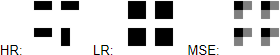Researchers from the deepsense.ai machine learning team, Piotr Miłoś, Błażej Osiński and Henryk Michalewski, together with Łukasz Kaiser from Google Brain’s TensorFlow team optimized infrastructure for reinforcement learning in the Tensor2Tensor project.
The idea behind the improvements was to develop an artificial intelligence capable of imagining and reasoning about the future. Instead of using precise and costly simulators or even more costly real-world data, the new AI spends most of its energy on imagining possible future events. The process of imagining is much less costly than gathering real data. At the same time, a properly trained imagination is a far cry from daydreaming. In fact, it makes it possible to precisely model reality and reason about it hundreds of times faster than would be possible using simulators.
The novelty of Tensor2Tensor consists in implementation of the Proximal Policy Optimization, which is completely contained in the computation graph. This is the main technical factor behind the lightning fast imagination.
In the second stage of the project the researchers from deepsense.ai, the University of Warsaw and Google Brain are focusing on the end-to-end training of an reinforcement learning agent fully inside a computation graph.
One of the steps in the experiment is the implementation of the Proximal Policy Optimization algorithm entirely using TensorFlow atoms. The training will be run on Cloud Tensor Processing Units (TPUs), which are custom Google-designed chips for machine learning. Assuming that a game simulator can be represented as a neural network, we expect that the whole training process can then be kept in the memory of the Cloud TPU.
Stay tuned for the results of our project!
https://deepsense.ai/wp-content/uploads/2019/02/artificial-intelligence-imagining-and-reasoning-about-the-future.jpg4021362Anna Kowalczykhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngAnna Kowalczyk2018-03-09 12:33:152023-04-14 00:07:02Artificial intelligence imagining and reasoning about the future
Companies pay astonishing amounts of money to sponsor events and raise brand visibility. Calculating the ROI from such sponsorship can be augmented with machine learning-powered tools to deliver more accurate results.
Event sponsoring is a well-established marketing strategy to build brand awareness. Despite being one of the most recognizable brands in the automotive industry, Chevrolet pays $71.4 million dollars each year to put its brand on Manchester United shirts.
How many people does your brand reach?
According to Eventmarketer’s study, 72% of consumers positively view brands that provide them with positive experiences, be it a great sports game or another cultural event, such as a music festival. Such events attract large numbers of viewers both directly and via media reports, allowing brands to get favorable positioning and work on their word-of-mouth recognition.
Sponsorship contracts often come at a steep price, so brand owners are naturally more than a little interested in finding out how effectively their outlays are working for them. However, it’s difficult to assess quantitatively just how great the brand exposure is in a given campaign. The information on brand exposure can further support demand forecasting efforts, as the company gains information on expected demand peaks that result from greater brand exposure in media coverage.
The current approach to computing such statistics has involved manually annotating broadcast material, which is tedious and expensive. To address these problems, we have developed an automated tool for logo detection and visibility analysis that provides both raw detection and a rich set of statistics.
We decided to break the problem down into two steps: logo detection with convolutional neural networks and an analytics for computing summary statistics.
The main advantage of this approach is that swapping the analytics module for a different one is straightforward. This is essential when different types of statistics are called for, or even if the neural net is to be trained for a completely different task (we had plenty of fun modifying this system to spot and count coins – stay tuned for a future blog post on that).
Logo detection with deep learning
There are two principal approaches to object detection with convolutional neural networks: region-based methods and fully convolutional methods.
Region-based methods, such as R-CNN and its descendants, first identify image regions which are likely to contain objects (region proposals). They then extract these regions and process them individually with an image classifier. This process tends to be quite slow, but can be sped up to some extent with Fast R-CNN, where the image is processed by the convolutional network as a whole and then region representations are extracted from high-level feature maps. Faster R-CNN is a further improvement where region proposals are also computed from high-level CNN features, which accelerates the region proposal step.
Fully convolutional methods, such as SSD, do away with processing individual region proposals and instead aim to output class labels where the region proposal step would be. This approach can be much faster, since there is no need to extract and process region proposals individually. In order to make this work for objects with very different sizes, the SSD network has several detection layers attached to feature maps of different resolutions.
Since real-time video processing is one of the requirements of our system, we decided to go with the SSD method rather than Fast R-CNN. Our network also uses ResNet-50 as its convnet backbone, rather than the default VGG-16. This made it much less memory-hungry, while also helping to stabilize the training process.
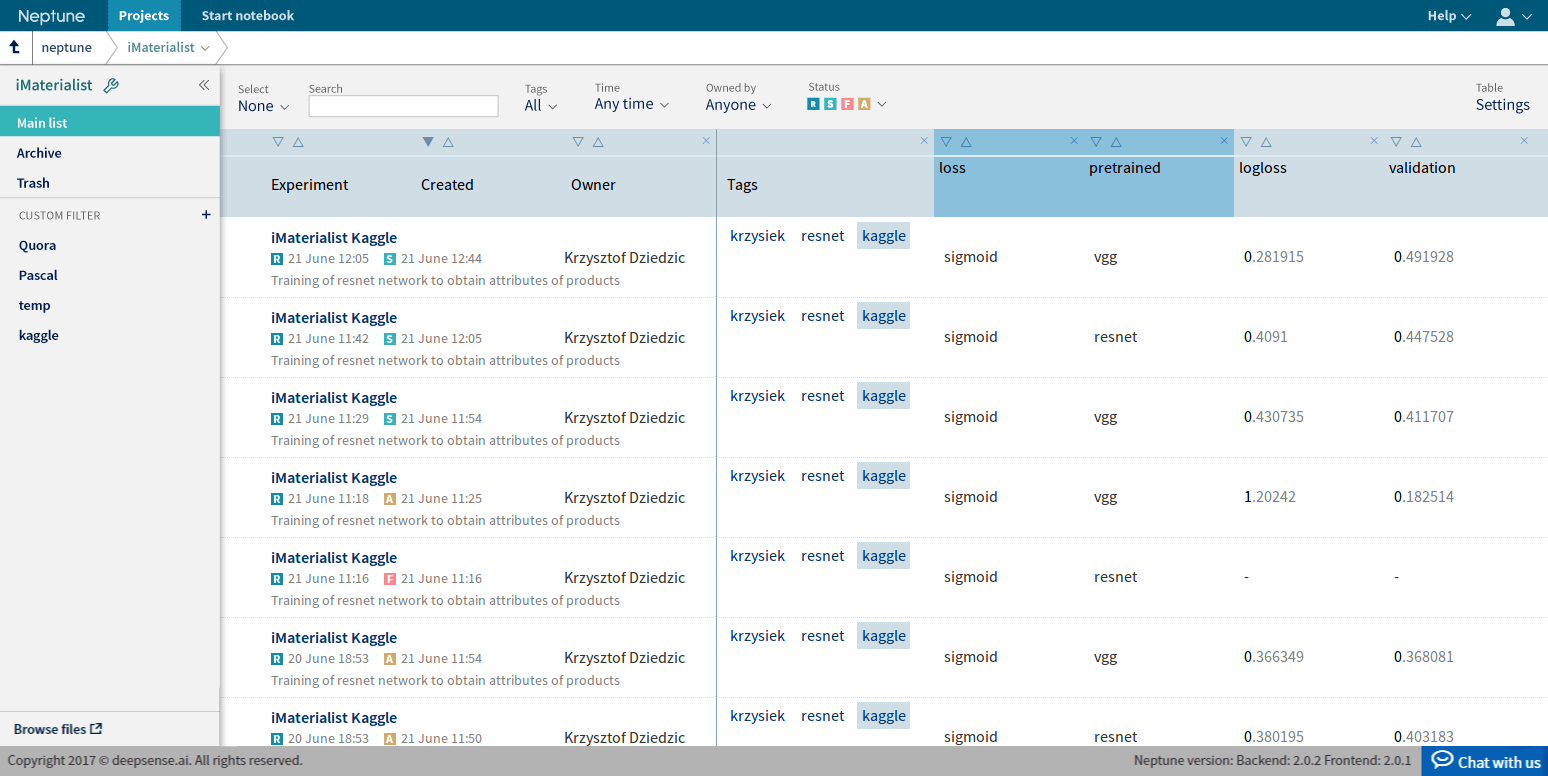
In the process of refining the SSD architecture for our requirements, we ran dozens of experiments. This was an iterative process with a large delay between the start and finish of an experiment (typically 1-2 days). In order to run numerous experiments in parallel, we used Neptune, our machine learning experiment manager. Neptune captures the values of the loss function and other statistics while an experiment is running, displaying them in a friendly web UI. Additionally, it can capture images via image channels and display them, which really helped us troubleshoot the different variations of the data augmentation we tested.
Logo detection analytics
The model we produced generates detections very well. However, when even a short video is analyzed, the raw description can span thousands of lines. To help humans analyze the results, we created software that translates these descriptions into a series of statistics, charts, rankings and visualizations that can be assembled into a concise report.
The statistics are calculated globally and per brand. Some of them, like brand display time, are meant to be displayed, but many are there to fuel the visual representation. Speaking of which, the charts are really expressive in this task. Some features include brand exposure size in time, heatmaps of a logo’s position on the screen and bar charts to allow you to easily compare various statistics across the brands. Last but not least, we have a module for creating highlights – visualizations of the bounding boxes detected by the model. This module serves a double purpose: in addition to making the analysis easy to track, such visualizations are also a source of valuable information for data scientists tweaking the model.
We processed a short video featuring a competition between rivals Coca-Cola and Pepsi to see which brand received more exposure in quantitative terms. You can watch it on YouTube by following this link. Which logo has better visibility?
Below, you can compare your guesses with what our model reported:
Possible extensions
There are many business problems where object detection can be helpful. Here at deepsense.ai, we have worked on a number of them.
