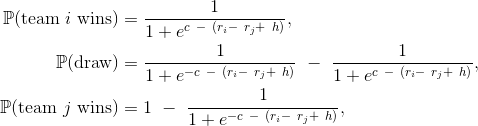Underground mining poses a number of threats including fires, methane outbreaks or seismic tremors and bumps. An automatic system for predicting and alerting against such dangerous events is of utmost importance – and also a great challenge for data scientists and their machine learning models. This was the inspiration for the organizers of AAIA’16 Data Mining Challenge: Predicting Dangerous Seismic Events in Active Coal Mines.
Our solutions topped the final leaderboard by taking the first two places. In this post, we present the competition and describe our winning approach. For a more detailed description please see our publication.
The Challenge
The datasets provided by organizers comprised of seismic activity records from Polish coal mines (24 working sites) collected throughout a period of several months. The goal was to develop a prediction model that, based on recordings from a 24-hour period, would predict whether an energy warning level (50k Joules) was going to be exceeded in the following 8 hours.
The participants were presented with two datasets: one for training and the other for testing purposes. The training set consisted of 133,151 observations accompanied by labels – binary values indicating warning level excess. The test set was of a moderate size of 3,860 observations. The prediction model should automatically assess the danger for each event, i.e. evaluate the likelihood of exceeding the energy warning level for each observation.
The model’s quality was to be judged by the accuracy of the likelihoods measured with respect to the Area Under ROC curve (AUC) metric. This is a common metric for evaluating binary predictions, particularly when the classes are imbalanced (only about 2% of events in the training dataset were labeled as dangerous). The AUC measure can be interpreted as the probability that a randomly drawn observation from the danger class will have a higher likelihood assigned to it than a randomly drawn observation from the safe class. Knowing the interpretation it is easy to assess the quality of the results: a score of 1.0 means perfect prediction and 0.5 is the equivalent of random guessing. (Bonus question for the readers: what would a score of 0 mean?).
Overview of the data
What constitutes an observation in this dataset? An observation is not a single number but a list of 541 values. There are 13 general features describing the entire 24 hour-long period, such as:
ID of the working site;
Overall energies of bumps, tremors, destressing blasts and total seismic energy;
Latest experts’ hazard assessments.
The remaining features are 24 hour-long time series of the number of seismic events and their energies.
Apart from the above data, the participants were provided with metadata about each working site. This was mostly information specific to a given working site, e.g. its name.
Our insights
The very first and one of the major tasks facing a data scientist is getting familiar with the dataset. One should assess its coherence, check for missing values and, in many cases, modify it to obtain a more meaningful representation of underlying phenomena. In other words, one would perform feature engineering. Below we present insights which we found interesting from a machine learning perspective.
Sparse information
The majority of the values in the training set were just zeros – around 66 percent! A sensible approach is to aggregate related sparse features to produce denser representations. An example could be to sum hourly counts of seismic events. By summing values in all 24 hours, the last 5 hours and in the very last hour, we would end up with 3 features instead of 24 – eight times less. We would not only reduce the size of the dataset – we would also have a greater chance that our models would see some interesting patterns more easily. At the same time, we would prevent the models from getting fooled by temporary artifacts – their impact will fade down after aggregation.
Multiple locations
An interesting difficulty – or rather a challenge – are the observations’ origins. The seismic records were collected at different coal mines with varying seismic activity. In some of them dangerous events were much more frequent than in others, ranging from 0 to 17% of observations. Ideally, we would produce a single specialized model for each working site. However, there is a high probability that these models would be useless when confronted with a new location. They would also be useless in this data mining challenge – the table below presents coal mines along with the number of available observations – notice that not all of them appear in both training and test sets and that the number of observations vary considerably between the sites. Thus, there was a need to build a location-agnostic model that would learn from general seismic activity phenomena.
Working site ID
Training observations
Test observations
Warnings frequency
373
31236
–
1.1%
264
20533
–
0.4%
725
14777
330
9.4%
777
13437
330
0.0%
437
11682
–
0.4%
541
6429
5
0.9%
146
5591
98
0.1%
575
4891
253
0.5%
765
4578
329
0.0%
149
4248
98
7.3%
155
3839
98
17.2%
583
3552
215
0.2%
479
2488
35
0.0%
793
2346
330
0.0%
607
2328
209
0.0%
599
1196
363
1.9%
799
–
317
–
470
–
258
–
490
–
160
–
703
–
145
–
641
–
97
–
689
–
83
–
508
–
58
–
171
–
49
–
Working site proxies
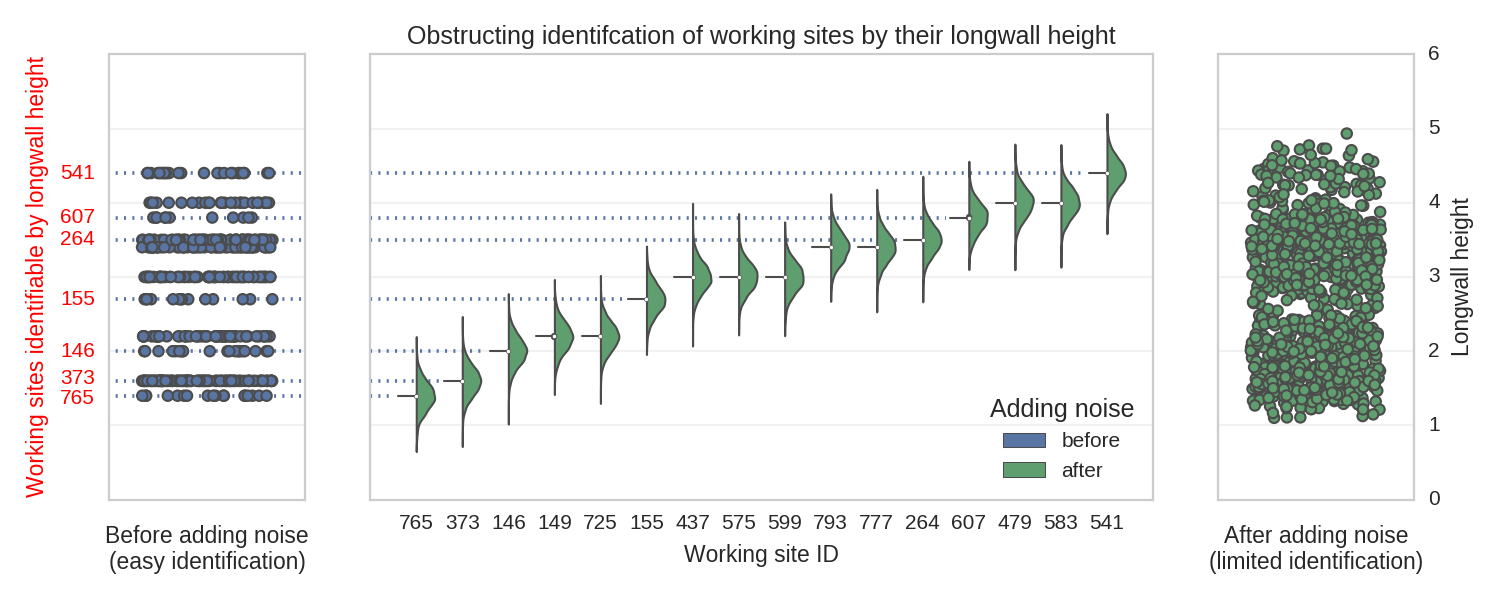
As mentioned above, our goal was to build a model which generalizes well and is able to infer predictions from a broad variety of clues (the features we extracted) without getting biased toward particular locations. Therefore, a necessary step is to exclude the mine IDs from the features set. We have to be careful though, as the information identifying a particular site can leak through other features, turning them into working site proxies. We have already mentioned them – these were the coal mines’ metadata and the majority of them were excluded straight away (various names specific only to particular locations). We only kept the main working height, as this information was valuable. However, as you can see in the figure below, some of the mines can be exactly identified by their main working height values. To obstruct the identification, we added some Gaussian noise:
After injecting some randomness, it is no longer possible to exactly identify location based on a longwall’s height. However, the essential information is still conveyed.
Features
The above insights allowed us to significantly reduce the number of features. We ended up with 133 features – 4 times less than the original set.
This was not the end of feature extraction. Often some valuable information is not stored directly in the features, but rather in the interactions between them (e.g. pairwise multiplications). We selected around 1,000 of the most promising interactions and treated them as additional features.
Validation
The condition – that the model has to generalize well – sets particular requirements on the validation procedure. It has to favor the models that make accurate predictions for the known working sites, as well as for previously unseen sites. One possible validation procedure which satisfies these conditions is to, for every train-test split, divide the working sites into three groups: first group will be used solely for training, second only for testing, in the third the observations will be split. For the sake of the results’ stability, we would generate many of these configurations (25 worked well in our case) and average the outcomes.
Model selection
Having settled on the features set and the validation procedure we focused on model selection. The process was quite complex, so let’s go through it step-by-step:
We decided to use tree-based classifiers as they work particularly well with unbalanced classes and possibly correlated features. Namely, we used ExtraTreesClassifier (ETC) from scikit-learn and XGBoost (XGB) classifier from xgboost;
We ran a preliminary grid search to find well-performing meta-parameters;
The models were used to select promising features subsets. We ran hundreds of evaluations, where in each run we made use of a random selection of features (between 20 and 40) and interactions (up to 10).
Model ensembling
The above procedure was meant to reveal relatively small feature subspaces. All of them were reasonably accurate. Moreover, they were also (to some extent) independent. The models based on them could see only a small part of the entire features space, therefore they were inferring their predictions based on diverse clues. And what can one do with a number of varied models? Let them vote! The final submission to the contest was a blend of predictions generated by multiple models (2 major ones which saw all features and 40 minor ones, which saw only subspaces).
Final results
The final submission reached 0.94 AUC and turned out to be the best in the competition, outperforming 200 other machine learning teams. This meant that deepsense.ai retained its top position in the AAIA Data Mining Challenges (you can read about our success last year here).
I would like to thank all the competition participants for a challenging environment, as well as the organizers from the University of Warsaw and the Institute of Innovative Technologies EMAG for preparing such an interesting and meaningful dataset. I would also like to thank my colleagues from the deepsense.ai Machine Learning Team: Robert Bogucki, Jan Kanty Milczek and Jan Lasek for the great time we had tackling the problem.
In 2013 the Deepmind team invented an algorithm called deep Q-learning. It learns to play Atari 2600 games using only the input from the screen. Following a call by OpenAI, we adapted this method to deal with a situation where the playing agent is given not the screen, but rather the RAM state of the Atari machine. Our work was accepted to the Computer Games Workshop accompanying the IJCAI 2016 conference. This post describes the original DQN method and the changes we made to it. You can re-create our experiments using a publicly available code.
Atari games
Atari 2600 is a game console released in the late 1970s. If you were a lucky teenager at that time, you would connect the console to the TV-set, insert a cartridge containing a ROM with a game and play using the joystick. Even though the graphics were not particularly magnificent, the Atari platform was popular and there are currently around \(400\) games available for it. This collection includes immortal hits such as Boxing, Breakout, Seaquest and Space Invaders.
agent (which sees states and rewards and decides on actions) and
environment (which sees actions, changes states and gives rewards).
R. Sutton and A. Barto: Reinforcement Learning: An Introduction
In our case, the environment is the Atari machine, the agent is the player and the states are either the game screens or the machine’s RAM states. The agent’s goal is to maximize the discounted sum of rewards during the game. In our context, “discounted” means that rewards received earlier carry more weight: the first reward has a weight of \(1\), the second some \(gamma\) (close to \(1\)), the third \(gamma^2\) and so on.
Q-values
Q-value (also called action-value) measures how attractive a given action is in a given state. Let’s assume that the agent’s strategy (the choice of the action in a given state) is fixed. Then a Q-value of a state-action pair \((s, a)\) is the cumulative discounted reward the agent will get if it is in a state \(s\), executes the action \(a\) and follows his strategy from there on.
