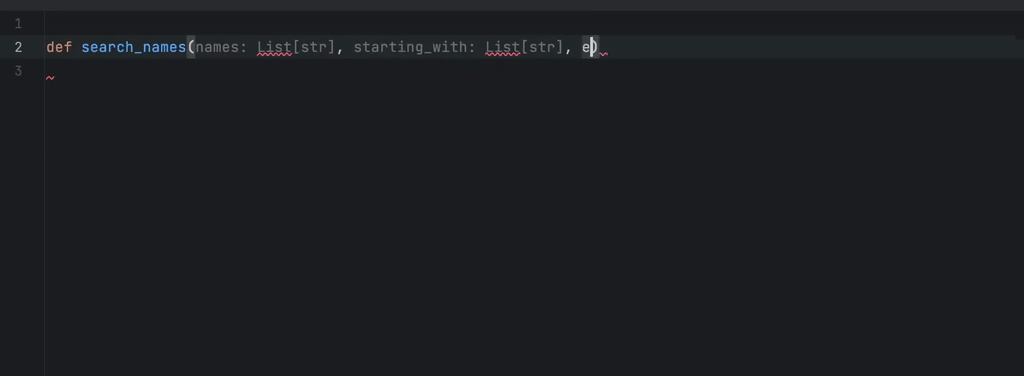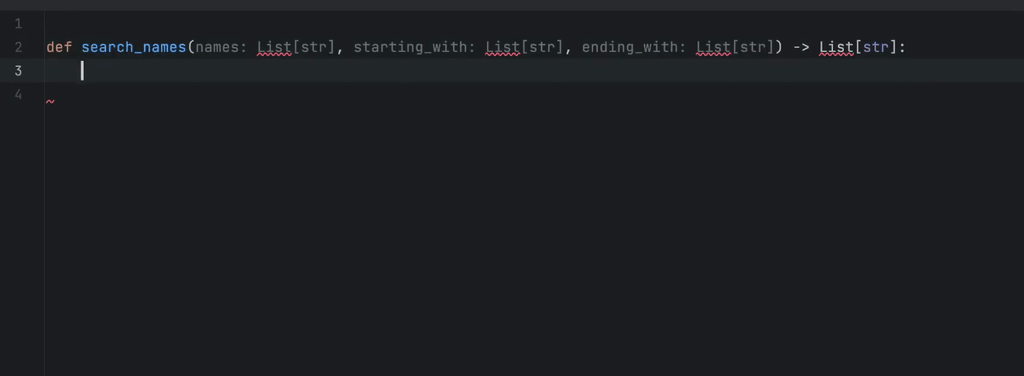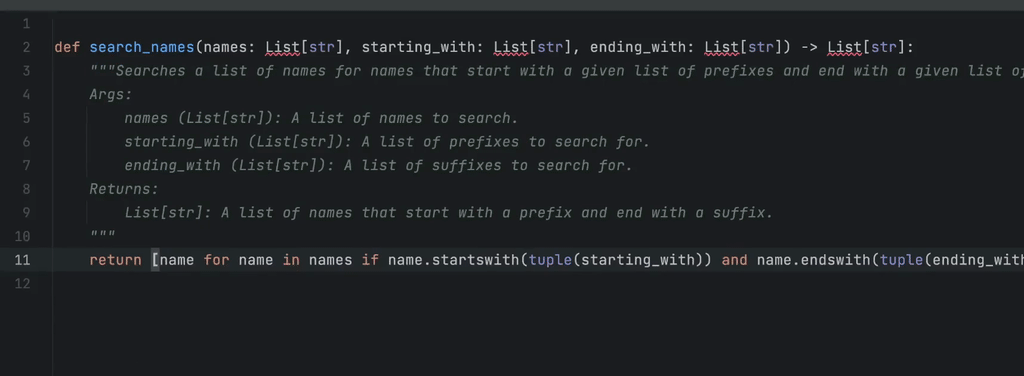
An example of in-line completions. The programmer starts typing a Python function that is about to find names in a collection of strings, whose prefix is one of the elements of the starting_with list and whose suffix is one of the elements of ending_with. GitHub Copilot found a proper solution and filled the docstring as well.
GitHub Copilot is an IDE plugin, compatible with MS VisualStudio, VisualStudio Code, JetBrains IDEs and even NeoVim. This plugin leverages the Codex model, an OpenAI creation that is diligently developed, trained, and maintained. The architecture of this tool is not overly complex – the pivotal element is the “client” segment of the plugin, which is responsible for prompt formulation. This prompt is then forwarded to the model backend service, and the response is utilized to generate a code suggestion.