We developed a solution for Nielsen that extracts information about ingredients from photographs of FMCG products, using object detection networks to locate the list of ingredients in photographs of products. This made Nielsen’s data collection more efficient and automatic. In its bid to save the gravely endangered North Atlantic Right Whale,The NOAA used a related technique to spot whales in aerial photographs. Similar techniques are used when the reinforcement learning-based models behind autonomous vehicles learn to recognize road signs.
With logo detection technology, companies can evaluate a campaign’s ROI by analyzing any media coverage of a sponsored event. With the information on brand positioning in hand, it is easy to calculate the advertising equivalent value or determine the most impactful events to sponsor.
With further extrapolation, companies can monitor the context of media coverage and track whether their brand is shown with positive or negative information, providing even more knowledge for the marketing team.
https://deepsense.ai/wp-content/uploads/2019/02/logo-detection-and-brand-visibility-analytics.jpg3371140Michal Romaniukhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngMichal Romaniuk2019-08-29 10:03:572024-02-06 19:08:48Logo detection and brand visibility analytics – example
Single Image Super Resolution involves increasing the size of a small image while keeping the attendant drop in quality to a minimum. The task has numerous applications, including in satellite and aerial imaging analysis, medical image processing, compressed image/video enhancement and many more. In this blog post we apply three deep learning models to this problem and discuss their limitations and promising ways to overcome them.
Single Image Super Resolution: Problem statement
Our objective is to take a low resolution image and produce an estimate of a corresponding high‑resolution image. This problem is ill‑posed – multiple high‑resolution images can be produced from the same low‑resolution image. For instance, suppose we have a 2×2 pixel sub‑image containing a small vertical or horizontal bar [Fig. 1]. Regardless of the orientation of the bar, these 4 pixels will correspond to just one pixel in a picture downscaled 4 times. With real life images, one needs to overcome an abundance of similar problems, making the task difficult to solve.
Figure 1: from left to right, ground truth HR image, corresponding LR image,
prediction of a model trained to minimize MSE loss
First, let’s introduce a quantitative quality‑measurement method to evaluate and compare the models. For each model implemented, we will compute a metric commonly used to measure the quality of reconstruction of lossy compression codecs, called Peak Signal to Noise Ratio (PSNR). This metric is a de‑facto standard used in Super Resolution research. It measures how much the distorted image (possibly of lower quality) deviates from the original high‑quality image. In this setting, PSNR is the ratio of maximum possible pixel value of the image (signal strength) to maximum mean squared error (MSE) between the original image and its estimated version (noise strength), expressed in logarithmic scale.
\(PSNR = 10 cdot log_{10}frac{MAX_I^2}{MSE}\)
The larger the PSNR values, the better the reconstruction, and therefore maximization of PSNR naturally leads to minimizing MSE as the objective function. That was our approach in two out of three models we present here.
In our experiments, we trained the models to upscale input images four times (in terms of width and height). Above this factor, upscaling even small images becomes hard – for example, an image upscaled eight times has a 64x bigger pixel count. Storing it consequently requires 64x more memory in raw form, to which it is converted during training.
We have tested our models on benchmarks commonly used in the literature – Set5, Set14 and BSD100. The performance of the models described on these datasets is cited in the papers, which allowed us to compare our results to those other authors have put forward.
The models were implemented in PyTorch, an open‑source neural network framework developed by Facebook.
One of the most commonly used techniques for upscaling an image is interpolation. Although simple to implement, this method leaves much to be desired in terms of visual quality, as the details (e.g. sharp edges) are often not preserved.
Figure 2: Most common interpolation methods produce blurry images. From top to bottom:
nearest neighbour interpolation, bilinear interpolation and bicubic interpolation. The image
was upscaled 4x.
More sophisticated methods exploit internal similarities of a given image or use datasets of low‑resolution images and their high‑resolution counterparts, effectively learning a mapping between them. Among example‑based SR algorithms, the sparse‑coding‑based method is one of the most popular.
This method requires a dictionary to be found that will allow us to map low resolution images into an intermediate, sparse representation. In addition, the HR dictionary is learned, and will allow us to restore our estimate of a high resolution image. Such a pipeline usually involves several steps and not all of them can be optimized. Ideally we would like to have all of these steps combined in one big step with all of its parts being optimizable. That effect can be achieved by a neural network, the architecture of which is inspired by sparse coding.
See more here.
SRCNN
SRCNN was the first deep learning method to outperform traditional ones. It is a convolutional neural network consisting of only 3 convolutional layers: patch extraction and representation, non‑linear mapping and reconstruction.
Before being fed into the network, an image needs to be upsampled via bicubic interpolation. It’s then converted to YCbCr color space, while only luminance channel (Y) is used by the network. The network’s output is then merged with interpolated CbCr channels to produce a final color image. We chose this procedure because we are not interested in changing colors (this is the information stored in the CbCr channels), but only their brightness (the Y channel), and ultimately because human vision is more sensitive to luminance (“black and white”) differences than chromatic differences.
We found SRCNN really difficult to train. It was sensitive to hyperparameter changes, and the set‑up presented in the paper (learning rate 10-4 for the first two layers, 10-5 for the last layer, SGD optimizer) caused our PyTorch implementation to produce sub‑optimal results. We observed small changes under some different learning rates, but in the end the thing that gave us the biggest performance boost was switching to Adam optimizer, with a learning rate of 10-5 used for all layers. The final network was trained on 14k 32×32 subimages from the same dataset as in original paper (91 images).
Figure 3: Upper left – bicubic interpolation, upper right – SRCNN, bottom left – perceptual loss, bottom right – SRResNet. SRCNN,
perceptual loss and SRResNet images were produced by our implementations of corresponding models.
Perceptual loss
Although SRCNN is already better than standard methods, there are some ways in which it can still be enhanced. As mentioned earlier, the network is unstable, and one may also wonder whether optimizing MSE is an optimal choice.
Clearly, the images obtained by minimizing MSE are overly smooth. (MSE tends to produce an image resembling the mean of all possible high resolution pictures, resulting in a given low resolution picture [Fig. 1]). MSE also does not capture the perceptual differences between the model’s output and the ground truth image. Consider a pair of images, where the second one is a copy of the first, but shifted a few pixels to the left. For a human the copy looks almost indistinguishable from the original, but even such a small change can cause PSNR to decrease dramatically.
How should the perceived content of a given image be preserved? A similar arises in neural style transfer, and perceptual loss is a potential solution. It too optimizes MSE, but instead of using the model output itself, one can use the high‑level image feature representations extracted from pretrained convolutional neural networks (in our case output from 7th layer of VGG16). The intuition behind this idea is that a network trained for image classification (like VGG) stores in its feature maps the information on what details of common objects look like. And we want our upscaled image to be made up of objects resembling real world ones as much as possible.
Apart from changing the loss function, network architecture is also remodeled. The model is much deeper than SRCNN, uses residual blocks and does most of the processing on low‑resolution images (which accelerates training and inference). Upscaling also happens inside the network. In their paper, the authors used transposed convolutions (also called deconvolutions) with kernel 3×3 and stride=2 for that purpose. Artifacts produced by this model seemed similar to those known as the checkerboard effect. To reduce this effect we also tried deconvolution with a 4×4 kernel and nearest neighbor interpolation followed by a 3×3 convolutional layer with stride=1. In the end, interpolation followed by convolutional layer gave the best results, but didn’t remove the artifacts completely. Similar effects were observed in the original report.
Similar to the process described in paper, our training pipeline consisted of a dataset of 288×288 random crops from nearly 10k images from MS‑COCO. We set the learning rate to 10-3 and used Adam as our optimizer. Unlike in the paper cited above, we skipped post‑processing (histogram matching) as it didn’t provide any improvement.
In order to maximise our PSNR performance, we decided to implement a network called SRResNet, which achieves state‑of‑the‑art results on standard benchmarks. The original paper mentions a way of extending it in a way that allows more high frequency details to be restored.
As with the residual network described in the previous paragraph, SRResNet’s residual blocks architecture is based on this post. There are two minor additions: first, SRResNet uses Parametric ReLU instead of ReLU, which generalizes the former by introducing a learnable parameter that makes it possible to adaptively learn the negative part coefficient. The other difference is the image upsampling method used – in SRResNet, sub‑pixel convolutional layers are used. This technique is thoroughly explained here.
The images generated by the SRResNet we trained are almost indistinguishable from the results presented in the paper. The training took two days, during which we used Adam optimizer with a learning rate of 10-4. The dataset used consisted of 96×96 random crops from MS‑COCO, similar to the perceptual loss network.
Future work
There are several promising deep learning‑based approaches to single image super resolution that we didn’t test due to time constraints.
This recent paper mentions superb PSNR results gained thanks to the use of a modified SRResNet architecture. The authors remove batch normalization from the residual layers, and increase the number of residual layers used from 16 to 32. The resulting network trains for seven days on NVIDIA Titan Xs. Our implementation of SRResNet trained for two days to get our results, which allowed for faster iterations and more efficient hyperparameter tuning, but would not be possible had the ideas described been implemented.
Our perceptual loss experiments show that PSNR may not be a good metric to use for evaluating super resolution networks. In our opinion, more research needs to be done on different types of perceptual loss. In the papers we have examined, we’ve only seen simple MSE between VGG feature map representations of network output and ground truth. It’s unclear why MSE, being a per‑pixel loss, would be a good choice in this case.
Another promising direction for super resolution is Generative Adversarial Networks. This original paper extends SRResNet by using it as part of the architecture called SRGAN. Images generated by the resulting network contain high frequency details, like animals’ fur or grass straws. While they may look more believable, the images generated suffer in the PSNR statistics.
Figure 4: From top to bottom: the image produced by our SRResNet implementation,
the image produced by SRResNet extension, and the original image
In this blogpost we have described our experiments with three different convolutional neural networks used for Single Image Super Resolution. The table below summarizes our results.