The Q-value function has an interesting property – if a strategy is optimal, the following holds:
$$
Q(s_t, a_t) = r_t + gamma max_a Q(s_{t+1}, a)
$$
One can mathematically prove that the reverse is also true. Namely, any strategy which satisfies the property for all state-action pairs is optimal. This fact is not restricted to deterministic strategies. For stochastic strategies, you have to add some expectation value signs and all the results still hold.
Q-learning
The above concept of Q-value leads to an algorithm learning a strategy in a game. Let’s slowly update the estimates of the state-action pairs to the ones that locally satisfy the property and change the strategy, so that in each state it will choose an action with the highest sum of expected reward (estimated as an average reward received in a given state after following given action) and biggest Q-value of the subsequent state.
for all (s,a):
Q[s, a] = 0 #initialize q-values of all state-action pairs
for all s:
P[s] = random_action() #initialize strategy
# assume we know expected rewards for state-action pairs R[s, a] and
# after making action a in state s the environment moves to the state next_state(s, a)
# alpha : the learning rate - determines how quickly the algorithm learns;
# low values mean more conservative learning behaviors,
# typically close to 0, in our experiments 0.0002
# gamma : the discount factor - determines how we value immediate reward;
# higher gamma means more attention given to far-away goals
# between 0 and 1, typically close to 1, in our experiments 0.95
repeat until convergence:
1. for all s:
P[s] = argmax_a (R[s, a] + gamma * max_b(Q[next_state(s, a), b]))
2. for all (s, a):
Q[s, a] = alpha*(R[s, a] + gamma * max_b Q[next_state(s, a), b]) + (1 - alpha)Q[s, a]
This algorithm is called Q-learning. It converges in the limit to an optimal strategy. For simple games like Tic-Tac-Toe, this algorithm, without any further modifications, solves them completely not only in theory but also in practice.
Deep Q-learning
Q-learning is a correct algorithm, but not an efficient one. The number of states which need to be visited multiple times to learn their action-values is too big. We need some form of generalization: when we learn about the value of one state-action pair, we can also improve our knowledge about other similar state-actions.
The deep Q-learning algorithm uses the convolutional neural network as a function approximating the Q-value function. It accepts the screen (after some transformations) as an input. The algorithm transforms the input with a couple of layers of nonlinear functions. Then it returns an up to \(18\) dimensional vector. Entries of the vector denote the approximated Q-values of the current state and each of the possible actions. The action to choose is the one with the highest Q-value.
Training consists of playing the episodes of the game, observing transitions from state to state (doing the currently best actions) and rewards. Having all this information, we can estimate the error, which is the square of the difference between the left- and right-hand side of the Q-learning property above:
$$
error = (Q(s_t, a_t) – (r_t + gamma max_a Q(s_{t+1}, a)))^2
$$
We can calculate the gradient of this error according to the network parameters and update them to decrease the error using one of the many gradient descent optimization algorithms (we used RMSProp).
DQN+RAM
In our work, we adapted the deep Q-learning algorithm so that its input are not game screens, but the RAM states of the Atari machine. Atari 2600 has only \(128\) bytes of RAM. On one hand, this makes our task easier, as our input is much smaller than the full screen of the console. On the other hand, the information about the game may be hard to retrieve. We tried two network architectures. One with \(2\) hidden ReLU layers, \(128\) nodes each, and the other with \(4\) such layers. We obtained results comparable (in two games higher, in one lower) to those achieved with the screen input in the original DQN paper. Admittedly, higher scores can be achieved using more computational resources and some additional tricks.
Tricks
The method of learning Atari games, as presented above and even with neural networks employed to approximate the Q-values, would not yield good results. To make it work, the original DQN paper’s authors and we in our experiments, employed a few improvements to the basic algorithm. In this section, we discuss some of them.
Epsilon-greedy strategy
When we begin our agent’s training, it has little information about the value of particular game states. If we were to completely follow the learned strategy at the start of the training we’d be nearly randomly choosing some actions to follow in the first game states. As the training continues, we’d stick to these actions for the first states, as their value estimation would be positive (and for the other actions would be nearly zero). The value of the first-chosen action would improve and we’d only pick these, without even testing the other possibilities. The first decisions, made with little information, would be reinforced and followed in the future.
We say that such a policy doesn’t have a good exploration-exploitation tradeoff. On one hand, we’d like to focus on the actions that led to reasonable results in the past, but on the other ahnd, we prefer our policies to extensively explore the state-action space.
The solution to this problem used in DQN is using an epsilon-greedy strategy during training. This means that at any time with some small probability \(varepsilon\) the agent chooses a random action, instead of always choosing the action with the best Q-value in the given state. Then, every action will get some attention and its state-action value estimation will be based on some (possibly limited) experience and not the initialization values.
We join this method with epsilon decay — at the beginning of training we set \(varepsilon\) to a high value (\(1.0\)), meaning that we prefer to explore the various actions and gradually decrease \(varepsilon\) to a small value, that indicate the preference to exploit the well-learned action-values.
Experience replay
Another trick used in DQN is called experience replay. The process of training a neural network consist of training epochs; in each epoch we pass all the training data, in batches, as the network input and update the parameters based on the calculated gradients.
When training reinforcement learning models, we don’t have an explicit dataset. Instead, we experience some states, actions, and rewards. We pass them to the network, so that our statistical model can learn what to do in similar game states. As we want to pass a particular state/action/reward tuple multiple times to the network, we save them in memory when they are seen. To fit this data to the RAM of our GPU, we store at most \(100 000\) recently observed state/action/reward/next state tuples.
When the dataset is queried for a batch of training data, we don’t return consecutive states, but a set of random tuples. This reduces correlation between states processed in a given step of learning. As a result, this improves the statistical properties of the learning process.
For more details about experience replay you can see Section 3.5 of Lin’s thesis. As quite a few other tricks in reinforcement learning, this method was invented back in 1993 – significantly before the current deep learning boom.
Frameskip
Atari 2600 was designed to use an analog TV as the output device. The console generated \(60\) new frames appearing on the screen every second. To simplify the search space we imposed a rule that one action is repeated over a fixed number of frames. This fixed number is called the frame skip. The standard frame skip used in the original work on DQN is \(4\). For this frame skip the agent makes a decision about the next move every \( 4cdot frac{1}{60} = frac{1}{15}\) of a second. Once a decision is made, it remains unchanged during the next \(4\) frames. A low frame skip allows the network to learn strategies based on a super-human reflex. A high frame skip will limit the complexity of a strategy. Hence learning may be faster and more successful whenever strategy matters over tactic. In our work , we tested frame skips equal to \(4,8\) and \(30\).
https://deepsense.ai/wp-content/uploads/2019/02/Playing-Atari-games-using-RAM-state.jpg3371140Henryk Michalewskihttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngHenryk Michalewski2016-09-27 12:00:342023-02-28 21:57:21Playing Atari on RAM with Deep Q-learning
In January 2016, deepsense.ai won the Right Whale Recognition contest on Kaggle. The competition’s goal was to automate the right whale recognition process using a dataset of aerial photographs of individual whales. The terms and conditions for the competition stated that to collect the prize, the winning team had to provide source code and a description of how to recreate the winning solution. A fair request, but as it turned out, the winning solution’s authors spent about three weeks recreating all of the steps that led them to the winning machine learning model.
When data scientists work on a problem, they need to test many different approaches – various algorithms, neural network structures, numerous hyperparameter values that can be optimized etc. The process of validating one approach can be called an experiment. The inputs for every experiment include: source code, data sets, hyperparameter values and configuration files. The outputs of every experiment are: output model weights (definition of the model), metric values (used for comparing different experiments), generated data and execution logs. As we can see, that’s a lot of different artifacts for each experiment. It is crucial to save all of these artifacts to keep track of the project – comparing different models, determining which approaches were already tested, expanding research from some experiment from the past etc. Managing the process of experiment executions is a very hard task and it is easy to make a mistake and lose an important artifact.
To make the situation even more complicated, experiments can depend on each other. For example, we can have two different experiments training two different models and a third experiment that takes these two models and creates a hybrid to generate predictions. Recreating the best solution means finding the path from the original data set to the model that gives the best results.
Recreating the path that led to the best model
The deepsense.ai research team performed around 1000 experiments to find the competition-winning solution. Knowing all that, it becomes clear why recreating the solution was such a difficult and time consuming task.
The problem of recreating a machine learning solution is present not only in an academic environment. Businesses struggle with the same problem. The common scenario is that the research team works to find the best machine learning model to solve a business problem, but then the software engineering team has to put the model into a production environment. The software engineering team needs a detailed description of how to recreate the model.
Our research team needed a platform that would help them with these common problems. They defined the properties of such a platform as:
Every experiment and the related artifacts are registered in the system and accessible for browsing and comparing;
Experiment execution can be monitored via real-time metrics;
Experiment execution can be aborted at any time;
Data scientists should not be concerned with the infrastructure for the experiment execution.
deepsense.ai decided to build Neptune – a brand new machine learning platform that organizes data science processes. This platform relieves data scientists of the manual tasks related to managing their experiments. It helps with monitoring long-running experiments and supports team collaboration. All these features are accessible through the powerful Neptune Web UI and useful for scripting CLI.
Neptune is already used in all machine learning projects at deepsense.ai. Every week, our data scientists execute around 1000 experiments using this machine learning platform. Thanks to that, the machine learning team can focus on data science and stop worrying about process management.
Experiment Execution in Neptune
Main Concepts of the Machine Learning Platform
Job
A job is an experiment registered in Neptune. It can be registered for immediate execution or added to a queue. The job is the main concept in Neptune and contains a complete set of artifacts related with the experiment:
source code snapshot: Neptune creates a snapshot of the source code for every job. This allows a user to revert to any job from the past and get the exact version of the code that was executed;
parameters: customly defined by a user. Neptune supports boolean, numeric and string types of parameters;
data and logs generated by the job;
metric values represented as channels.
Neptune is library and framework agnostic. Users can leverage their favorite libraries and frameworks with Neptune. At deepsense.ai we currently execute Neptune jobs that use: TensorFlow, Theano, Caffe, Keras, Lasagne or scikit-learn.