Crucial to creating relevant and sensible code suggestions is the prompt itself – as I mentioned earlier, I wasn’t fibbing. The plugin garners specific metadata about the surrounding code – the currently open file, the code snippets from neighboring tabs, the programming language, the filename, and more. While this may set off cybersecurity concerns, we will delve into this discussion in an upcoming section.
Now that we have a basic understanding of GitHub Copilot’s functionality, comprehending its second mode – code generation from within comment descriptions – becomes simpler.
Example of completion made from in-comment description. GitHub Copilot is asked to create a fully working application. While some elements are stubbed (e.g. database connection), the rest of the code is correct.
This mode is closer to the way we use ChatGPT – we’re asking the plugin to generate code that is described in natural language. A crucial skill here is to be as specific as possible, while using simple language at the same time. Keep in mind that you cannot expect the plugin to create a fully working product for you – it’s much better to construct highly specified parts of the code which can be described using the Single Responsibility Principle. This makes us – developers – safe in the place we’re working in ;).
The market quickly understood the potential of tools like GitHub Copilot; that’s why Amazon released their own version of a code generation plugin – Amazon Code Whisperer. The way it works is almost the same as with the GitHub product. There are basically two modes we can work with. Amazon took more care over the origin of the completion. We have better control over the source of the suggestion that the tool proposes and whether it matches some open source code with limited licensing.
The number of LLM-based code generators is growing and we can expect the market to deliver at least one a week. At the time of writing, tools like Tabnine, JetBrains AI Assistant or Codeium are worth mentioning.
As evidenced, the realm of coding assistant tools is expanding rapidly. An eager developer might say, “Alright, give me the best one, and I’ll start using it!” However, the hitch is these tools are challenging to compare. Comparisons of code generators are available, but they do not explicitly rank one tool as superior over another. They do, however, offer some valuable insight:
-
Adhering to best practices in terms of code naming, simplicity of structure, etc., makes your code more intuitive for the tools to interpret. The old adage that “the quality you give is the quality you get” holds true – provide superior quality code and receive improved suggestions in return.
-
The tools can sometimes anticipate your desired output even with just a few words of a function name. However, this isn’t a golden rule and generally applies to basic scenarios.
-
The inclusion of descriptive names, type hints and documentation (like Javadoc or Python docstrings) significantly enhances the quality of code completion suggestions.
The overarching advice is to focus less on which tool to choose and more on how to utilize it efficiently. The quality of the suggestions is largely influenced by your coding approach and how you express your expectations, rather than the inherent quality of a specific tool. Moreover, anticipate swift evolution and frequent shuffling in the rankings of these tools in the upcoming months. While staying up to date with market trends is beneficial, frequently jumping from one tool to another is detrimental.
Prioritizing enduring skills such as prompt formation over mastering a particular tool bears a resemblance to learning universal coding principles instead of trying to memorize every aspect of a specific framework. When your foundational skills in prompting are well-honed, transitioning to a different tool becomes a breeze.
Discover the power of the GPT model
With the launch of ChatGPT by OpenAI, the tech industry encountered a ground-breaking game changer. Professionals are still discovering new practical use cases for this remarkable tool. This definitely holds true for programming – developers can use this chat-style tool in pair programming sessions as a digital partner.
ChatGPT can be employed to generate code, much like the integrated tools we’ve previously discussed. The key lies in crafting the appropriate prompt and providing all of the necessary context. Playing with the system in this manner not only presents an educational opportunity but also provides insights into how to utilize these integrated tools more efficiently.
What truly captivates our interest is the vast array of applications not strictly related to code writing; instead, they enhance various other tasks that developers routinely tackle. These include:
-
Creating concise but descriptive names: It’s a well-known joke amongst developers that naming conventions and cache invalidation are the two hardest aspects of programming. Thankfully, heeding the first problem is now an ace up your sleeve.
-
Comparing libraries, frameworks, and platforms: The GPT model has compiled a wealth of knowledge, allowing you to probe its database for comparisons between two solutions, while focusing on the aspects that particularly interest you.
-
Generating sample data: By supplying a data structure (in any format), you can instruct it to generate sample data for use in tests.
-
Code improvements: By simply pasting a snippet of code, ChatGPT can suggest improvements, and sometimes even spot bugs.