SRCNN
Perceptual loss
SRResNet
+ short inference
+ better than standard methods
– worst results among deep learning approaches
+ more natural looking results than SRCNN
– strong artifacts
+ state‑of‑the‑art results
– long inference
Figure 5: Advantages and disadvantages of the models discussed
Even a simple three layer SRCNN was able to beat most non‑deep‑learning methods when measured on standard benchmark datasets using PSNR. Our examinations of perceptual loss showed, however, that this measure is not perfect for evaluating our model’s performance, as we were able to produce visually appealing images that were much worse than bicubic interpolation when evaluated with PSNR. Finally, we reimplemented SRResNet and reproduced state‑of‑the‑art results on benchmark datasets.
https://deepsense.ai/wp-content/uploads/2019/02/using-deep-learning-for-single-image-super-resolution.jpeg3371140Katarzyna Kańskahttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKatarzyna Kańska2017-10-23 09:17:272024-03-11 15:45:24Using deep learning for Single Image Super Resolution
We’re thrilled today to announce the latest version of Neptune: Machine Learning Lab. This release will allow data scientists using Neptune to take some giant steps forward. Here we take a quick look at each of them.
Cloud support
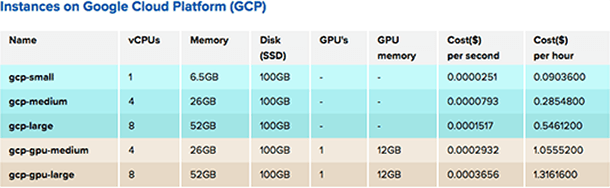
One of the biggest differences between Neptune 1.x and 2.x is that 2.x supports Google Cloud Platform. If you want to use NVIDIA® Tesla® K80 GPUs to train your deep learning models or Google’s infrastructure for your computations, you can just select your machine type and easily send your computations to the cloud. Of course, you can still run experiments on your hardware the way it was. We currently support only GCP–but stay tuned as we will not only be bringing more clouds and GPUs into the Neptune support fold, but offering them at even better prices!
With cloud support, we are also changing our approach to managing data. Neptune uses shared storage to store data about each experiment, for both the source code and the results (channel values, logs, output files, e.g. trained models). On top of that, you can upload any data to a project and use it in your experiments. As you execute your experiments, you’ve got all your sources at your fingertips, in the /neptune directory, which is available on fast drive for reading and writing. It is also your current working directory – just like you would run it on your local machine. Alongside this feature, Neptune can still keep your original sources so you can easily reproduce your experiments. For more details please read documentation.
Interactive Notebooks
Engineers love how interactive and easy to use Notebooks are, so it should come as no surprise that they’re among the most frequently used data science tools. Neptune now allows you to prototype faster and more easily using Jupyter Notebooks in the cloud, which is fully integrated with Neptune. You can choose from among many environments with different libraries (Keras, TensorFlow, Pytorch, etc) and Neptune will save your code and outputs automatically.
New Leaderboard
Use Neptune’s new leaderboard to organize data even more easily.
You can change the width of all columns and reorder them by simply drag and dropping their headings.
You can also edit the name, tags and notes directly in the table and display metadata including running time, worker type, environment, git hash, source code size and md5sum.
The experiments are now presented with their Short ID. This allows you to identify an experiment among those with identical names.
Sometimes you may want to see the same type of data throughout the entire project. You can now fix chosen columns on the left for quick reference as you scroll horizontally through the other sections of the table.
Parameters
Neptune comes with new, lightweight and yet more expressive parameters for experiments.
This means you no longer need to define parameters in configuration files. Instead, you just write them in the command line!
Let’s assume you have a script named main.py and you want to have 2 parameters: x=5 and y=foo . You need to pass them in the neptune send command:
neptune send -- '--x 5 --y foo'
Under the hood, Neptune will run python main.py –x 5 –y foo , so your parameters are placed in sys.argv . You can then parse these arguments using the library of your choice.
An example using argparse :
At deepsense.ai, we strive to make our mark on the cutting-edge research leading towards intelligent machines by providing practical machine learning tools and designs that make it much easier for scientists to track their experiments and verify novel ideas.
One particular step towards achieving this ideal was distributing a state-of-the-art Reinforcement Learning algorithm on a large CPU cluster, allowing super-fast training of agents that learned to master a wide range of Atari 2600 games. This post contains a brief description of our Distributed Deep Reinforcement Learning experiments. For a more in-depth look you can read our paper on the matter here.
Distributed reinforcement learning
Atari games are a widely accepted benchmark for deep reinforcement learning (RL). One common characteristic of these games is that they are very easy for humans to crack conceptually. Comparing the time it takes humans and computers to master these games can provide a clear indication of the capabilities of modern artificial intelligence. The first approaches to teach an agent to play Atari were developed by DeepMind and required around a week of training. The A3C algorithm developed later was able to achieve human performance in most games and did so with a similar amount of training time. But could computers ever learn faster than us?
Creating such a quick and bright Atari games learner would mean that computers outpaced us in understanding a game environment. The techniques that said agent would use to quickly develop a good grasp of the game could be studied to further develop our understanding of the cognitive features of a human brain. Moreover, faster training would give researchers considerably more flexibility in terms of experimenting and thus make verifying various RL approaches much quicker. Today, we present a Distributed Reinforcement Learning algorithm that efficiently trains on a large cluster of 64 12-core CPUs (768 cores in total). Our design enables agents to learn to play Atari games in as little as 20 minutes. We’re making our implementation available here.
Breakout
Initial performance
After 15 minutes of training
After 30 minutes of training
Assault
Initial performance
After 15 minutes of training
After 30 minutes of training
Boxing
Initial performance
After 15 minutes of training
After 30 minutes of training
Our achievement and results
By distributing the BA3C (details of single-machine implementation here) reinforcement learning algorithm, we were able to make an agent teach itself to play a wide range of Atari games rapidly, by just looking at a raw pixel output (game screen) from the game emulator. Our best experiments were distributed across 64 machines, each of which had 12 Intel CPU cores. In the game of Breakout, our agent achieves a superhuman score in just 20 minutes, which is a significant reduction of the single machine implementation learning time.
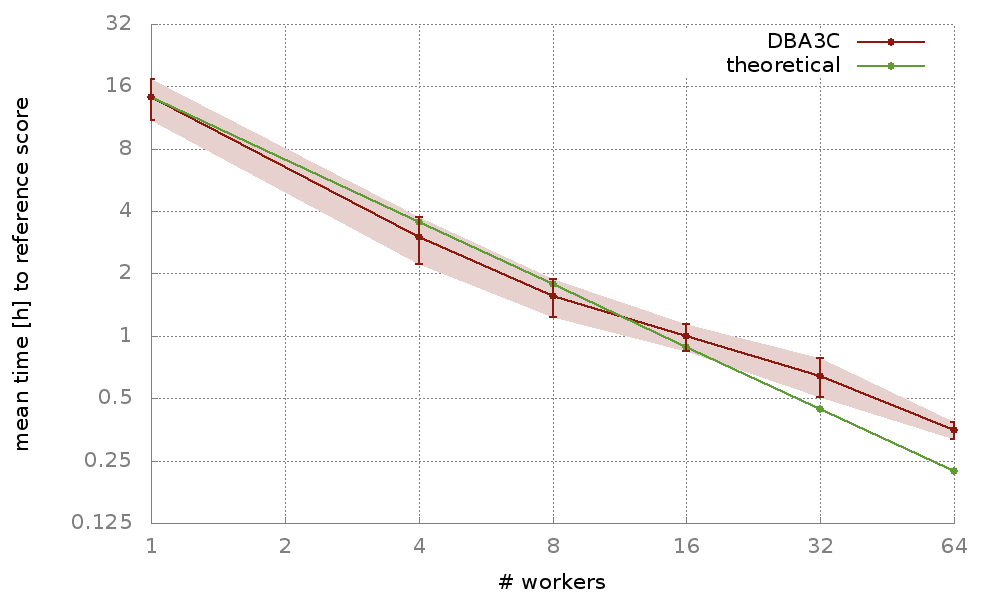
Training for Breakout on a single computer takes around 15 hours, bringing our implementation very close to the theoretical scaling (assuming computational power is maximized, using 64 times more CPUs should yield a 64-fold speed-up). The graph below shows the scaling of our implementation for different numbers of machines. Moreover, our algorithm exhibits robust results on many Atari environments, meaning that it is not only fast, but also adaptable to various learning tasks.
Graph showing the mean time of our algorithm (DBA3C) to achieve a score of 300 in the game of Breakout (average score of 300 needs to be obtained in 50 consecutive tries). The green line shows the theoretical scaling in reference to a single machine implementation.
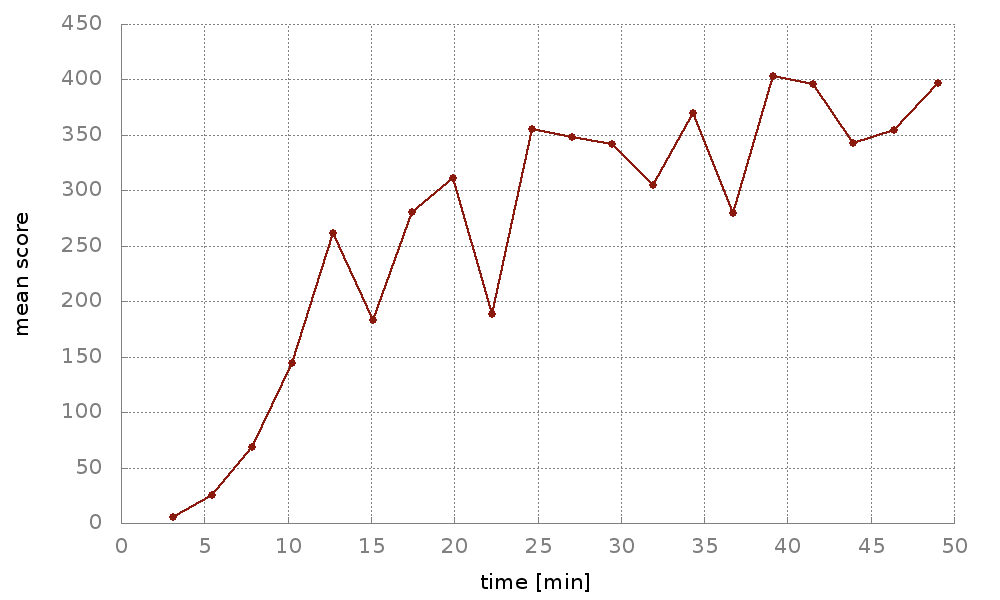
Using Neptune, a tool developed here at deepsense.ai, we were able to proactively track the performance of our agents. This enabled us to instantly verify if a certain feature of the algorithm works as expected. In Neptune, we could observe our agents’ real-time scores along with many other experiment-related metrics that we later used to optimize the algorithm. The graph below shows training curves from 10 different experiments on the Breakout game. Graphs were updated live in Neptune as the training went on.