Channel
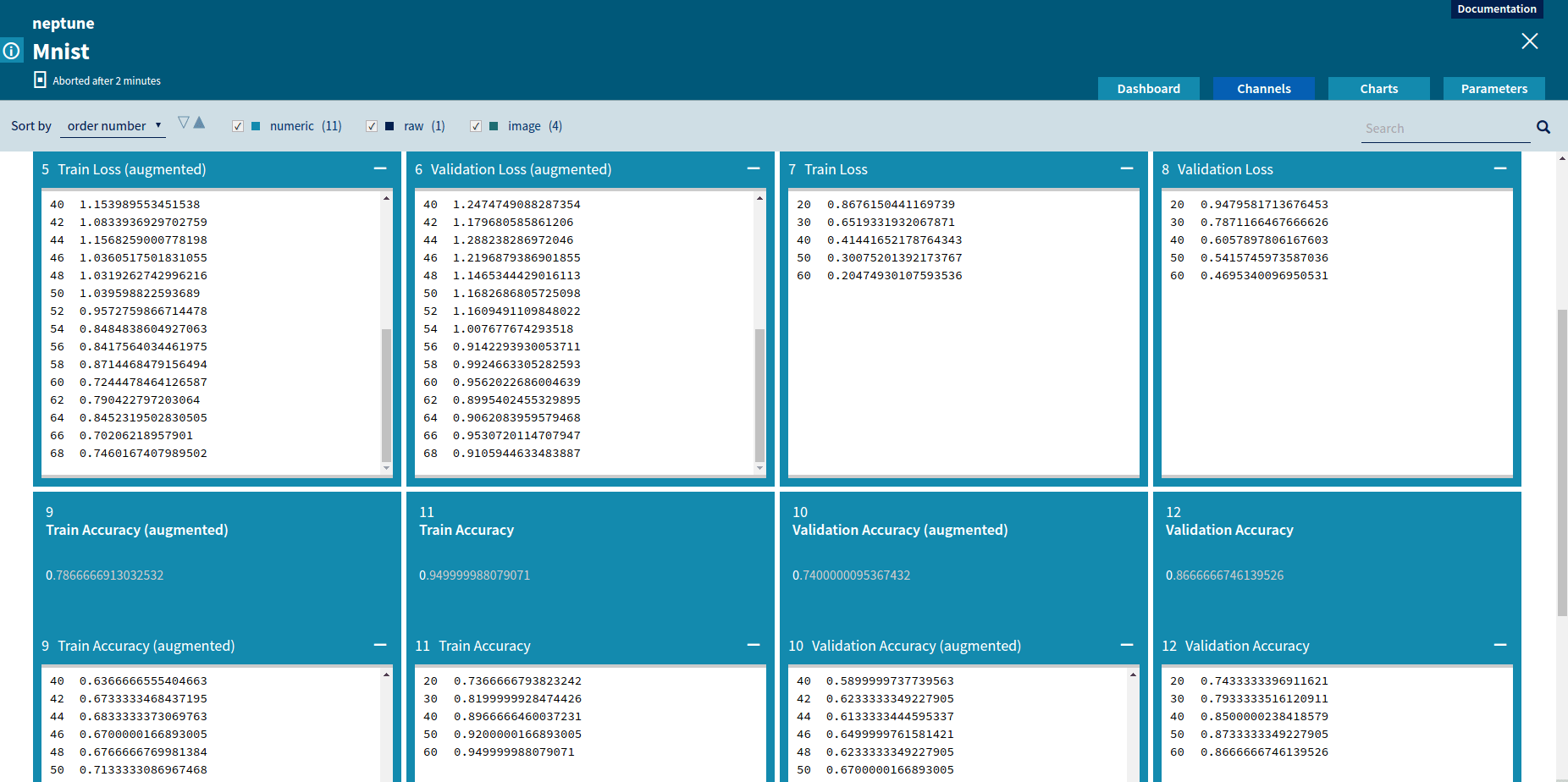
A channel is a mechanism for real-time job monitoring. In the source code, a user can create channels, send values through them and then monitor these values live using the Neptune Web UI. During job execution, a user can see how his or her experiment is performing. The Neptune machine learning platform supports three types of channels:
Numeric: used for monitoring any custom-defined metric. Numeric channels can be displayed as charts. Neptune supports dynamic chart creation from the Neptune Web UI with multiple channels displayed in one chart. This is particularly useful for comparing various metrics;
Text: used for logs;
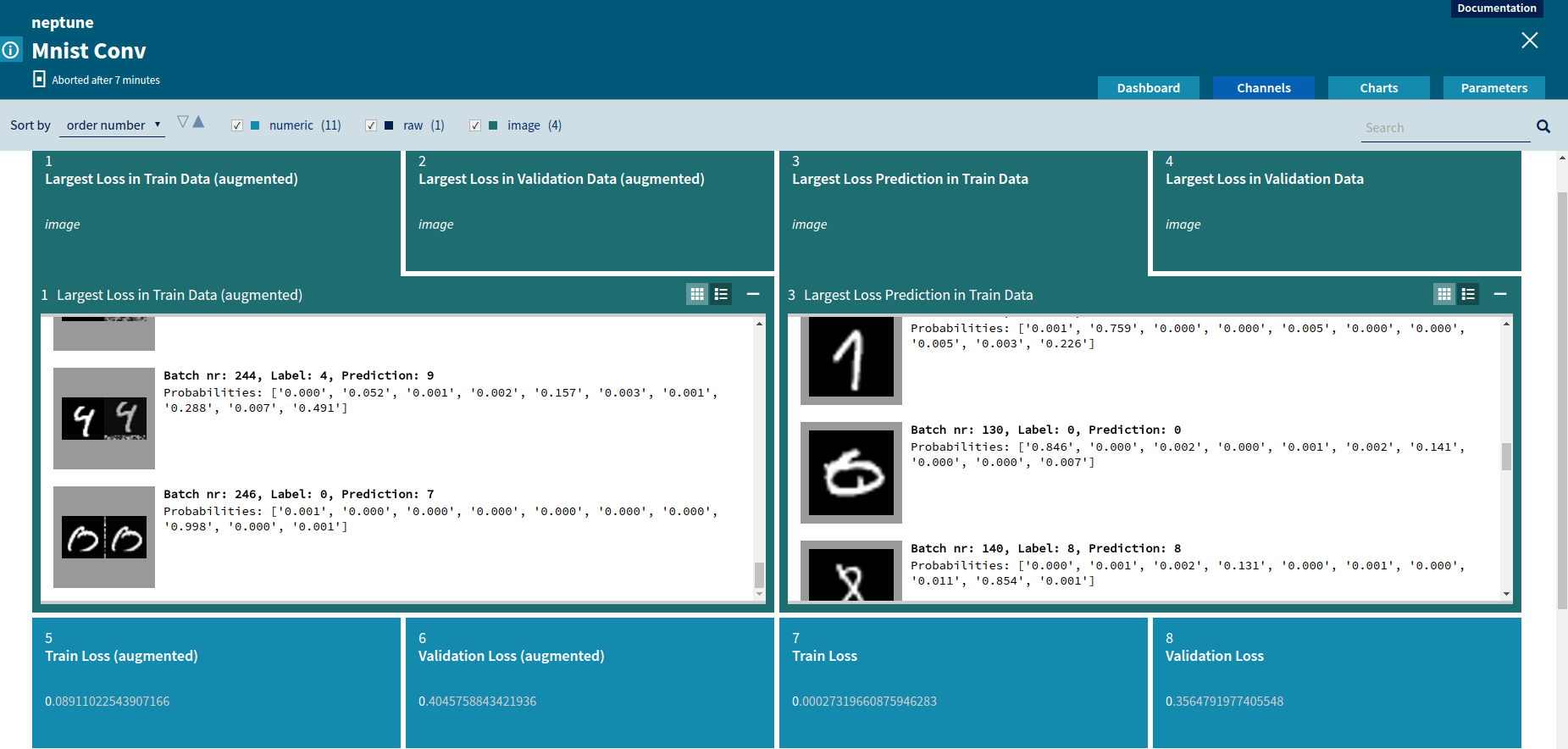
Image: used for sending images. A common use case for this type of channel is checking the behavior of an applied augmentation when working with images.
Comparing two Neptune image channels
Queue
A queue is a very simple mechanism that allows a user to execute his or her job on remote infrastructure. A common setup for many research teams is that data scientists develop their code on local machines (laptops), but due to hardware requirements (powerful GPU, large amount of RAM, etc) code has to be executed on a remote server or in a cloud. For every experiment, data scientists have to move source code between the two machines and then log into the remote server to execute the code and monitor logs. Thanks to our machine learning platform, a user can enqueue a job from a local machine (the job is created in Neptune, all metadata and parameters are saved, source code copied to users’ shared storage). Then, on a remote host that meets the job requirements the user can execute the job with a single command. Neptune takes care of copying the source code, setting parameters etc.
The queue mechanism can be used to write a simple script that queries Neptune for enqueued jobs and execute the first job from the queue. If we run this script on a remote server in an infinite loop, we don’t have to log to the server ever again because the script executes all the jobs from the queue and reports the results to the machine learning platform.
Creating a Job
Neptune is language and framework agnostic. A user can communicate with Neptune using REST API and Web Sockets from his or her source code written in any language. To make the communication easier, we provide a high-level client library for Python (other languages are going to be supported soon).
Let’s examine a simple job that provided with amplitude and sampling_rate generates sine and cosine as functions of time (in seconds).
import math
import time
from deepsense import neptune
ctx = neptune.Context()
amplitude = ctx.params.amplitude
sampling_rate = ctx.params.sampling_rate
sin_channel = ctx.job.create_channel(name='sin', channel_type=neptune.ChannelType.NUMERIC)
cos_channel = ctx.job.create_channel(name='cos', channel_type=neptune.ChannelType.NUMERIC)
logging_channel = ctx.job.create_channel(name='logging', channel_type=neptune.ChannelType.TEXT)
ctx.job.create_chart(name='sin & cos chart', series={'sin': sin_channel, 'cos': cos_channel})
ctx.job.finalize_preparation()
# The time interval between samples.
period = 1.0 / sampling_rate
# The initial timestamp, corresponding to x = 0 in the coordinate axis.
zero_x = time.time()
iteration = 0
while True:
iteration += 1
# Computes the values of sine and cosine.
now = time.time()
x = now - zero_x
sin_y = amplitude * math.sin(x)
cos_y = amplitude * math.cos(x)
# Sends the computed values to the defined numeric channels.
sin_channel.send(x=x, y=sin_y)
cos_channel.send(x=x, y=cos_y)
# Formats a logging entry.
logging_entry = "sin({x})={sin_y}; cos({x})={cos_y}".format(x=x, sin_y=sin_y, cos_y=cos_y)
# Sends a logging entry.
logging_channel.send(x=iteration, y=logging_entry)
time.sleep(period)
The first thing that we can see is that we need to import Neptune library and create a neptune.Context object. The Context object is an entrypoint for Neptune integration. Afterwards, using the context we obtain values for job parameters: amplitude and sampling_rate.
Then, using neptune.Context.job we create numeric channels for sending sine and cosine values and a text channel for sending logs. We want to display sin_channel and cos_channel on a chart, so we use neptune.Context.job.create_chart to define a chart with two series named sin and cos. After that, we need to tell Neptune that the preparation phase is over and we are starting the proper computation. That is what: ctx.job.finalize_preparation() does.
In an infinite loop we calculate sine and cosine functions values and send these values to Neptune using the channel.send method. We also create a human-readable log and send it through logging_channel.
To run main.py as a Neptune job we need to create a configurtion file – a descriptor file with basic metadata for the job.
config.yaml contains basic information about the job: name, project, owner and parameter definitions. For our simple Sine-Cosine Generator we need two parameters of double type: amplitude and sampling_rate (we already saw in the main.py how to obtain parameter values in the code).
To run the job we need to use the Neptune CLI command: neptune run main.py –config config.yaml –dump-dir-url my_dump_dir — –amplitude 5 –sampling_rate 2.5
For neptune run we specify: the script that we want to execute, the configuration for the job and a path to a directory where snapshot of the code will be copied to. We also pass values of the custom-defined parameters.
Job Monitoring
Every job executed in the machine learning platform can be monitored in the Neptune Web UI. A user can see all useful information related to the job:
metadata (name, description, project, owner);
job status (queued, running, failed, aborted, succeeded);
location of the job source code snapshot;
location of the job execution logs;
parameter schema and values.