The ongoing evolution of Integrated Development Environments (IDEs) alongside developers’ tools indicates a clear shift towards integrating intelligent assistants into the daily life of a developer. Embrace these emerging technologies today and explore the plethora of tasks that the GPT model can facilitate. This will enable a smooth transition to using specialized, dedicated tools in the future.
Give various LLM-based assistants a chance
In today’s ever-evolving technological landscape, leveraging large language models (LLMs) to develop innovative digital products is easier than ever before. One can lean on proprietary offerings such as the OpenAI API or opt for self-hosted LLMs, depending on individual project requirements. While technical execution might not be straightforward but is at least well covered by the right LLMOps practices, the true challenge and artistry lies in utilizing LLMs creatively to address and resolve specific problems, and in designing the perfect prompts to do so. The potential of LLMs has already been recognized and harnessed by individuals and organizations alike, resulting in an array of solutions uniquely equipped to tackle specific challenges.
This burgeoning trend extends well into the realm of coding-related activities. Take phind.com, for instance. This cutting-edge, LLM-powered assistant for developers enables users to resolve complex programming conundrums step by step.
Meanwhile, a Chrome extension named codereview.gpt is revolutionizing the way developers engage with GitHub and GitLab platforms. When you’re drained but still staring at a queue of three pull requests, CodeReview.GPT is your ally. The tool analyzes proposed changes, identifies code smells and typos, and even suggests improvements, making code reviewing efficient and adaptive.

CodeReview.GPT
But it’s not just developers who are benefiting from these advancements. Data scientists and analysts who favor Jupyter notebooks can take advantage of genai. This tool seamlessly integrates with your notebook setup and provides intuitive hints and solutions for coding obstacles you may encounter within your cells.
The power shared by these versatile tools stems from their foundation on LLMs. While the implementation of LLMs is technically quite demanding, the real challenge and the secret to success lies in crafting the most effective prompts for any given user task. This underlines the importance of mastering the art of setting effective prompts – a sophisticated blend of skills that draws from both technical understanding and creative thinking.
Security considerations
As we journey deeper into the world of generative AI tools, it is imperative that we address the elephant in the room – security. Like any technology, tools such as GitHub Copilot or ChatGPT aren’t devoid of potential risks. While they offer numerous efficiencies and streamlining possibilities, caution must be exercised to ensure secure usage.
The most significant concern arises from the fact that these tools learn from public code repositories – they don’t possess the ability to differentiate between confidential proprietary code and public code. This could inadvertently risk the exposure of sensitive data.
Furthermore, there’s the concern of a tool like GitHub Copilot generating code snippets that it learned from open-source projects or libraries that come with strict licensing conditions. The usage of such pieces of code, without complying with these conditions, could lead to potential legal or compliance issues.
However, these limitations shouldn’t deter you from leveraging generative AI tools. Rather, they should reinforce the importance of a transparent, well-structured approach to the adoption of these tools.
To safely navigate these security concerns and prepare your company for the change, adopt a strategy that includes:
-
Implementing comprehensive access controls and guidelines to ensure the secure and responsible use of AI tools.
-
Regularly updating your risk assessment protocols to include artificial intelligence tool applications.
-
Training your team not only in the functional use of these tools but also educating them about the associated risks and how to circumvent them.
Instances where sensitive information accidentally trickles into the AI training data can be addressed by employing secure coding practices and routine data audits. Policies should be put in place that restrict AI access to sensitive information to the bare minimum.
In conclusion, adopting AI tools like GitHub Copilot or ChatGPT requires a cautious balance. On one hand, you should cautiously respect the potential risks; on the other hand, you shouldn’t be dissuaded from harnessing the immense benefits these tools offer. View these security aspects not as impediments, but as crucial components of your journey towards integrating AI into your everyday coding practices.
Summary
The choice of AI-based tools for coders has exploded in the last few months. As professionals, we could have ignored them and even stuck to the good old vi editor. But times are changing and a conscious developer should adapt to be more effective and valuable on the market. It’s the best time to start learning the new way of coding – even if not in your current project (due to security restrictions), try it in your pet project or programming exercises (coding katas).
The way software is being created is definitely evolving – starting with no-code and low-code solutions that help companies deliver products faster and with lower costs, to coding enhancing tools like Copilot that make developers more efficient, to Large Language Models that even help in architecture and business decision-making processes. Place yourself in this new landscape of the IT industry by starting your journey with a generative AI toolkit.