A plot showing the live mean score obtained by the agent in 50 consecutive trials of Breakout
We managed to achieve very competitive training times. As we hope to inspire further research in the RL domain, we decided to open-source the implementation of our distributed reinforcement learning algorithm.
Details of the implementation
In the following section we describe the technicalities of our distributed set-up, aiming primarily to address a more advanced audience. To get the most out of our description, we recommend readers familiarize with this study done by the Google Brain team.
For parallelization we chose the synchronous paradigm. Synchronizing all our workers yielded much faster training times than the asynchronous set-up, where each node works for itself. Using a synchronous design prevented our model from using stale gradients in the updates, but at the same time introduced a problem known as slow stragglers. As suggested in the Google study linked above, deploying a few more backup workers can significantly reduce the impact of the slow stragglers, and doing just that has worked very well for us.
One of the biggest challenges that arises when dealing with largely distributed training is the cluster interconnect congestion on the parameter server nodes. Sending the gradients from multiple workers to a single parameter server bottlenecks the pipeline, effectively slowing down the training process.
To deal with that, we first reduced the model’s size. We noticed that a contraction of the neural network did not affect the accuracy of the algorithm, but did significantly increase the number of points processed per second, and hence also its speed.
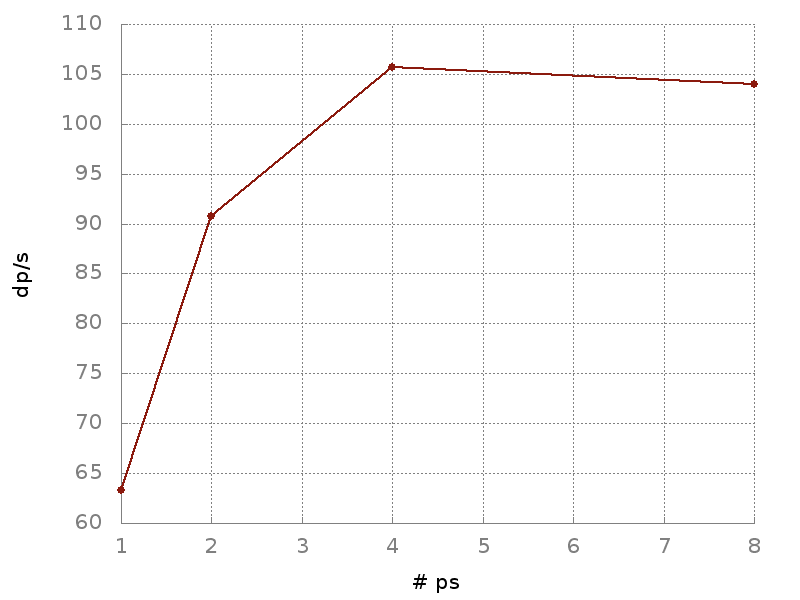
Since the communication overhead between the workers and parameter server was the biggest impeding factor to the speed of learning, we decided to balance the pressure on the pipeline by adding more parameter servers. This way, with the model weights distributed uniformly on multiple parameter servers, our training times began to pick up speed. The increase in processed data points per second for a different number of parameter servers can be seen below.
Graph showing the relation between the number of parameter servers and processed data-points per second – we can see that using more parameter servers significantly increases the dp/s
Related work
The distributed paradigm has been a topic of extensive research. Parallelization on 256 concurrent GPUs recently enabled a Facebook team to efficiently train the Resnet-51 model in one hour. Later developments from UC Berkeley reduced the time of training ImageNet to merely 24 minutes. The development of a distributed evolution strategy (ES) algorithm has led researchers from OpenAI to train agents to play Atari games in one hour by using 720 parallel CPUs. Since none of these designs have ever been applied to classical RL, the work done here can be considered pioneering in the field of distributed reinforcement learning.
Acknowledgements
The work on this distributed reinforcement learning design would not have been possible without the services of the PL-Grid supercomputing infrastructure, which provided us with all the computational power needed to conduct this research. We would like to thank Henryk Michalewski from the University of Warsaw for supervising the project and granting us access to the PL-Grid. We also used tensorpack, developed by Yuxin Wu, a very efficient open-source implementation of the A3C algorithm.
https://deepsense.ai/wp-content/uploads/2019/02/Solving-Atari-games-with-distributed-reinforcement-learning.jpg3371138Igor Adamskihttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngIgor Adamski2017-10-04 10:00:002021-01-05 16:49:18Solving Atari games with distributed reinforcement learning
Everybody who watched ‘Minority Report’, Steven Spielberg’s movie based on the Philip Dick’s short story, daydreams about crime forecasting in the real world. We have good news: machine learning algorithms can do just that!
In September 2016, the National Institute of Justice in the US announced the Real-Time Crime Forecasting Challenge. The goal was to predict future crimes in the city of Portland, OR. CodiLime, deepsense.ai’s parent company, took part in it, giving the job to our machine learning team. The results were revealed in August 2017: we did a great job and won eight out of 40 sub-competitions! In this post we describe the crime forecasting algorithms we used.
Competition rules
Fortunately, the NIJ didn’t ask contestants to carve names of forthcoming criminals and victims into wooden balls, as was the case in the movie. Instead, they wanted to know the hotspots – small areas with the greatest ‘intensity’ of future crimes.
Frame from ‘Minority Report’: red ball means a murder of passion. What color should the ball that predicts a tax fraud of passion be?
Three different types of crimes were considered separately: burglary, car theft and street crimes (including assaults, robberies, shots fired). Additionally, all the crimes together were of interest as well.
The end of February 2017 was the deadline and five future timespans were involved:
The first week of March 2017,
The first two weeks of March 2017,
All of March 2017,
March and April 2017,
March, April and May 2017.
Thus, we had to make 4 x 5 = 20 individual crime forecasts for 20 type/time categories (e.g. ‘burglary, two weeks’).
Once we finished May 2017, in each of 20 type/time categories our hotspot predictions were compared against the actual state of affairs in Portland using two independent metrics:
‘crime density’: number of crimes that occurred in hotspots divided by the total volume of hotspots,
‘prediction efficiency’: the number of crimes that occurred in hotspots divided by the number of crimes in the actual worst regions with the same total volume as our hotspots.
Hence, the competition consisted of 4 x 5 x 2 = 40 separate sub-competitions in total (e.g. ‘burglary, two weeks, crime density’). The winner took it all in each of them and the all was $15,000. So, there was $600,000 in the pot – a good motivation to work!
To be clear, three independent clones of the Real-Time Crime Forecasting Challenge were run simultaneously. The one we took part in was intended for large businesses. Of the remaining two, one was run for small businesses and the other for students. Every clone had the same rules and goals, but its own contestants, winners and prizes.
Our solution
Data
In ‘Minority Report’, the Precrime Police unit got their crime forecasts from Precogs, three mutated humans who could see into the future. At deepsense.ai, our Precrime unit created the predictions based on the past.
Frame from ‘Minority Report’: Precogs doing their forecasting thing. Fortunately, the deepsense.ai team isn’t forced to work under such conditions.
The organizer delivered historical data with all the crimes registered in Portland between March 2012 and February 2017. Almost 1,000,000 records were provided in total. Each of them contained daytime, place (with accuracy to one foot!) and the type of crime committed.
Our first question was: since we have no Precogs onboard, can we use anything else than historical data? What could affect future crimes, but hadn’t left a trace on those that had already been committed? Well, in our opinion these could only be future events. But are they easier to predict than crimes themselves? For instance, one can page through local newspapers seeking sentences like ‘A new gin mill is going to be opened in March 2017. The crime rate will certainly rise there.’ However, such research requires a lot of work and there is no guarantee it’ll actually help. So we decided to squeeze as much out of the historical data only as we could.
Blind contest
No leaderboard was run during the contest. We didn’t know how many competitors we had and how honed their crime forecasting skills were. The only thing we could do to win was improve our own results over and over.
Frame from ‘Minority Report’: temporarily blind John Anderton. This is how the lack of a leaderboard made us feel.
The first attempts showed us that in each of 20 type/time categories the ‘crime density’ metric was maximized by a lot of small hotspots whereas the ‘prediction efficiency’ performed best for a small number of large hotspots. Hence it was clear that we couldn’t satisfy both metrics simultaneously. Since each metric formed an independent sub-competition with a separate prize, it was better to have a good score for one metric than mediocre results for both. So, for each of the 20 type/time categories we had to decide which metric to focus on in our further work.
Which metric to choose when the metrics are incomparable, scores between categories are incomparable and you don’t know other competitors’ results? We checked that under some reasonable assumptions the best strategy is to just toss a coin; and this is what we did, 20 times – once per type/time category.
Bad neighborhoods remain bad
The major rule we followed while building our models was rather pessimistic: ‘if many crimes have occurred somewhere, more are likely to happen.’ This principle may strike some as naive, but the longer we explored the data, the more confident we were that it worked.