Parameters for Sine-Cosine Generator
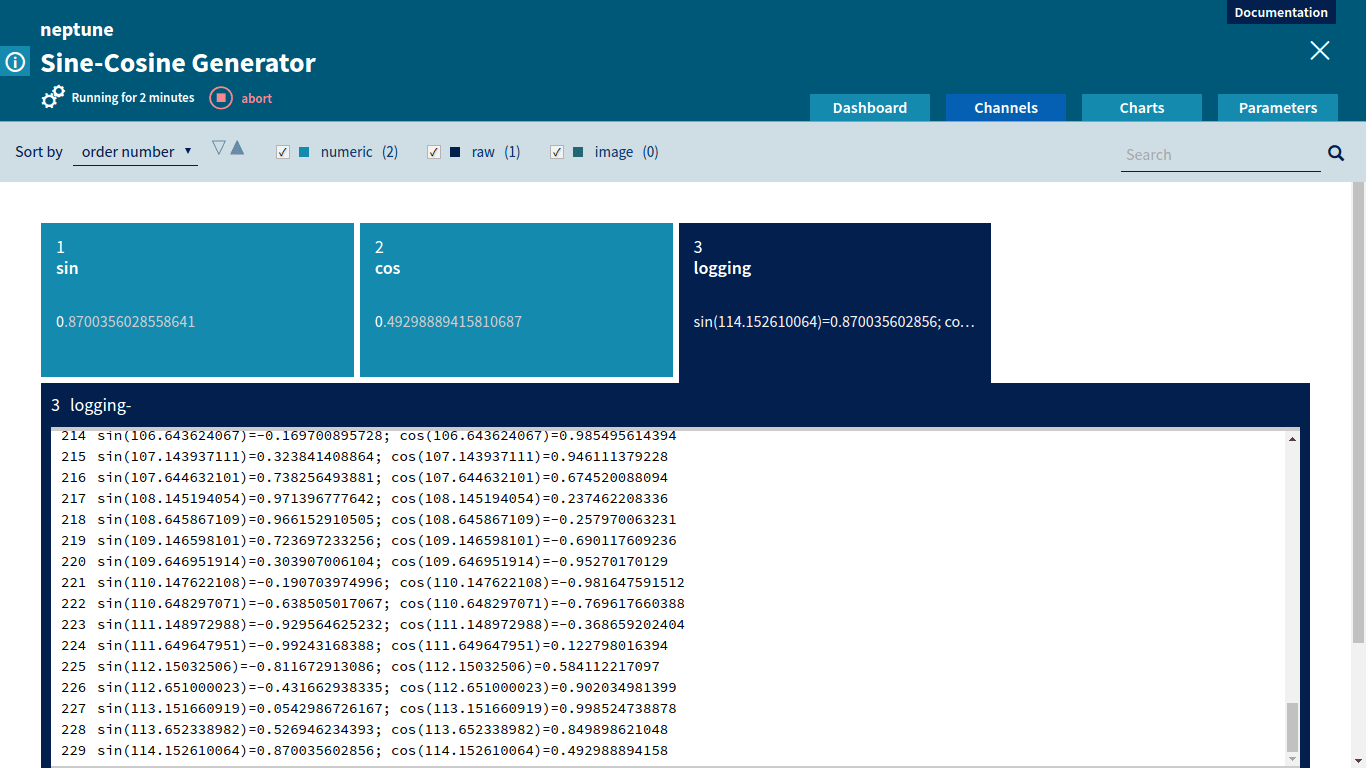
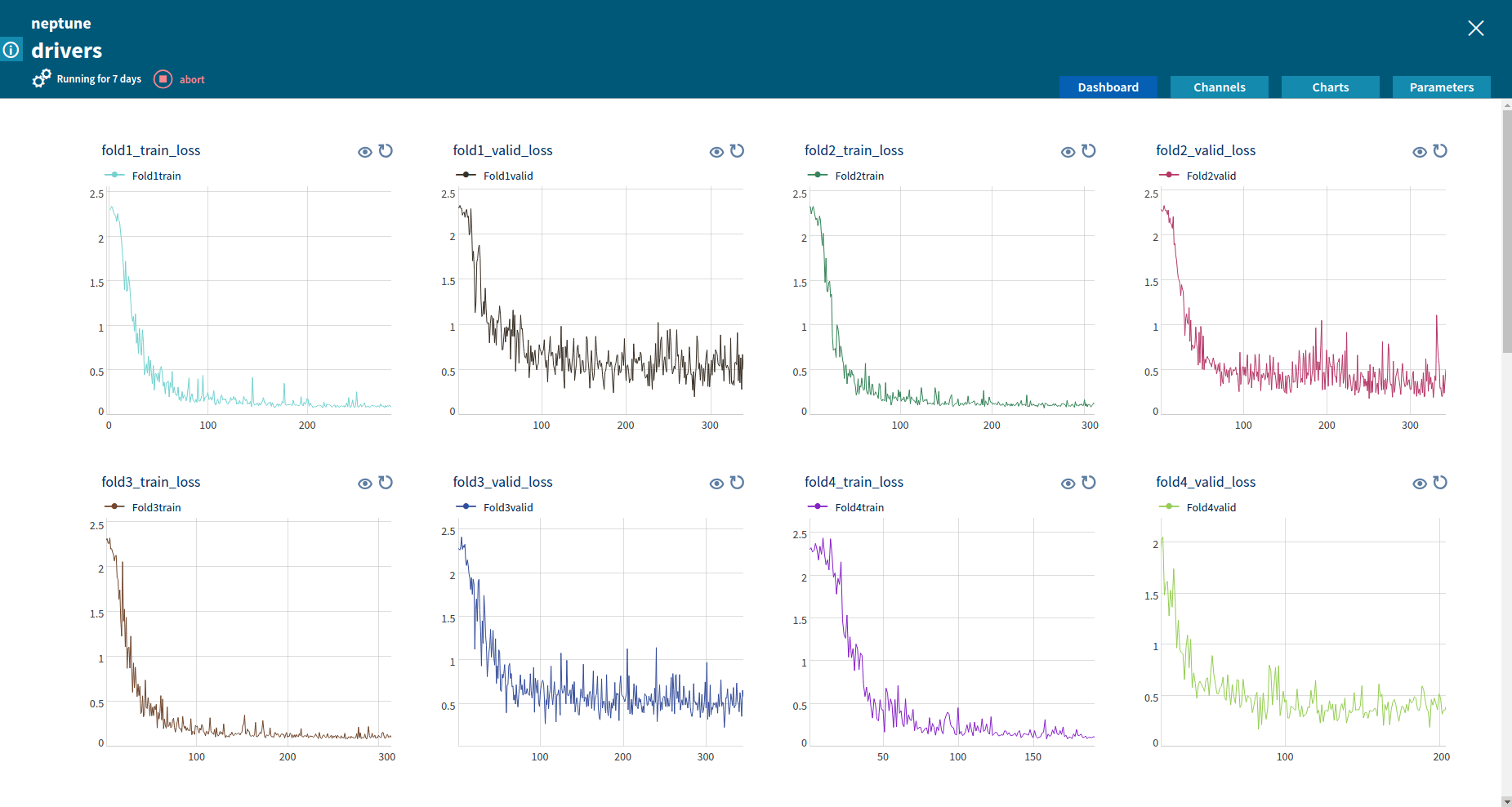
A data scientist can monitor custom metrics sent to Neptune through the channel mechanism. Values of the incoming channels are displayed in the Neptune Web UI in real time. If the metrics are not satisfactory, the user can decide to abort the job. Aborting the job can also be done from the Neptune Web UI.
Channels for Sine-Cosine GeneratorComparing values of multiple metrics using Neptune channels
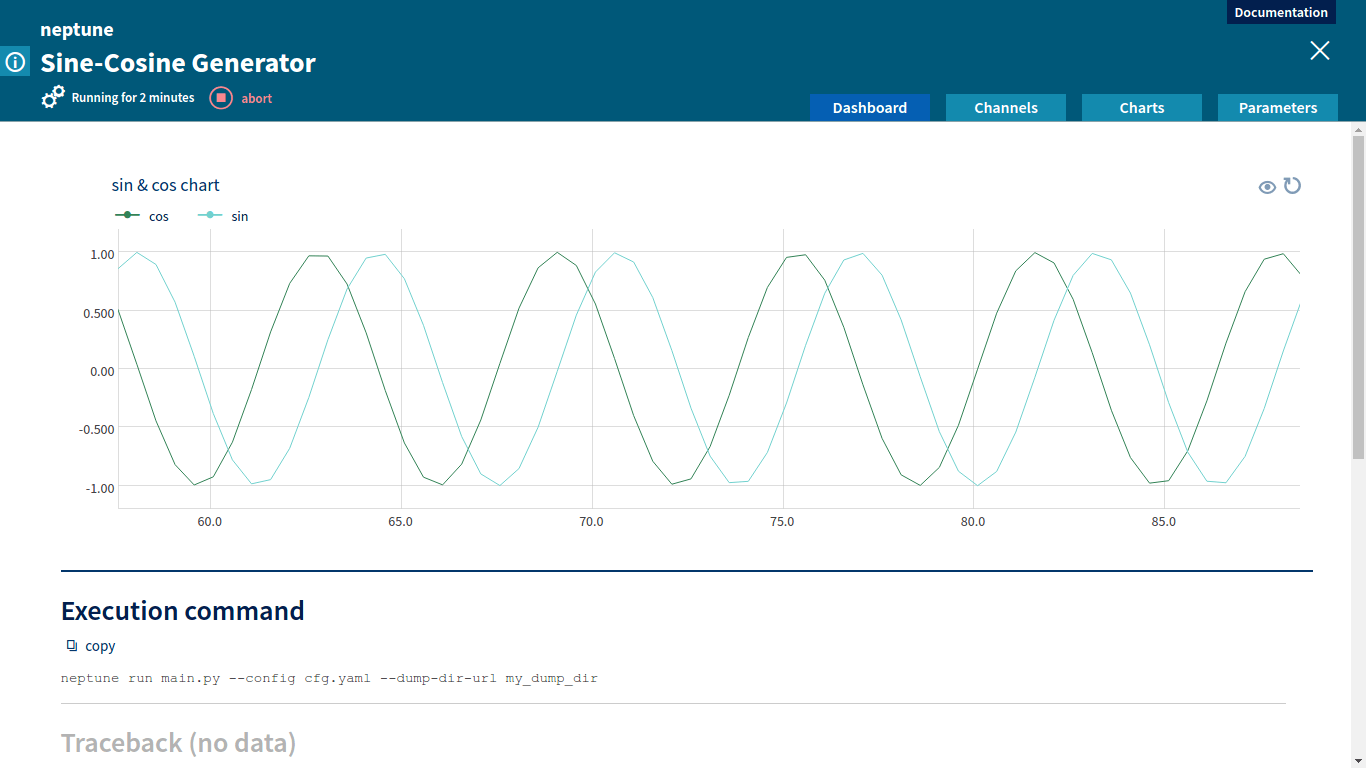
Numeric channels can be displayed graphically as charts. A chart representation is very useful to compare various metrics and to track changes of metrics during job execution.
Chart for Sine-Cosine GeneratorCharts displaying custom metrics
For every job a user can define a set of tags. Tags are useful for marking significant differences between jobs and milestones in the project (i.e if we are doing a MINST project, we can start our research by running the job with a well known and publicly available algorithm and tag it ‘benchmark’).
Comparing Results and Collaboration
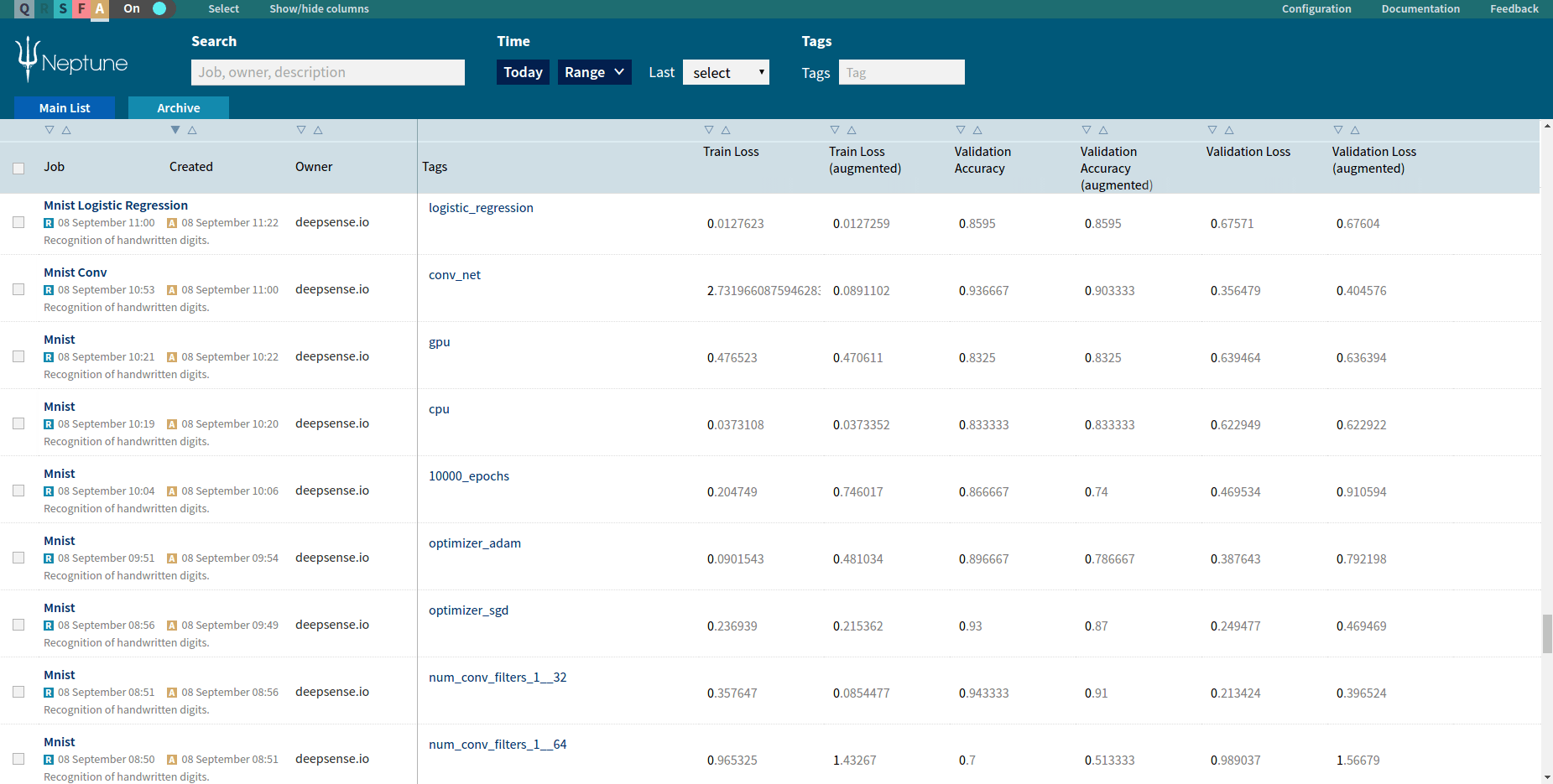
Every job executed in the Neptune machine learning platform is registered and available for browsing. Neptune’s main screen shows a list of all executed jobs. User can filter jobs using job metadata, execution time and tags.
Neptune jobs list
A user can select custom-defined metrics to show as columns on the list. The job list can be sorted using values from every column. That way, a user can select which metric he or she wants to use for comparison, sort all jobs using this metric and then find the job with the best score.
Thanks to a complete history of job executions, data scientists can compare their jobs with jobs executed by their teammates. They can compare results, metrics values, charts and even get access to the snapshot of code of a job they’re interested in.
Thanks to Neptune, the machine learning team at deepsense.ai was able to:
get rid off spreadsheets for keeping history of executed experiments and their metrics values;
eliminate sharing source code across the team as an email attachment or other innovative tricks;
limit communication required to keep track of project progress and achieved milestones;
unify visualisation for metrics and generated data.
The 2016 UEFA European Championship is about to kick-off in a few hours in France with 24 national teams looking to claim the title. In this post, we’ll explain how to utilize various football team rating systems in order to make Euro 2016 predictions.
Rating systems for football teams
Have you ever wondered how to predict the outcome of a football match? One of the basic techniques for doing so is to use a rating system. Usually, a rating system assigns each team a single parameter – its rating – based on its performance in previous games. These ratings can then be used to generate predictions for future matches. There are many rating systems to choose from. In this post, we will review several methods used for rating football a.k.a. soccer teams (of course, these methods can also be applied to other sports). Next, we will use these rating systems to generate our Euro 2016 predictions.
Elo rating system
However, before getting started with football, we’ll have to briefly discuss… chess. In the previous century, Arpad Elo, a Hungarian-American physicist, proposed a rating system to assess chess players’ performance. Since its development, the system has been widely adapted for other sports and online gaming. It also serves as the foundation for other rating systems, such as: Glicko or TrueSkill. The Elo model’s appealing formulation, elegance and, most importantly, accuracy, contributed to its popularity.
Let’s briefly introduce the Elo model. The general idea is that the Elo model updates its ratings based on what result it expects prior to the game and its actual outcome. There are two steps in compiling team ratings. First of all, given two team ratings ri and rj, one can derive the expected outcome of their match by using the so-called sigmoid function applied to the difference in their ratings. This function takes values from 0 to 1 and has a direct interpretation as a probability estimate. The exact formula is
where a is a scaling factor and h is an extra points parameter for the home team, which has a slight advantage over the visiting team (in chess, a parallel advantage is given to the ‘White’ player who always makes the first move). Given the predicted outcome pij and actual outcome oij equal to 1 in case of team i‘s win, 0.5 in case of a tie and 0 for team j’s win, the ratings are updated as follows:
and accordingly for the second team:
Here, k is the so-called K-factor, which governs the magnitude of rating changes. Note that in its original formulation the Elo system only predicts binary outcomes with 0.5 being interpreted as a draw. To generate the probability of a tie we used a simple method suggested here.
As far as football is concerned, Elo ratings’ implementation is maintained at EloRatings.net website. Moreover, the system is also the basis of the FIFA Women’s World Ranking. Notably, these systems have been documented to work better than FIFA’s Men’s Ranking when considering the ranking systems’ predictive capabilities. We will employ both versions of the Elo model in their original formulation to generate the predictions below.
Another way of estimating team ratings is to use an ordinal regression model. This model is an extension of the basic logistic regression model to ordered outcomes – in this case win, draw and loss. Somewhat analogous to the Elo system, the probabilities of the occurrence of these events, given the two teams’ ratings ri and rj are determined as:
where c > 0 is a parameter governing draw margin and h is used to adjust for home team advantage. Here, unlike in the original Elo model, the probability of a draw is modeled explicitly (in case c = 0 we arrive at the Elo’s expected outcome equation provided previously). Using these equations and the method of maximum likelihood, one can estimate team ratings ri, c and the home team advantage parameters.
Least squares method
The next rating system is based on a simple observation that the difference si – sj in the scores produced by the teams should correspond to the difference in ratings:
Again, h is a correction for the home team i advantage. The rating system’s name originates from its estimation method: one finds ratings ri such that the sum of squared differences (over a set of games) between the two sides of the above equation is minimal. Kenneth Massey’s website, among others, compiles and maintains a version of the rating system for various sports.
For the least squares model, we still need to generate probabilities for particular outcomes. Once again, we do this by using the sigmoid function analogously to the Elo model.
Poisson model
The final rating system that we’ll discuss is based on the assumption that the goals scored by a team can be modeled as a Poisson distributed variable. This distribution is applicable in situations in which we deal with count data, e.g., the number of accidents, telephone calls or… goals scored :) the mean rate of this variable is dependent on the attacking capabilities of a team and the defensive skills of its opponent. This extends ratings to two parameters – offensive and defensive skills per team as opposed to a single parameter in the methods discussed above.
Given the attacking and defensive skills of teams i and j, ai, aj and di, dj, respectively, the rates of Poisson variables for a home team i and visiting team j, λ and μ respectively, are modeled as:
Under this model, the probability of a score x to y is equal to:
Given a dataset of matches, one can estimate the team rating parameters using the maximum likelihood method. Here, we employ the basic version of the model that assumes that the Poisson variables modeling the goals scored by the teams, given their rating parameters, are independent.
We used the rating systems presented here to estimate win, draw and loss probabilities for every pair of possible matchups among the 24 teams participating in Euro 2016. Given these probabilities, we simulated the tournament multiple times and computed each team’s probability of winning it all. We used the database of international football match results provided at this website (thanks to Christian Muck for generously exporting the data).
First of all, the rating systems involve some adjustable parameters e.g., weights for importance of matches (friendly vs. World Cup final), a weighing function for most recent results and regularization (to avoid overfitting of rating models to historical results). We then tuned these parameters to maximize the predictive accuracy of the models: using a sample of games, we predicted their results and evaluated them. For tuning the parameters, we chose matches from major international tournaments – World Cup finals, European Championships and Copa America (South American continental championships).
The parameters of ratings systems are chosen for World Cup finals held between 1994 and 2010 (5 tournaments), UEFA European Championships 1996 – 2008 (4) and Copa America finals 1999 – 2011 (5). This accounts for a set of 562 matches. The prediction accuracy is evaluated using logarithmic loss (so-called logloss). It is an error metric that is often used to evaluate probabilistic predictions. Perhaps a more direct interpretation is provided by accuracy – this is just the percentage of matches that were correctly predicted by a given method. The table below presents logloss for probabilities of match outcome as well as accuracy of predictions for each method.
Method
Logloss
Accuracy
EloRatings.net
0.9818
52%
FIFA Women World Rankings
0.9934
52%
Ordinal Logistic Regression
0.9638
53%
Least Squares
0.9553
55%
Poisson Ratings
0.9646
55%
The estimates below might be overly optimistic since they were chosen so as to minimize the prediction error on this specific set of games. To validate the methods more thoroughly, we used 121 other matches from the three most recent tournaments – the 2014 World Cup finals, the 2012 European championships and 2015 Copa America finals. The results are presented below. To provide some context for the numbers, we present a benchmark solution of random guessing and probabilities derived from an average of bookmakers’ odds. A random guess yields a logarithmic loss of -log(1/3) ≈ 1.1 and accuracy of 33% for a three-way outcome.
Method
Logloss
Accuracy
EloRatings.net
1.0074
55%
FIFA Women World Rankings
1.0032
54%
Ordinal Logistic Regression
0.9972
50%
Least Squares
0.9949
56%
Poisson Ratings
0.9981
55%
Random guess
1.0986
33%
Bookmakers
0.9726
52%
Ensemble
0.9919
55%
The results achieved by bookmakers (in terms of logloss) are better than all the individual rating methods. Of course, the bookmakers can include some additional information on player injuries, suspensions or a team’s form during the contest – this provides them with an advantage over the models. Including such external information would be the next step to enhancing the accuracy of the presented models. In any case, the accuracy of predictions is slightly better in case of the rating systems. The bottom row of the table presents results for an ensemble method – which is the average of predictions for the three best performing methods: least squares, Poisson and ordinal regression ratings. It is a simple method for increasing the predictive power of individual models. We observe that this method slightly improves logloss while maintaining accuracy.
The rating methods presented here have some limitations. There are many factors influencing match results and we only covered simple predictive models based on historical data. Naturally, one could use some external and more sophisticated information e.g., players and their skills, and include it in a model. We encourage you to think about other factors playing a role in match outcomes which could be included in a model. This could greatly improve the models’ accuracy!
Given match outcome probabilities for each possible matchup, we simulated 1,000,000 Euro 2016 tournaments. We sampled only win, draw and loss results. If – after considering head-to-head results – the teams are still tied in the group stage, we resolved such ties randomly. According to the tournament’s official rules, we should use goal differences, however, this information is not available in our simulation. Notably, coin-tosses (random outcome) were used to resolve ties (if the game was tied after extra-time) before the penalty shoot-out was “invented.” For instance, on its way to winning Euro 1968, Italy “won” its semifinal with the USSR through a coin toss. Although we do not support this manner of deciding the outcomes of sporting events, we employ drawing lots if teams are tied at the end of the tournament’s group stage. If there is a draw in the playoffs, we sample the result again.
And… here are the predictions generated using the ensemble of the three best-performing ratings systems! The consecutive columns indicate the probability of advancing to a given stage of the competition. For example, the number next to Portugal in the first column indicates that there is a 91.37% chance that it will advance past the group stage. On the other hand, in the case of Spain, there is a 33.95% chance that it will reach the Euro 2016 final. The last column indicates a team’s chance of winning the whole tournament.