Frame from ‘Minority Report’. You can be sure that your neighborhood is safe when the Police flies around.
Not every past crime is equally important. We took advantage of the aging and seasonality of data. We focused more on data from 2017 and 2016 than on older ones. Also, we boosted the significance of crimes committed in the same season as the forecasting time. For instance, to make predictions for March 2017 we took special care of data from preceding Marches.
Moreover, as we know, evil is prone to ‘radiate’. When a crime is committed, we can expect others to happen nearby. This is why we decided to ‘diffuse’ the data points. For those who like statistical jargon, we note that this technique is called kernel density estimation.
However, we didn’t set the ‘intensities’ of data aging, seasonality and diffusion by hand. They were adjusted by our algorithm automatically. How did it know how to do that, you ask? As always in machine learning, it just chose them to obtain the best results! For each of 20 type/time categories we separated the last period of historical data as a validation dataset (e.g. February 2017 for a forecasting of March 2017). The algorithm used all but validation data to check which parameters best predict crimes from the validation set. Then, ultimately, it took all the available data to prepare the final crime forecasting.
Neptune
We must say that the Real-Time Crime Forecasting Challenge was also a logistic challenge. We had to manage and improve 40 models simultaneously. To do that we used our own machine learning lab called Neptune. We designed it for precisely this type of task: to easily store, compare and recreate a lot of experiments. To be honest, we can’t imagine how one would handle 40 models without using this tool.
Results
The results were announced in August 2017: in our large-business group we won 8 out of 40 sub-competitions, were the runner-up in 6 more and took third place in yet another 6. This is a big success, but there is something we are especially proud of. We compared crime forecasts from all the three clones of the competition: large businesses, small businesses and students, and it turned out that our results would give us the top place in the total ranking! Our team finished with the best predictions in seven sub-competitions, three more that the runner-up managed.
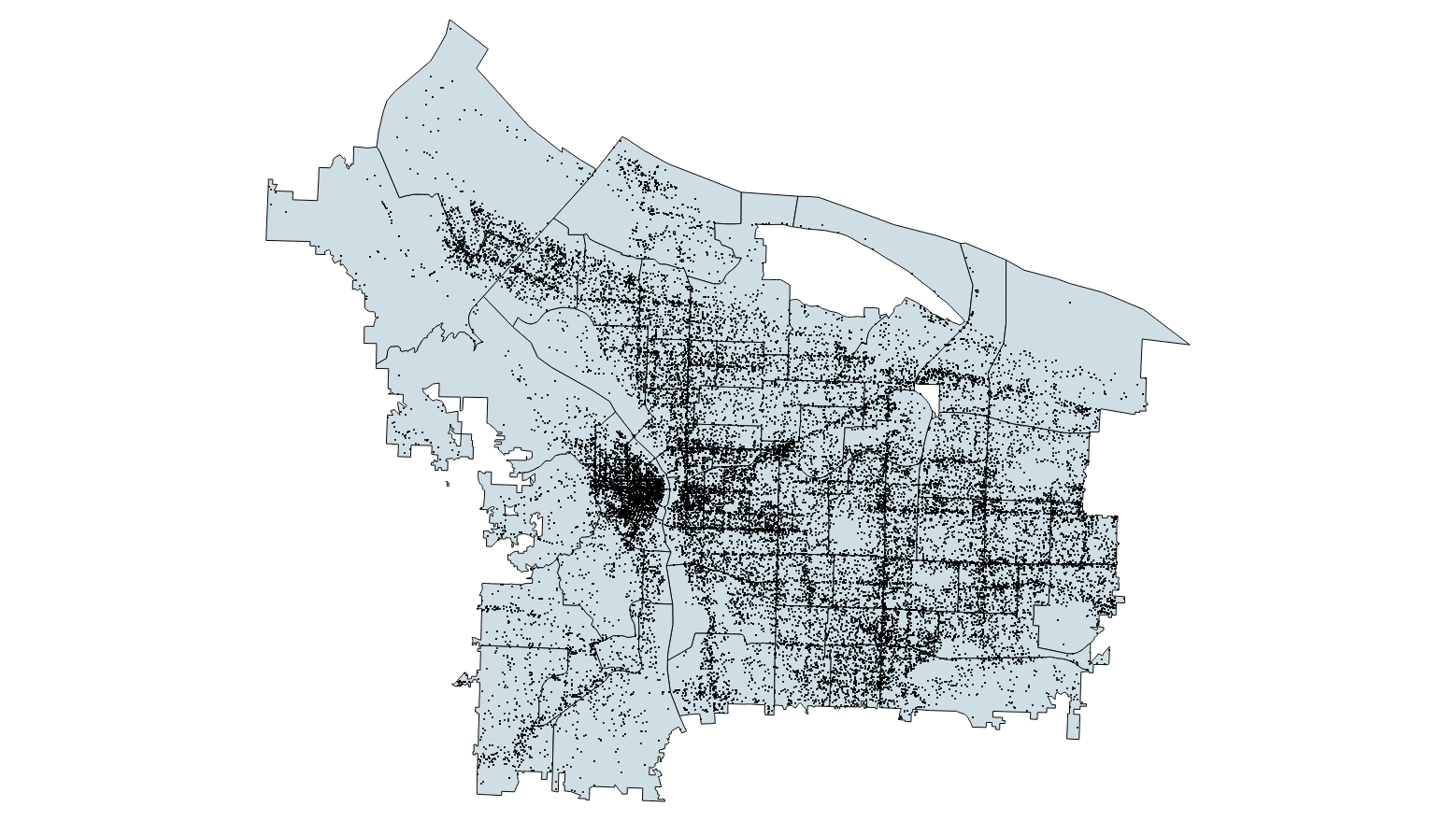
Do you want to see one of our winning crime forecasts? Here it is:
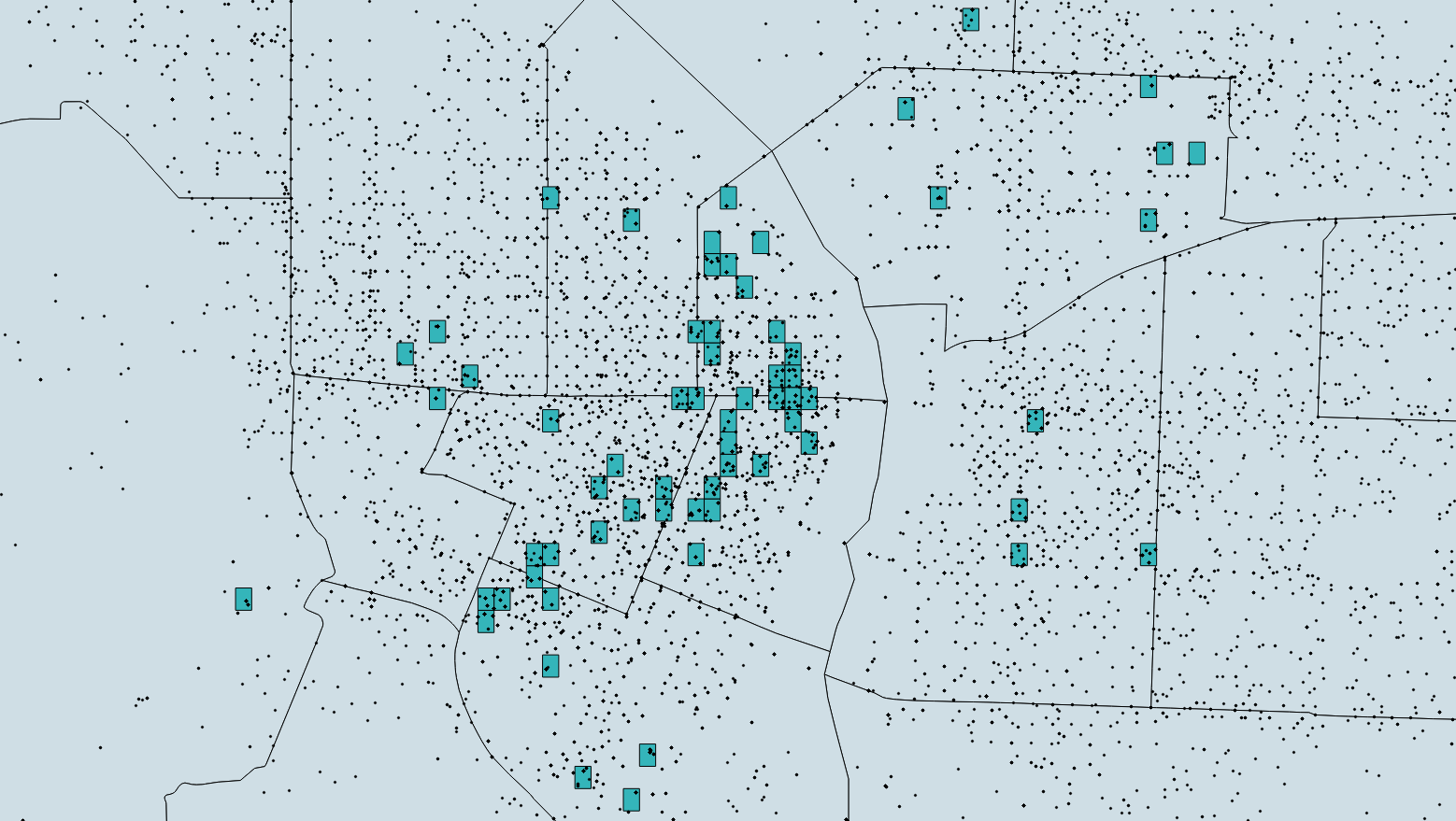
The gray area is Portland, around 15 by 20 miles. 56,000 black dots are all the crimes committed between March and May 2017. The hotspots we chose are blue, but you probably can’t see them, so let’s zoom in on the Downtown:
We indicated 112 hotspots, 294 by 213 ft each. They appear to be placed randomly, but they are not, they lie optimally. This is why machine learning algorithms are so fun: it’s hard to deal with their outputs using common sense, but they work!
Needle in a haystack
The total number of crimes in Portland between March and May 2017 – 56,000 – is impressively big. Another category was on the opposite pole: during the first week of March 2017 only 20 (twenty) burglaries were committed in the investigated area!
Frame from ‘Minority Report’. We doubt if these fancy gloves are more comfortable than good old mouse and keyboard.
If you think that it is hard to shoot 20 random events in a 150 mi2 area with use of bars with the total volume less than ¾ mi2 (the organizer’s requirement), you are absolutely right. In our opinion it was a matter of luck. We indeed hit one burglary, but it wasn’t enough to win this category.
But there was another way. The number of 20 crimes is so small that hypothetically any cheater could simply change the history and assure his victory by arranging a burglary or two in fixed places. Of course we didn’t do that and we think that nobody did since 20-25 is a typical amount of weekly burglaries in Portland. Experienced data scientists wouldn’t try this hoax because they’d know that if they weren’t the only ones who were going to do so, they wouldn’t benefit from this highly risky move. And, above all, they tend to spend their time on doing data science stuff rather than plotting fake crimes – being honest is usually a simpler way for us. However, in the ‘Minority Report’ universe a wooden ball would inform us about any bad intentions. In our world we just believe in people… or we can predict their behavior using machine learning algorithms!
Summary
If you’ve enjoyed our post or want to ask about anything related to crime forecasting (or maybe demand forecasting?), please leave us a reply!
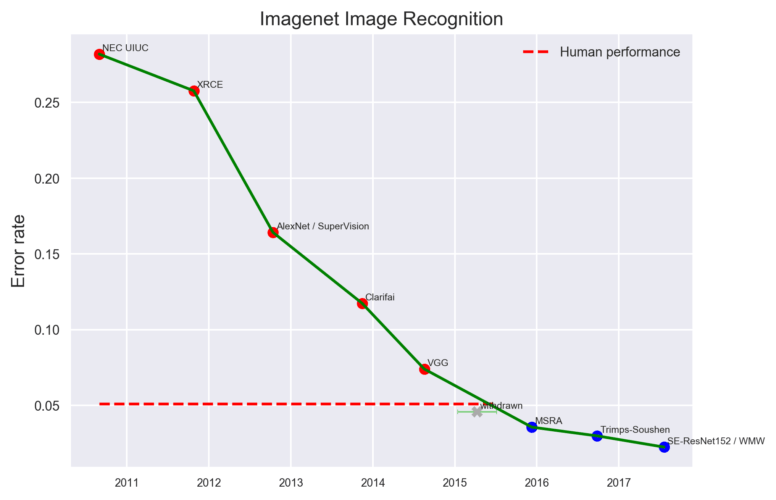
Deep learning vs human perception: creating a log loss benchmark for industrial & medical image classification problems (e.g. cancer screening).
In the last few years convolutional neural networks have outperformed humans in most visual classification tasks. But there is one caveat – usually they win by a small margin:
Chart from Measuring the Progress of AI Research by EFF (CC BY-SA).
There are few exceptions to this rule, including the whale individuals detection contest our deepsense.ai team won (85% accuracy for almost 500 different whales). However, one could argue that a computer’s pattern recognition skills were similar to a human’s, but it was easier for the computer to memorize 500 different whale specimens.
When we train our deep learning model for an image classification task, how do we know if it is performing well? One way to approach this problem is to compare it against a human performance benchmark. We expect human errors even for simple tasks – labels can be misclassified and the person performing the classification is likely to make mistakes from time to time: after all, “to err is human”.
Creating benchmarks for medical and industrial problems is even more challenging, because:
we don’t have a simple sanity check (unlike distinguishing dogs from cats),
it is not obvious if a single photo devoid of any context is enough for classification (very often even for the best specialists it is not).
Measuring human accuracy for medical images
In the Cervical Cancer Screening Kaggle competition (by Intel & MobileODT), the goal was to predict one of three classes of cervical openings for each patient. To see this image classification task, visit (warning: explicit medical images) Cervix type classification or this Short tutorial on how to (humanly) recognize cervix types.
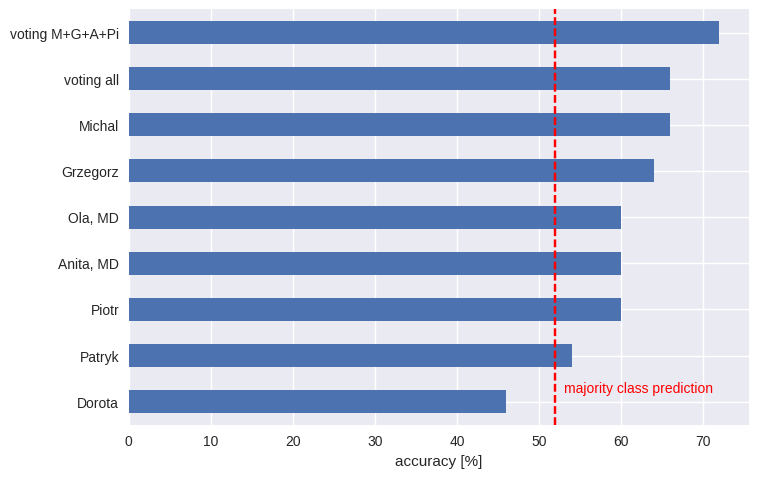
Our networks in this competition were just a bit better than a random model. We wanted to quantify human performance to see if our networks were bad, or if it is simply impossible to do much better. To measure human accuracy, we sampled 50 cervix images. This number sounded like a reasonable trade-off: high enough for some estimations, but small enough not to exhaust us. Unlike Andrej Karpathy, who set the human benchmark for ImageNet, we avoided going through the whole dataset. We looked at them ourselves and also gave them to two medical doctors, one a gynecologist. The task was to predict the cervix opening class for each image. The accuracy was as follows:
At least most of us did better than using the majority class prediction – i.e. assigning each image to the most numerous class. The medical doctors didn’t outperform the rest of us. That may seem surprising, but there is a common phenomenon at work here: many visual task much knowledge, just good pattern recognition (even pigeons can detect cancer from photos). Even less unexpected is the wisdom of crowds – an ensemble model (which involves members of “the crowd” voting) significantly outperformed each individual prediction.
Translating categorical predictions into log loss
However, many machine learning tasks use another measure of error – log loss (also known as cross-entropy), which takes into account our uncertainty (e.g. it is better to predict the correct class with 90% certainty than with 51%). It is especially important for problems with imbalanced classes. If we want to use the same prediction for a group of items, to minimize log loss we need to use empirical probabilities for the sample. For the whole sample of cervixes, those probabilities would be (18%, 52%, 30%) for classes 1, 2 and 3, respectively, resulting in a log loss of 1.01.
To measure human log loss we need to ask people to predict a probability distribution for each image, e.g. (20%, 70%, 10%). However, this task is time-consuming and can be difficult to explain to non-data scientists, in this case medical doctors. Humans are notoriously bad at assigning probabilities, so this approach would most likely need calibration anyway.
Fortunately, there is a very simple probability calibration technique, which takes discrete predictions as its input. Here’s the recipe:
predict a class for each image (here: 1, 2 or 3)
for all instances with the same predicted class, calculate the empirical distribution of the ground truth values
turn discrete predictions into the respective distributions
given the predictions, calculate the log loss
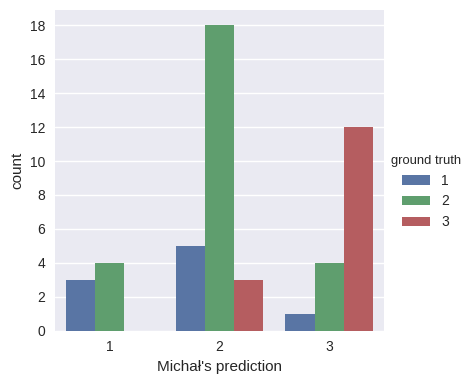
For example, for Michał (the project leader and top guesser), it is:
So, whenever he predicted class 1, we assign it to the (3/7, 4/7, 0/7) probability distribution, for class 2 – (5/26, 18/26, 3/26) and for class 3 – (1/17, 4/17, 12/17). His log loss on the same dataset is 0.78. This procedure is equivalent to calculating the conditional entropy of cervix classes, given our prediction, that is: H(groud_truth | our_prediction). See also the Wikipedia page on mutual information and its relation to conditional entropy.
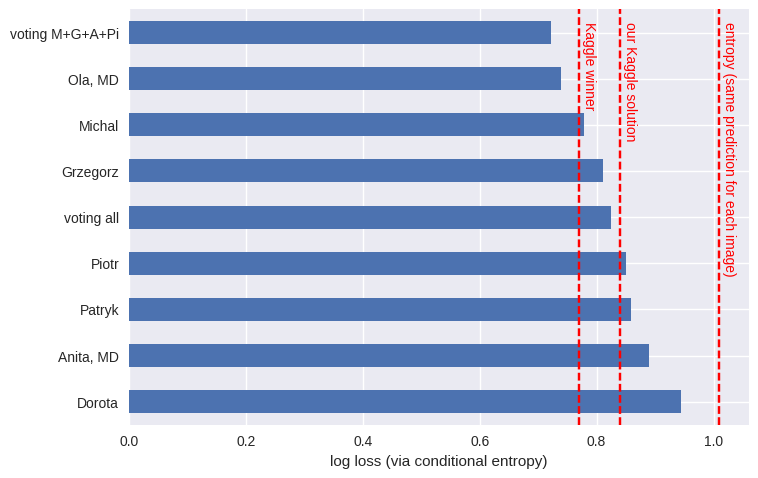
Human predictions vs Kaggle results
Here we calculate the conditional entropy for each participant:
How does this compare to the final Kaggle results? Ultimately, the top winner had a log loss of 0.77, whereas our (artificial, not biological) neural network ensemble returned 0.84. Neither of those beat us humans, with our log loss of 0.73.