Team
Last 16
Quarterfinals
Semifinals
Final
Champions
France
98.01%
82.6%
67.71%
51.21%
37.55%
Spain
92.6%
72.24%
51.11%
33.95%
19.08%
Germany
94.71%
70.41%
45.99%
24.88%
13.21%
England
93.52%
67.5%
40.87%
22.25%
10.4%
Belgium
84.38%
48.2%
26.1%
11.51%
4.55%
Portugal
91.37%
54.7%
26.31%
12.09%
4.42%
Italy
72.43%
33.38%
14.83%
5.26%
1.55%
Ukraine
76.81%
37.05%
15.5%
5.53%
1.52%
Croatia
66%
31.92%
14.65%
5.27%
1.5%
Russia
75.34%
37.84%
13.07%
4.29%
1.14%
Turkey
61.9%
27.97%
12.07%
4%
1.05%
Switzerland
69.98%
30.49%
11.8%
3.97%
0.88%
Poland
67.4%
26.58%
9.35%
2.77%
0.6%
Sweden
57.89%
20.76%
7.45%
2.11%
0.47%
Romania
62.64%
23.82%
8.07%
2.35%
0.45%
Austria
71.63%
27.01%
7.46%
2.07%
0.43%
Slovakia
63.66%
25.57%
6.96%
1.79%
0.37%
Republic of Ireland
54.68%
18.64%
6.38%
1.72%
0.35%
Czech Republic
46.28%
16.19%
5.6%
1.44%
0.29%
Hungary
56.86%
16.08%
3.37%
0.69%
0.11%
Iceland
47.81%
11.32%
2.02%
0.36%
0.05%
Albania
31.46%
6.62%
1.26%
0.19%
0.02%
Wales
34.29%
7.98%
1.19%
0.16%
0.02%
Northern Ireland
28.32%
5.11%
0.88%
0.13%
0.01%
Some of you might find these predictions surprising – and our discussion thread is now open! As far as our thoughts are concerned, first of all, we see that France tops the ranking. The 12th man is behind them – they are playing at home and the methods we used give them some edge due to this fact. On the other hand, the prediction for four-time World Cup winners Italy is somewhat discouraging. In recent years, Italy has seen disappointing results, including draws with Armenia, Haiti and Luxembourg (not to mention their 2010 and 2014 World Cup records). However, what the rating system could not infer is the fact that the Italian team usually rises to the occasion when faced with a major challenge – which usually happens at the big tournaments. Russia’s perhaps surprisingly high position in the ranking might be partially attributed to the easier (according to the rating systems that we used) group stage opponents they will face: Wales, Slovakia and England.
All in all, no team is condemned to lose before the start of the tournament and that is the very beauty of sports. We might well end up with a surprising result, such as Greece’s Euro 2004 triumph… so, which team will upset the favorites this year?
https://deepsense.ai/wp-content/uploads/2019/02/euro-2016-predictions.jpg217750Jan Lasekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngJan Lasek2016-06-10 10:03:022023-02-05 20:23:28Euro 2016 Predictions Using Team Rating Systems
This year’s annual Kaggle’s optimization competition, sponsored once again by FICO, was “Santa’s Stolen Sleigh” which featured a variant of a vehicle routing problem. Our team master.exploder@deepsense.io claimed 3rd place overall, as well as the Xpress Prize, awarded for best use of the FICO Xpress Optimization Suite.
The goal of the challenge was to organize Santa’s gift-delivery schedule in a way that minimizes the reindeer’s total workload.
All the gifts are stored in a warehouse at the North Pole, where Santa loads them onto his sleigh. He has to take into account that each gift weighs a certain amount, and the sleigh cannot carry more than 1,000 kg at a time. Santa then delivers the batch of gifts and comes back for the next one. Given that the total weight of all gifts was about 1.4*106 kg, Santa has to make at least 1,400 trips to deliver all the gifts.
While it is very natural to ask for a set of trips with the shortest total distance traveled, Santa has a much more important goal in mind – to minimize the reindeer’s workload. This is defined as the integral of weight carried over the distance traveled. In simple terms, for every meter traveled with x kg of sleigh weight, the weariness increases by x [kg*m]. Note that sleigh itself weighs 10 kg, which is rather small compared to the 1,000 kg of maximum load, but does affect the problem quite significantly.
The data
The problem described above is NP-hard. This means that depending on the actual instance to be solved, very different approaches should be used. For small or highly structured sets of data, one might hope for a fast exact solution. On the other hand, for generic and large sets of data, the best one can hope for is a good, but suboptimal solution.
The challenge data consisted of 100,000 gifts with more or less random weights and destinations selected randomly all over the world. For data that large, it is likely not possible to find an optimal solution within reasonable time. However, given the problem’s similarity to the much studied Travelling Salesman Problem, one can hope for some very good heuristics.
The basic approach
It is generally agreed, that the best methods for approaching an Kaggle’s optimization competition like this are based on local search. The idea is to start with an easy to obtain solution (e.g. a random or greedy one) and then keep performing improvements. The way this is usually implemented is as follows: For every solution (also called a state), we define a set of close solutions, also called its neighbors. We then either scan all neighbors looking for one that is better than the current state, or perhaps sample this set. The word local might suggest that the differences between neighboring solutions are restricted spatially, but that is often not the case. Instead, the word local points at the locality structure of the state space induced by the neighborhoods.
The most naive implementation of local search would be to exhaustively scan the whole neighborhood of the current solution at each step and then proceed with either the first or the best-improving move found. Rather aptly, this approach is usually called hill climbing, and it has a rather glaring weakness. Just as always going uphill does not necessarily lead to reaching the highest peak, hill climbing has a tendency to get stuck in so-called local optima. These are solutions that, while not optimal, are still better than all of their neighbors.
One could devote thousands of pages to describing the different approaches to handling the problem of local optima in local search algorithms (to name a few: simulated annealing, threshold acceptance, tabu search, etc.). An obvious solution would be to simply increase the size of the neighborhoods, i.e. look further away. While this sometimes works surprisingly well (e.g. state of the art TSP solvers based on Lin-Kernighan heuristic do exactly that), it does not improve things substantially in general. A more subtle idea is to sometimes move to a state that is worse than the current. The most popular approach based on this idea is simulated annealing.
In simulated annealing (SA), one maintains an additional parameter T, called the temperature. This parameter is initially set to a large value and gradually decreased. SA randomly chooses a neighbor of the current state. If it improves upon the current state, it is always accepted, otherwise SA proceeds in a probabilistic fashion. When T is large, the move is still quite likely to be accepted. On the other hand, when T is very small, SA essentially reverts back to hill climbing. The way this behaviour is achieved is by accepting a worsening move with probability exp((old_objective-new_objective)/T).
As an example, consider a move that increases the objective function by 1. For T=100, this move would be accepted with probability exp(-1/100), which is around 99/100. On the other hand, for T=1/100, this move would be accepted with probability exp(-100), i.e. almost never.
From our experience, simulated annealing is the most effective approach to handling problems like this one, and that is the approach we decided to go with.
Choosing the right moves
Deciding on the shape of the neighborhoods, i.e. what kind of moves are allowed for a given state, is very often the key design decision in implementing SA. We kept making small adjustments to our list of moves until the very end of the competition, and here is what we arrived at:
swap positions of two gifts in the same route,
move a gift to an arbitrary position within the same route,
move a gift to an arbitrary position in another route,
swap positions of two gifts from two different routes,
double shift: move one gift from route r1 to route r2 and another gift from route r2 to route r1,
swap suffixes of two routes,
three-way suffix swap: given three routes r1, r2, r3 split each of them into two parts ri=prefisufi, where prefi is a prefix of ri and sufi is a suffix of ri, then create new routes r’1=pref1suf2, r’2=pref2suf3, r’3=pref3suf1.
It is worth noting that all of the moves on this list are non-greedy ones. We do not use moves like “Remove an item from one route and place it optimally in another route”. There are pros and cons to such moves. On one hand, they lead to much faster convergence towards good solutions, they also naturally prevent divergence in higher temperatures. On the other hand, by using such moves one risks getting stuck at local optima too quickly – despite using SA. This is always a delicate balance, and it is very hard to reason out in a rigorous fashion. In this particular case, more greedy moves might have actually been better. As it turned out, the top two teams used them, and it seems to be the biggest difference between our solution and theirs.
Where to begin?
Usually, one initializes SA with a random solution. However, in our case, this does not seem very appealing. The state space is huge, and it has thousands of parameters. To get from a random solution to a good one would require a very large number of local moves. There is also another reason for not using a random initial solution. It is quite easy to notice that in a good solution, Santa’s trips will be more or less vertical. This property can be exploited algorithmically (details in a later section), but only if it holds for most trips.
For the reasons given above we decided to use a non-random initialization. We first split the gifts into two categories: ones on the South Pole, and the remaining ones. Then, we processed each category separately. The main reason for doing this is that “everything is close on the South Pole”, so the verticality property holds to a much smaller extent there.
For each of the two categories we formed vertical stripes of gifts of varying width (wider at the South Pole), use SA to find good solutions for each stripe, and then glue the solutions together using dynamic programming. The SA we use here is a very crude and quick one, which is fine since the number of gifts in each stripe is relatively small.
How to make it fast?
One problem with performing local search on a massive state space, like the one we are dealing with, is that it requires a huge number of iterations to converge on a really good solution. There are several ways to achieve that goal, and we used all of them:
Use an efficient implementation: We used a very efficient implementation in C++. We observed that even at high temperature, almost all moves are rejected (this is in part because our moves are not greedy). We used this observation in our implementation: actually performing a move is rather slow, but evaluating it works lightning fast.
Use better hardware: We had access to one of the deepsense.ai machine learning team’s multi-core Xeon machines. Making SA multi-threaded is actually a rather non-trivial task. In the end, we decided to go with the following approach: once a second, we semi-randomly split the trips into buckets (this relies on verticality of the trips since we try to assign to each bucket a set of trips that are close to each other horizontally) and each thread only optimizes a single bucket, and thus avoids conflicts with other threads.
Run your program for a very long time: We did. Our longest single SA runs would take as long as two days straight.
Cooling schedule
One issue we ignored so far is choosing the cooling schedule, i.e. deciding how the temperature changes over time. The most commonly used schedule is the exponential one, in which after each iteration we multiply T by some constant 0<c<1. The larger c is, the longer the whole process takes, and most of the time this is the only consideration.
The target value of T is usually chosen so that SA in the target temperature essentially reduces to hill climbing. Choosing the initial value of T is a whole different story. In general, the higher this value, the better. Of course, a higher value also means a longer running time. However, in our case, if we set it too high, the solution starts to diverge from the initial one and has trouble converging back within reasonable time. Because of this, we needed to empirically choose the value that was as high as possible without causing any divergence problems.
Using MIP
One problem with local search algorithms, as opposed to exact algorithms, is that it is not clear at what point they are strong enough to produce good quality solutions. When solving very large TSP instances, Mixed Integer Program (MIP) solvers were used to this end (see e.g. http://www.math.uwaterloo.ca/tsp/index.html). We attempted to use MIPs in a similar fashion. The basic idea was to model gift transportation as a flow problem, in which:
all gifts are sinks,
the North Pole is the only source,
each node is limited to a single outgoing edge (this works for modelling a single trip, to model k trips, we allow at most k outgoing edges at the North Pole).
We also added many extra constraints to the integer program to make it easier to solve. This method worked really well for single trips and allowed us to prove that our SA optimizes them perfectly. For two trips or more, however, the resulting MIP proved too difficult for the solver. Our findings in this area netted us the Xpress prize.
Last week we have downloaded and loaded into R data from fitness tracker (motion coprocessor in iphone). Then with just few lines of R code we decomposed the data into a seasonal weekly component and the trend. Today we are going to see how to plot the number of steps per hour for different days of week. And then same data will be used to check how often there was any activity at given time.
To plot the activity we need to do some aggregation. Here we will count number of steps per hour per day of a week.
dataDF <- xml_dataSelDF %>%
group_by(wday, hour) %>%
summarise(sum = sum(value))
head(dataDF)
# Source: local data frame [6 x 3]
# Groups: wday [1]
#
# wday hour sum
# (fctr) (fctr) (dbl)
# 1 Sun 00 2013
# 2 Sun 01 2475
# 3 Sun 02 347
# 4 Sun 03 919
# 5 Sun 04 2158
# 6 Sun 05 4062
Great. How to present this data? Of course with ggplot2!
Here the geom_bar geometry will be used to present number of steps per hour for different days of week.
As we see the largest activity is around 4pm (time to collect kids from schools).
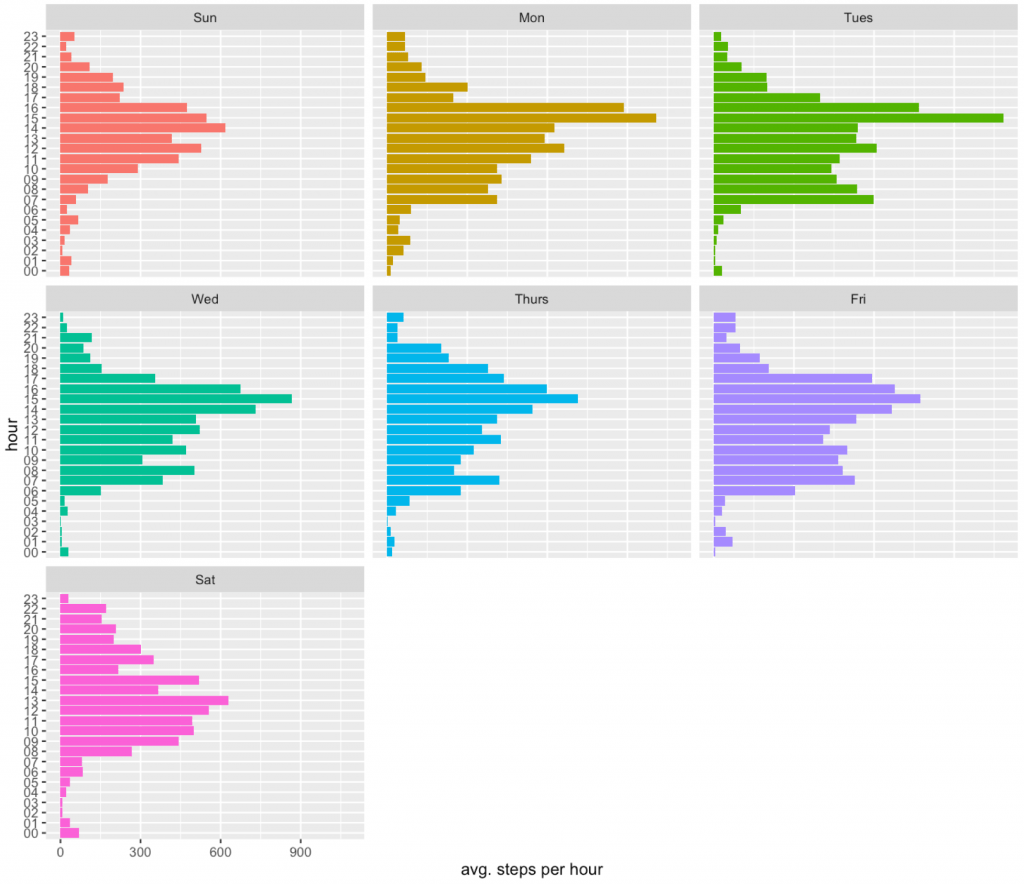
We can use such data to try other things.
Like for example, one can check if there was any activity during this hour. It will not be 100% accurate, since not always phone is in the pocket.
Then we will compute the fraction of days in which there was any activity during this hour.
Let’s see these patterns.
dataDF <- xml_dataSelDF %>%
group_by(day, wday, hour) %>%
summarise(sum = sum(value)>0 + 0) %>%
spread(hour, sum, fill=0) %>%
gather(hour, value, -day, -wday) %>%
group_by(wday, hour) %>%
summarise(mv = mean(value))
head(dataDF)
# Source: local data frame [6 x 3]
# Groups: wday [1]
#
# wday hour mv
# (fctr) (fctr) (dbl)
# 1 Sun 00 0.17021277
# 2 Sun 01 0.17021277
# 3 Sun 02 0.14893617
# 4 Sun 03 0.06382979
# 5 Sun 04 0.06382979
# 6 Sun 05 0.06382979
And the ggplot.
ggplot(dataDF, aes(x=hour, y=mv, fill=wday)) +
geom_bar(stat="identity") +
facet_wrap(~wday) +
coord_flip() + theme(legend.position="none") +
ylab("percent of days with any activity") + xlab("hour") +
scale_y_continuous(label=percent)
https://deepsense.ai/wp-content/uploads/2019/02/Exploration-of-data-from-iPhone-motion-coprocessor-2.jpg3371140Przemyslaw Biecekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPrzemyslaw Biecek2016-01-21 22:06:002021-01-05 16:51:47Exploration of data from iPhone motion coprocessor (2)
Right Whale Recognition was a computer vision competition organized by the NOAA Fisheries on the Kaggle.com data science platform. Our machine learning team at deepsense.ai has finished 1st! In this post we describe our solution.
The challenge
The goal of the competition was to recognize individual right whales in photographs taken during aerial surveys. When visualizing the scenario, do not forget that these giants grow up to more than 18 metres, and weigh up to 91 tons. There were 447 different right whales in the data set (and this is likely the overall number of living specimens). Even though that number is (terrifyingly) small for a species, uniquely identifying a whale poses a significant challenge for a person. Automating at least some parts of the process would be immensely beneficial to right whales’ chances of survival.
“Recognizing a whale in real-time would also give researchers on the water access to potentially life-saving historical health and entanglement records as they struggle to free a whale that has been accidentally caught up in fishing gear,”
— excerpt from competition’s description page.
The photographs had been taken at different times of day, and with various equipment. They ranged from very clear and centered on the animal to taken from afar and badly focused.
A non-random sample from the dataset
The teams were expected to build a model that recognizes which one of the 447 whales is captured in the photograph. More technically, for each photo, we were asked to provide a probability distribution over all 447 whales. The solutions were judged by multiclass log loss, also known as cross-entropy loss.
It is worth noting that the dataset was not balanced. The number of pictures per whale varied a lot: there were some “celebrities” having around forty, a great deal with over a dozen, and around twenty with just a single photo! Another challenge, is that images representing different classes (i.e. different whales) were very similar to each other. This is somewhat different than the situation where we try to discriminate between, say, dogs, cats, wombats and planes. This posed some difficulties for the neural networks that we had been training – the unique characteristics that make up an individual whale, or that set this particular whale apart from others, occupy only a small portion of an image and are not very apparent. Helping out our classifiers to focus on the correct features, i.e. the whale’s heads and their callosity patterns, turned out to be crucial.
Convolutional neural networks (CNNs) have proven to do extraordinarily well in image recognition tasks, so it was natural for us to base our solution on them. In fact, to our knowledge, all top contestants have used them almost at every step. Even though some say that those techniques require huge amounts of data (and we only had 4,544 training images available with some of the whales appearing only once in the whole training set), we were still able to produce a well-performing model, proving that CNNs are a powerful tool even on limited data.
In fact our solution consisted of multiple steps:
– head localizer (using CNNs),
– head aligner (using CNN),
– training several CNNs on passport-like photos of whales (obtained from previous steps),
– averaging and tuning the predictions (not using CNNs).
One additional trick that has served us well is providing the networks with some additional targets, even though those additional targets were not necessarily used afterwards or required in any way. If the additional targets depend on the part of image that is of particular interest for us (i.e. head and callosity pattern in this case), this trick should force the network to focus on this area. Also, the networks have more stimuli to learn on, and thus have to develop more robust features (sensible for more than one task) which should limit overfitting.
Software and hardware
We used Python, NumPy and Theano to implement our solution. To create manual annotations (and do not lose sanity during these long moments of questionable joy) we employed Sloth (a universal labeling tool), as well as an ad-hoc Julia script.
To train our models we used two types of Nvidia GPUs: Tesla K80 and GRID K520.
Domain knowledge
Even though it seems significantly harder for humans to identify whales than other people, neural networks do not suffer from such problem for obvious reasons. Even then, a bit of Wikipedia research on right whales reveals that “the most distinguishing feature of a right whale is the rough patches of skin on its head which appear white due to parasitism by whale lice.” Turns out that it not only distinguishes them from other species of whales, but also serves as an excellent way to differentiate between specimens. Our solution uses this fact to great lengths. Besides this somewhat trivial hint (provided by the organizers) about what to look at, we (sadly) posses no domain knowledge about right whales.
Preparing for the take-off
Before going further into the details, a disclaimer is needed. During a competition, one is (or should be) more tempted to test new approaches, than to fine tune and clean up existing ones. Hence, soon after an idea had proved to work well enough, we usually settled on it and left it “as is”. As a side-effect, we expect that some parts of the solution may possess unnecessary artifacts or complexity that could (and ought to) be eliminated. Nevertheless, we have not done so during the competition, and decided not to do so here either.
One does not need to see many images from the dataset in order to realize that whales do not pose very well (or at least were reluctant to do so in this particular case).
Not very cooperative whales
Therefore, before training final classifiers we spent some time (and energy) to account for this fact. The general idea of this approach can be thought of as obtaining a passport photo from a random picture where the subject is in some arbitrary position. This boiled down to training a head localizer and a head aligner. The first one takes a photo and produces a bounding box around the head, still the head may be arbitrarily rotated and not necessarily in the middle of the photo. The second one takes a photo of the head and aligns and rescales it, so that the blowhead and bonnet-tip are always in the same place, and the distance between them is constant. Both of these steps were done by training a neural network on manual annotations for the training data.
Bonnet-tip (red) and blowhead (blue)
Localizing the whale
This was the first step in order to achieve good quality, passport-like photos. In order to obtain the training data, we have manually annotated all the whales in the training data with bounding boxes around their heads (a special thanks goes to our HR department for helping out!).
Bounding box produced by the head localizer
These annotations amounted to providing four numbers for each image in the training set: coordinates of the bottom-left and the top-right points of the rectangle. We then proceeded to train a CNN which takes an original image (resized to 256×256) and outputs the two coordinates of the bounding box. Although this is clearly a regression task, instead of using L2 loss, we had more success with quantizing the output into bins and using Softmax together with cross-entropy loss. We have also tried several different approaches, including training a CNN to discriminate between head photos and non-head photos or even some unsupervised approaches. Nevertheless, their results were inferior.
In addition, the head localizing network also had to predict the coordinates of the blowhead and bonnet-tip (in the same, quantized manner), however it was less successful in this task, so we ignored this output.
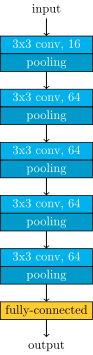
We trained 5 different networks, all of them had almost the same architecture.
Head localizer’s architecture
Where they differed is the number of buckets used to quantize the coordinates. We have tried 20, 40, 60, 128, and also another (a little bit smaller) network using 20 buckets.
Before feeding the image into the network, we had used the following data augmentation (after resizing it to 256×256):
– rotation: up to 10° (note that if you allow bigger angles, it won’t be enough to simply rotate the points – you’ll have to implement some logic to recalculate the bounding box – we were too lazy to do this),
– rescaling: random ratio between 1/1.2 and 1.2,
– colour perturbation (as in Krizhevsky et al. 2012), with scale 0.01.
Although we have not used test-time augmentation here, we combined the outputs from all the 5 networks. Each time a crop was passed to the next step (head alignment), a random one from all 5 variants was chosen. As can be seen above, the crops provided by these networks were quite satisfactory. To be honest – we did not really “physically” crop the images (i.e. produce a bunch of smaller images). What we’ve done instead, and what turned out to be really handy, is producing a json file with the coordinates of bounding boxes. This may seem trivial, but doing so encouraged and allowed us to easily experiment with them.
The final step of this “make the classifier’s life easier” pipeline was to align the photos so that they all conform to the same standards. The idea was to train a CNN that estimates the coordinates of blowhead and bonnet-tip. Having them, one can easily come up with a transformation that maps the original image into one where these two points are always in the same position. Thanks to the annotations made by Anil Thomas, we had the coordinates for the training set. So, once again we proceeded to train CNN to predict quantized coordinates. Although we do not claim that it was impossible to pinpoint these points using the whole image (i.e. avoid the previous step), we now face a possibly easier task – we know the approximate location of the head.
In addition, the network had some additional tasks to solve! First of all it needed to predict which whale is on the image (i.e. solve the original task). Moreover, it needed to tell whether the callosity pattern on the whale’s head is continuous or not (training on manual annotations once again, although there was much less work this time since looking at 2-3 images per whale was enough).
Broken (left) and continuous (right) callosity patterns
We used the following architecture.
Head aligner’s architecture
As an input to head aligner we took the crops from the head localizer. This time we dared to use a more bold augmentation:
– translation: random up to 4 pixels,
– rotation: up to 360°,
– rescaling: random ratio between 1.0 and 1.5,
– random flip,
– colour perturbation with scale 0.01.