During the competition phase had seen entries with log loss as low as 0.4. We hadn’t known if the authors had used a clever approach, or if it had been simply an overfit. After our human test, however, we rightfully assumed that it was indeed a large overfit. It seems that this technique may be useful for setting a reasonable benchmark for your next image classification problem – whether it’s a Kaggle challenge or a project for your customer.
Additional materials
Remarks
This technique may underestimate log loss (in general, there is no unbiased estimator for Shannon entropy). A more educated way (but one requiring more samples) would be to use cross-validation. To avoid ending up with zero probabilities, smoothing probabilities may be crucial.
We can use different classes for guessing than when we want to predict, for example, using the option “I don’t know”. The magic of methods related to entropy is that they are label-insensitive.
To learn more about entropy, read the first two chapters of Thomas M. Cover, Joy A. Thomas, Elements of Information Theory.
Code snippet
import numpy as np
from sklearn.metrics import confusion_matrix
# label - ground truth labels
# predictions - prediction labels
def entropy(x, epsilon=1e-6):
# assumes x is normalized
return (- x * np.log(x + epsilon)).sum()
def conditional_entropy(mat):
mat = mat / mat.sum()
return entropy(mat) - entropy(mat.sum(axis=0))
print(conditional_entropy(confusion_matrix(label, prediction)))
Project members: Michał Tadeusiak (leader), Grzegorz Łoś, Patryk Miziuła, Dorota Kowalska, Piotr Migdał.
Thanks also to Robert Bogucki, Paweł Subko and Agata Chęcińska for valuable remarks on the draft.
https://deepsense.ai/wp-content/uploads/2019/02/human-log-loss-for-image-classification.jpg3371140Piotr Migdalhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPiotr Migdal2017-09-12 08:53:032023-09-01 23:15:07Human log loss for image classification
Product recognition is a challenging area that offers great financial promise. Automatically detected product attributes in photos should be easy to monetize, e.g., as a basis for cross-selling and upselling.
However, product recognition is a tough task because the same product can be photographed from different angles, in different lighting, with varying levels of occlusion, etc. Also, different fine-grained product labels, such as ones in royal blue or turquoise, may prove difficult to distinguish visually. Fortunately, properly tuned convolutional neural networks can effectively resolve these problems.
In this post, we discuss our solution for the iMaterialist challenge announced by CVPR and Google and hosted on Kaggle in order to show our approach to product recognition.
The problem
Data and goal
The iMaterialist organizer provided us with hyperlinks to more than 50,000 pictures of shoes, dresses, pants and outerwear. Some tasks were attached to every picture and some labels were matched to every task. Here are some examples:
blue, blue jeans, denim blue, light blue, light, denim
pants: type
jeans
pants: age
adult
pants: decoration
men jeans
pants: gender
men
task
labels
shoe: color
dark brown
shoe: up height
kneehigh
pants: color
black
Our goal was to match a proper label to every task for every picture from the test set. From the machine learning perspective this was a multi-label classification problem.
There were 45 tasks in total (a dozen per cloth type) and we had to predict a label for all of them for every picture. However, tasks not attached to the particular test image were skipped during the evaluation. Actually, usually only a few tasks were relevant to a picture.
Problems with data
There were two main problems with data:
We weren’t given the pictures themselves, but only the hyperlinks. Around 10% of them were expired, so our dataset was significantly smaller than the organizer had intended. Moreover, the hyperlinks were a potential source of a data leak. One could use text-classification techniques to take advantage of leaked features hidden in hyperlinks, though we opted not to do that.
Some labels with the same meaning were treated by the organizer as different, for example “gray” and “grey”, “camo” and “camouflage”. This introduced noise in the training data and distorted the training itself. Also, we had no choice but to guess if a particular picture from the test set was labeled by the organizer as either “camo” or “camouflage”.
Evaluation
The evaluation score function was the average error over all test pictures and relevant tasks. A score value of 0 meant that all the relevant tasks for all the test pictures were properly labeled, while a score of 1 implied that no relevant task for any picture was labeled correctly. A random sample submission provided by the organizer yielded a score greater than 0.99. Hence we knew that a good result couldn’t be achieved by accident and we would need a model that could actually learn how to solve the problem.
Our solution
A bunch of convolutional neural networks
Our solution consisted of about 20 convolutional neural networks. We used the following architectures in several variants:
All of them were initialized with weights pretrained on the ImageNet dataset. Our models also differed in terms of the data preprocessing (cropping, normalizing, resizing, switching of color channels) and augmentation applied (random flips, rotations, color perturbations from Krizhevsky’s AlexNet paper). All the neural networks were implemented using the PyTorch framework.
Choosing the training loss function
Which loss function to choose for the training stage was one of the major problems we faced. 576 unique pairs of task/label occurred in the training data so the outputs of our networks were 576-dimensional. On the other hand, typically only a few labels were matched to a picture’s tasks. Therefore the ground truth vector was very sparse – only a few of its 576 coordinates were nonzero – so we struggled to choose the right training loss function.
Assume that \((z_1,…,z_{576})in mathbb{R}^{576}\) is a model output and
[y_i=left{begin{array}{ll}1, & text{if task/label pair }itext{ matches the picture,}, & text{elsewhere,}end{array}right.quadtext{for } i=1,2,ldots,576.]
As this was a multi-label classification problem, choosing the popular crossentropy loss function:
\([sum_{i=1}^{576}-y_ilog p_i,quad text{where } p_i=frac{exp(z_i)}{sum_{j=1}^{576}exp(z_j)},]\)
wouldn’t be a good idea. This loss function tries to distinguish only one class from others.
Also, for the ‘element-wise binary crossentropy’ loss function:
\([sum_{i=1}^{576}-y_ilog q_i-(1-y_i)log(1-q_i),quad text{where } q_i=frac{1}{1+exp(-z_i)},]\)
the sparsity caused the models to end up constantly predicting no labels for any picture.
In our solution, we used the ‘weighted element-wise crossentropy’ given by:
\([sum_{i=1}^{576}-bigg(frac{576}{sum_{j=1}^{576}y_j}bigg)cdot y_ilog q_i-(1-y_i)log(1-q_i),quad text{where } q_i=frac{1}{1+exp(-z_i)}.]\)
This loss function focused the optimization on positive cases.
Ensembling
Predictions from particular networks were averaged, all with equal weights. Unfortunately, we didn’t have enough time to perform any more sophisticated ensembling techniques, like xgboost ensembling.
Other techniques tested
We also tested other approaches, though they proved less successful:
Training the triplet network and then training xgboost models on features extracted via embedding (different models for different tasks).
Mapping semantically equivalent labels like “gray” and “grey” to a common new label and remapping those to the original ones during postprocessing.
Neptune
We managed all of our experiments using Neptune, deepsense.ai’s Machine Learning Lab. Thanks to that, we were easily able to track the tuning of our models, compare them and recreate them.
Results
We achieved a score of 0.395, which means that we correctly predicted more than 60% of all the labels matched to relevant tasks.
We are pleased with this result, though we could have improved on it significantly if the competition had lasted longer than only one month.
Summary
Challenges like iMaterialist are a good opportunity to create product recognition models. The most important tools and tricks we used in this project were:
Playing with training loss functions. Choosing the proper training loss function was a real breakthrough as it boosted accuracy by over 20%.
A custom training-validation split. The organizer provided us with a ready-made training-validation split. However, we believed we could use more data for training so we prepared our own split with more training data while maintaining sufficient validation data.
Using the PyTorch framework instead of the more popular TensorFlow. TensorFlow doesn’t provide the official pretrained models repository, whereas PyTorch does. Hence working in PyTorch was more time-efficient. Moreover, we determined empirically that, much to our surprise, the same architectures yielded better results when implemented in PyTorch than in TensorFlow.
We hope you have enjoyed this post and if you have any questions, please don’t hesitate to ask!
https://deepsense.ai/wp-content/uploads/2019/02/how-to-create-a-product-recognition-solution.jpg3371140Krzysztof Dziedzichttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKrzysztof Dziedzic2017-08-22 13:57:172021-01-05 16:49:37How to create a product recognition solution
In this post, we provide an example of how to run a TensorFlow experiment on a Slurm cluster. Since TensorFlow doesn’t yet officially support this task, we developed a simple Python module for automating the configuration. It parses the environment variables set by Slurm and creates a TensorFlow cluster configuration based on them. We’re sharing this code along with a simple image recognition example on CIFAR-10. You can find it in our github repo.
But first, why do we even need distributed machine learning?
Distributed TensorFlow
When machine learning models are developed, training time is an important factor. Some experiments can take weeks or even months on a single machine. Shortening this time enables us to try out more approaches, test many similar models and use the best one. That’s why it’s useful to use multiple machines for faster training.
One of of TensorFlow’s strongest points is that it’s designed to support distributed computation. To use multiple nodes, you just have to create and start a tf.train.Server and use a tf.train.MonitoredTrainingSession.
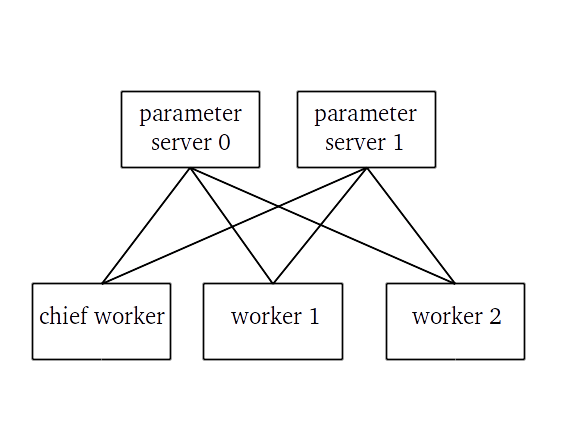
Between Graph Replication
In our example we’re going be using a concept called ‘Between Graph Replication’. If you’ve ever run MPI jobs or used the ‘fork’ system call, you’ll be familiar with it.