Also, we used test-time augmentation – the results were averaged over 5 random augmentations (not much, but still!). This network achieved surprisingly good results. To be more (or less) accurate – during manual inspection, the blowhead and bonnet-tip positions were predicted almost perfectly for almost all images. Besides, as a by-product (or was it the other way?), we started to see some promising results for the original task of identifying the whales. The (quite pessimistic) validation loss was around 2.2.
Putting everything together
When chaining multiple machine learning algorithms in the pipeline, some caution is needed. If we train a head localizer and head aligner on the training data and use them to produce “passport photos” for both the training and testing set, we may end up with photos that vastly differ in quality (and possibly some other properties). This can turn out to be a serious difficulty when training a classifier on top of these crops – if at test time it faces inputs that don’t bear any similarity to those it was accustomed to, it does not perform.
Although we were aware of this fact, when inspecting the crops we discovered that the quality did not differ much between training and testing data. Moreover, we’ve seen a huge improvement in the log loss. Following the mindset of “more ideas, less dwelling”, we decided to settle on this impure approach and press on.
“Passport photos” of whales
Final classifier
Network architecture
Almost all of our models worked on 256×256 images and shared the same architecture. All convolutional layers had 3×3 filters and did not change the size of the image, all pooling layers were 3×3 with 2 stride (they halved the size). In addition all convolutional layers were followed by batch normalization and ReLU nonlinearity.
Main net’s architecture
In the final blend, we have also used a few networks with an analogous architecture, but working on 512×512 images, and one network with a “double” version of this architecture (with an independent copy of the stacked convolutional layers, merged just before the fully-connected layer).
Once again, we’ve violated the networks’ comfort zone by adding an additional target – determining the continuity of the callosity pattern (same as in the head aligner case). We’ve also tried adding more targets coming from other manual annotations, one such target was “how much was the face symmetric”. Unfortunately, it did not improve the results any further.
Data augmentation
At this point data augmentation is a little bit trickier than usual. The reason behind this, is that you have to balance between enriching the dataset enough, and not ruining the alignment and normalization obtained from the previous step. We ended up using quite mild augmentation. Although the exact parameters were not constant among all models, the most common were:
– translation: random up to 4 pixels,
– rotation: up to 8°,
– rescaling: random ratio between 1.0 and 1.3,
– random flip,
– colour perturbation with scale 0.01.
We also used test-time augmentation, and averaged over 20+ random augmentations.
Initialization
We used a very simple initialization rule, a zero-centred normal distribution with std 0.01 for convolutional layers and std 0.001 for fully connected layers. This has worked well enough.
Regularization
For all models, we have used only L2 regularization. However, separate hyperparameters were used for convolutional and fully connected layers. For convolutional layers, we used a smaller regularization, around 0.0005, while for fully connected ones we preferred higher values, usually around 0.01 – 0.05.
One should also recall that we were adding supplementary targets to the networks. This imposes additional constraints on weights, enforces more focus on the head of the whale (instead of, say, some random patterns on the water), i.e. it works against overfitting.
Training
We trained almost all of our models with stochastic gradient descent (SGD) combined with 0.9 momentum. Usually we settled after around 500-1000 epochs (the exact moment didn’t really matter much, because the lack of overfitting). During the training process we used quite slow exponential decay on the learning rate (0.9955) and also manually adjusted the learning rate from time to time. After a rough kick – increasing the learning rate (yet still leaving the decay) the network’s error (on both: training and validation) went up a lot. Yet it tended to settle on a lower error after a few epochs to get back on a good track. Our best model also uses another idea – it was first trained with Nesterov momentum for over a hundred epochs, and then we switched to using Adam (adaptive moment estimation). We couldn’t achieve similar loss when using Adam all the way from the start. The initial learning rate may not have mattered much, but we used values around 0.0005.
Validation
We used a random 10% of the training data for validation. Thanks to our favourite seed 7300, we kept it the same for all models. Although, we were aware that this method caused some whales to be absent in the training set, it has worked good enough. The validation loss was quite pessimistic, and correlated well with the leaderboard.
Giving up 10% of a relatively small dataset is not something one would decide to do without any hesitation. Therefore, after we had decided that a model is good enough to use it, we proceeded to reuse the validation set for training (it was straightforward because we didn’t have any problems with overfitting). This was done either by a time-consuming process of rerunning everything from scratch on the whole training set (rarely), or (more often) adding the validation set to the training one and running 50-100 additional epochs. This was also meant to curate the issue of single-photo-whales appearing only in our validation set.
Combining the predictions
We have ended up with a number of models scoring in a range of 0.97 to 1.3 according to our validation (actual test scores were actually better). Thanks to keeping a consistent validation set we were able to test some blending techniques as well as basic transformations. We have concluded that using more complex ensembling methods would not be plausible due to the fact that our validation set did not include all the distinct whales, and was, in fact, quite small. Having no time left for some fancy cross-validation like ensembling, we settled on something ad-hoc and simple.
Even though simple weighted average of the predictions did not provide a better score than the best model alone (unless we increased the best model’s weight significantly), it performed better when combined with a simple transformation of raising the predictions to a moderate power (in the final solution we used 1.45). This translated into roughly ~0.1 improvement in the log loss. We have not scrutinized this enough, yet one may hypothesize that this trick worked because our fully connected layers were strongly regularized, and were reluctant to produce more extreme probabilities.
We also used some “safety” transformations, namely increasing all the predictions by a certain epsilon as well as slightly skewing them to the whale distribution found in the training set. They had not impacted our score much.
Loading images
At the latest, and middle stages of our solution the images we loaded from the disk were original ones. They are quite big. To efficiently use the gpu we had to load them in parallel. We thought the main cost was loading the images from the disk. It turned out not to be true. Conversely, it was decoding JPEG file to a numpy array. We did a quick and dirty benchmark, with 111 random original images from the dataset, 85Mb total. Reading them, when they are not cached in RAM takes ~420 ms. Whereas reading, and decoding to numpy arrays takes ~10 seconds. That’s a huge difference. The possible solutions to mitigate this, might be using other image formats, that offer better encoding speeds (at the cost of image sizes), decoding at GPU, etc.
What might have made it tick
Although, it’s hard to pinpoint a single trick or technique that overshadows everything else (and to do so, one needs a more careful analysis), we have hypothesized about the key tricks.
Producing good quality crops with well aligned heads
We have achieved this by doing this in two stages, and the results were vastly superior than what we observed with just a single stage.
Manual labour and providing the networks with additional targets
This was based on adding additional annotations to the original images. It required manual inspection of thousands of whales images, but we ended up using them in all stages (head localizing, head aligning, and classification).
Kicking the learning rate
Although it might have been the combination of a little bit careless initialization, poor learning rate decay schedule, and not fancy enough SGD, it turned out, that kicking (increasing) the learning rate did a great job.
Loss functions after kicking the learning rate
Calibrating the probabilities
Almost all our models, and blends of models benefitted from raising the predictions to a moderate power in the range [1.1 – 1.6]. This trick, discovered at the end of the competition, improved the score by ~0.1.
Reusing the validation set
Merging validation and training sets and running for additional 50-100 epochs gave us steady improvements on the score.
Overall, this was an amazing problem to tackle and an amazing competition to take part in. We have learned a lot during the process, and are actually quite amazed with the super-powers of deep learning!
A special thanks to Christin Khan and NOAA for presenting the data science community with this exceptional challenge. We hope that this will inspire others. Of course, all this would be much harder without Kaggle.com, which does a great job with their platform. We would also like to thank Nvidia for giving us access to Nvidia K80 GPUs – they’ve done a great job.
Robert Bogucki
Marek Cygan
Maciej Klimek
Jan Kanty Milczek
Marcin Mucha
https://deepsense.ai/wp-content/uploads/2016/01/deep-learning-right-whale-recognition-kaggle.jpg3371140Robert Boguckihttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngRobert Bogucki2016-01-16 16:16:562021-01-05 16:51:52Which whale is it, anyway? Face recognition for right whales using deep learning
During the Christmas break I met my brother-in-law who is an ultimate gadgeteer (an excellent trait for brother). He told me that most iPhones have build-in motion coprocessor and by default they are counting steps. No need to turn on anything, it is working all the time (assuming that the phone is with you).
For phones 5s and up, if you have ‘Health’ application then you can easily check if your activity is being tracked.
Short googling and it turns our that the measurements are quite accurate (see wired magazine, the error is smaller than 1%). In some articles authors even proof that this method is more accurate that other fitness trackers.
As you can imagine, we spend rest of the evening trying to load this data to R and doing some data exploration. You can do this easily by yourself. To export the data from the phone just follow these instructions.
Data will be exported in a single xml file. Just send it by email and we can start our adventuRe.
First, let’s load the data to R
require(XML)
data <- xmlParse("export.xml")
xml_data <- xmlToList(data)
The app is measuring number of steps, distance, and some other parameters. Let’s extract only the number of steps.
Each row corresponds to number of steps per few minutes. For us it will be much easier to work with daily aggregates.
So some dplyr trick and we will have number of steps per day
dataDF <- xml_dataSelDF %>%
group_by(day) %>%
summarise(sum = sum(as.numeric(as.character(value))))
> head(dataDF)
# Source: local data frame [6 x 2]
#
# day sum
# (fctr) (dbl)
# 1 2015-02-18 90
# 2 2015-02-19 10683
# 3 2015-02-20 5465
# 4 2015-02-21 4212
# 5 2015-02-22 2085
# 6 2015-02-23 7199
A very nice time series!
So it’s time for some decomposition.
There is probably some periodicity related to weeks (I have different number of teaching hours in different days, for sure this will have some impact).
Let’s decompose the series into a seasonal component, trend and residuals.
Strong seasonal component. We will dig it deeper next time. The trend is around 10000 steps, not that bad.
Weeks between 20 and 25 are summer holidays. These larger bumps correspond to some hiking, sightseeing etc. Then around week 30 the winter semester has started. Teaching after longer break. This was not an active semester. Actually the November was a disaster in terms of activity. So you know my plans for the new year.
Next time I will show some more detailed exploration.
https://deepsense.ai/wp-content/uploads/2019/02/Exploration-of-data-from-iPhone-motion-coprocessor.jpg3371140Przemyslaw Biecekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPrzemyslaw Biecek2016-01-13 08:30:072021-01-05 16:51:57Exploration of data from iPhone motion coprocessor
The new version of the ggplot2 package (v 2.0.0) will be available on CRAN in a few days. It has a very nice mechanism for adding new geoms and stats (more about it here).
Let’s create a new geom geom_christmas_tree() that will plot data with the use of christmas trees instead of points. The geom will support following aesthetics: size, fill, color, x and y.
The size will be translated into the number of segments of each single tree. Width of a tree is fixed and height is proportional to the size.
Let’s start with an example.
# generate random positions, colors and sizes
mm = data.frame(matrix(runif(1200),300,4))
# plot
ggplot(mm, aes(X1, X2, size=X3, fill=X4)) +
geom_christmas_tree() +
theme_void() + scale_fill_gradient(low='green1', high='green4')
One can combine this geom with other geoms (like contours).
https://deepsense.ai/wp-content/uploads/2019/02/How-to-create-a-new-geom-for-ggplot2.jpg3371140Przemyslaw Biecekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPrzemyslaw Biecek2015-12-17 13:08:322021-01-05 16:52:02How to create a new geom for ggplot2
I’ve prepared a short console-based data-driven R game named ,,The Proton Game’’ or ,,Hack the Proton” (still cannot decide which name is better). The goal of a player is to play the hacker and infiltrate Slawomir Pietraszko’s account on a Proton server. To do this, you have to solve four data-based puzzles.
Can you make it?
Each puzzle can be solved in many different ways. One can use the dplyr package, or base R functions or anything else. If you are familiar with R and have some experience with data wrangling, then around 15 minutes will be enough to complete all puzzles.
To install the game you shall install the package proton from CRAN servers.
install.packages("proton")
To start the game just load the installed package.
library("proton")
Additional instructions will appear on your screen (see the figure below).
Have fun and wait for next games from the series!
https://deepsense.ai/wp-content/uploads/2019/02/Hack-the-Proton.jpg3371140Przemyslaw Biecekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPrzemyslaw Biecek2015-12-10 23:45:372021-01-05 16:52:07Hack the Proton