In Distributed TensorFlow, Between Graph Replication means that when several processes are being run on different machines, each process (worker) runs the same code and constructs the same TensorFlow computational graph. However, each worker uses a discriminator (the worker’s I.D., for example) to execute instructions differently from the rest (e.g. process different batches of the training data).
This information is also used to make processes on some machines work as ‘Parameter Servers’. These jobs don’t actually run any computations – they’re only responsible for storing the weights of the model and sending them over the network to other processes.
Connections between tasks in a distributed TensorFlow job with 3 workers and 2 parameter servers.
Apart from the worker I.D. and the job type (normal worker or parameter server), TensorFlow also needs to know the network addresses of other workers performing the computations. All this information should be passed as configuration for the tf.train.Server. However, keeping track of it all in addition to starting multiple processes on multiple machines with different parameters can be really tedious. That’s why we have cluster managers, such as Slurm.
Slurm
Slurm is a workload manager for Linux used by many of the world’s fastest supercomputers. It provides the means for running computational jobs on multiple nodes, queuing the jobs until sufficient resources are available and monitoring jobs that have been submitted. For more information about Slurm, you can read the official documentation here.
When running a Slurm job you can discover other nodes taking part by examining environment variables:
SLURMD_NODENAME – name of the current node
SLURM_JOB_NODELIST – number of nodes the job is using
SLURM_JOB_NUM_NODES – list of all nodes allocated to the job
Our python module parses these variables to make using distributed TensorFlow easier. With the tf_config_from_slurm function you can automate this process. Let’s see how it can be used to train a simple CIFAR-10 model on a CPU Slurm cluster.
Distributed TensorFlow on Slurm
In this section we’re going to show you how to run TensorFlow experiments on Slurm. A complete example of training a convolutional neural network on the CIFAR-10 dataset can be found in our github repo, so you might want to take a look at it. Here we’ll just examine the most interesting parts.
Most of the code responsible for training the model comes from this TensorFlow tutorial. The modifications allow the code to be run in a distributed setting on the CIFAR-10 dataset. Let’s examine the changes one by one.
Starting the Server
import tensorflow as tf
from tensorflow_on_slurm import tf_config_from_slurm
cluster, my_job_name, my_task_index = tf_config_from_slurm(ps_number=1)
cluster_spec = tf.train.ClusterSpec(cluster)
server = tf.train.Server(server_or_cluster_def=cluster_spec,
job_name=my_job_name, task_index=my_task_index)
if my_job_name == 'ps':
server.join()
sys.exit(0)
Here we import our Slurm helper module and use it to create and start the tf.train.Server. The tf_config_from_slurm function returns the cluster spec necessary to create the server along with the task name and task index of the current job. The ‘ps_number’ parameter specifies how many parameter servers to set up (we use 1). All other nodes will be working as normal workers and everything gets passed to the tf.train.Server constructor.
Afterwards we immediately check whether the current job is a parameter server. Since all the work in a parameter server (ps) job is handled by the tf.train.Server (which is running in a separate thread), we can just call server.join() and not execute the rest of the script.
Placing the Variables on a parameter server
def weight_variable(shape):
with tf.device("/job:ps/task:0"):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
with tf.device("/job:ps/task:0"):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
These two functions are used when defining the model parameters. Note the “with tf.device(“/job:ps/task:0”)” statements telling TensorFlow that the variables should be placed on the parameter server, thus enabling them to be shared between the workers. The “0” index denotes the I.D. of the parameter server used to store the variable. Here we’re only using one server, so all the variables are placed on task “0”.
Instead of using the usual AdamOptimizer, we’re wrapping it with the SyncReplicasOptimizer. This enables us to prevent the application of stale gradients. In distributed training, the network communication may introduce communication delays which make it harder to train the model.
In distributed settings we’re using the tf.train.MonitoredTrainingSession instead of the usual tf.Session. This ensures the variables are properly initialized. It also allows you to restore a previously saved model and control how the summaries and checkpoints are written to disk.
Training
During the training, we split the batches between workers so everyone has their own unique batch subset to train on:
for i in range(max_epoch):
batch = mnist.train.next_batch(batch_size)
if i % len(cluster['worker']) != my_task_index:
continue
_, train_accuracy, xentropy = sess.run([train_step, accuracy, cross_entropy],
feed_dict={x: batch[0], y_: batch[1],
keep_prob: 0.5})
Summary
We hope this example was helpful in your experiments with TensorFlow on Slurm clusters. If you’d like to reproduce it or use our Slurm helper module in your experiments, don’t hesitate to clone our github repo.
https://deepsense.ai/wp-content/uploads/2019/02/tensorflow-on-slurm-clusters.png3371140Tomasz Grelhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngTomasz Grel2017-06-26 09:09:382021-02-23 11:19:35Running distributed TensorFlow on Slurm clusters
It all started with mathematics – rigorous thinking, science, technology. Today’s world is maths‑driven. Despite recent advances in deep learning, the way mathematics is done today is still much the same as it was 100 years ago. Isn’t it time for a change?
Introduction
Mathematics is at the core of science and technology. However the growing amount of mathematical research makes it impossible for non‑experts to fully use the developments made in pure mathematics. Research has become more complicated and more interdependent.
Moreover it is often impossible to verify correctness for non‑experts – knowledge is accepted as knowledge by a small group of experts (e.g. the problem with accepting Mochizuki’s proof of abc‑conjecture – it is not understandable for other experts).
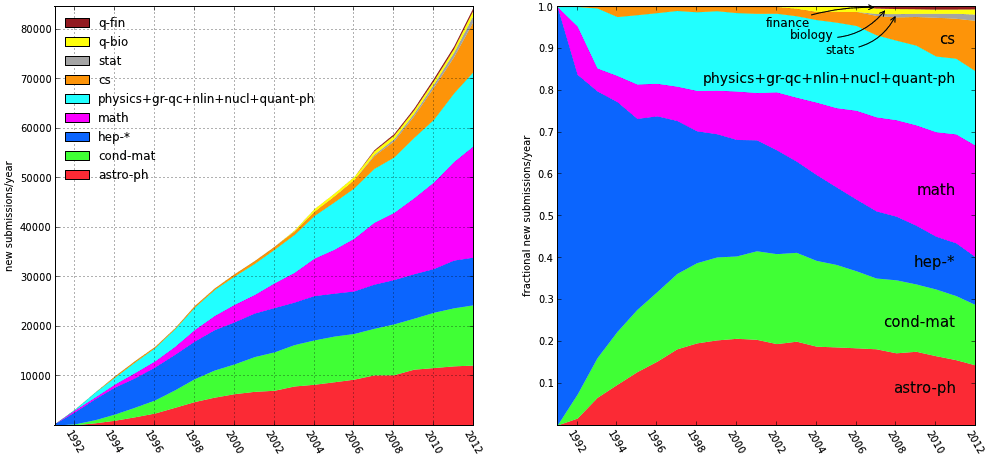
Fig. 1: The graph on the left shows the growing number of submissions to arXiv – an Internet repository for scientific research. In 2012, mathematics accounted for approx. 20,000 submissions annually.
Automated reasoning
To address the issue mentioned above, researchers try to automate or semi‑automate:
Producing mathematics
Verifying existing mathematics
This domain of science is called automatic theorem proving and is a part of automated reasoning. The current approach to automation is:
Take a mathematical work (e.g. Feit‑Thompson theorem or proof of Kepler’s conjecture)
Rewrite it in Coq, Mizar or another Interactive Theorem Prover (language/program which understands logic behind mathematics and is able to check its correctness)
Verify
The downside to this approach is that it is a purely manual work and quite a tedious process! One has to fill in the gaps as the human way of writing mathematics is different than what Coq/Mizar accepts. Moreover mathematical work is based on previous works. One needs to lay down foundations each time at least to some extent (but have a look at e.g. Mizar Math Library).
Once in Coq/Mizar, there is a growing number of methods to prove new theorems:
Hammers and tactics (methods for automatic reasoning over large libraries)
Machine learning and deep learning
Here we concentrate on the last method of automated reasoning. Firstly, in order to use the power of machine learning and deep learning, one needs more data. Moreover to keep up with current mathematical research we need to translate LaTeX into Coq/Mizar much faster.
Building a dictionary
We need to automate translation of human‑written mathematical works in LaTeX to Coq/Mizar. We view it as an NLP problem of creating a dictionary between two languages. How can we build such a dictionary? We could build upon existing syntactic parsers (e.g. TensorFlow’s SyntaxNet) and enhance them with Types and variables, which we explain in an example:
Consider the sentence “Let $G$ be a group” . Then “G” is a variable of Type “group”.
Once we have such a dictionary with at least some basic accuracy we can use it to translate LaTeX into Coq/Mizar sentence by sentence. Nevertheless we still need a good source of mathematics! Here is what we propose in the DeepAlgebra program:
Algebraic geometry is one of the pillars of modern mathematical research, which is rapidly developing and has a solid foundation (Grothendieck’s EGA/SGA, The Stacks Project). It is “abstract” hence easier to verify for computers than analytical parts of mathematics.
The Stacks Project is an open multi‑collaboration on foundations of algebraic geometry starting from scratch (category theory and algebra) up to the current research. It has a well‑organized structure (an easy‑to‑manage dependency graph) and is verified thoroughly for correctness.
The Stacks Project now consists of:
547,156 lines of code
16,738 tags (57 inactive tags)
2,691 sections
99 chapters
5,712 pages
162 slogans
Moreover it has an API to query!
Statements (also in LaTeX)
Data for graphs
Below we present a few screenshots.
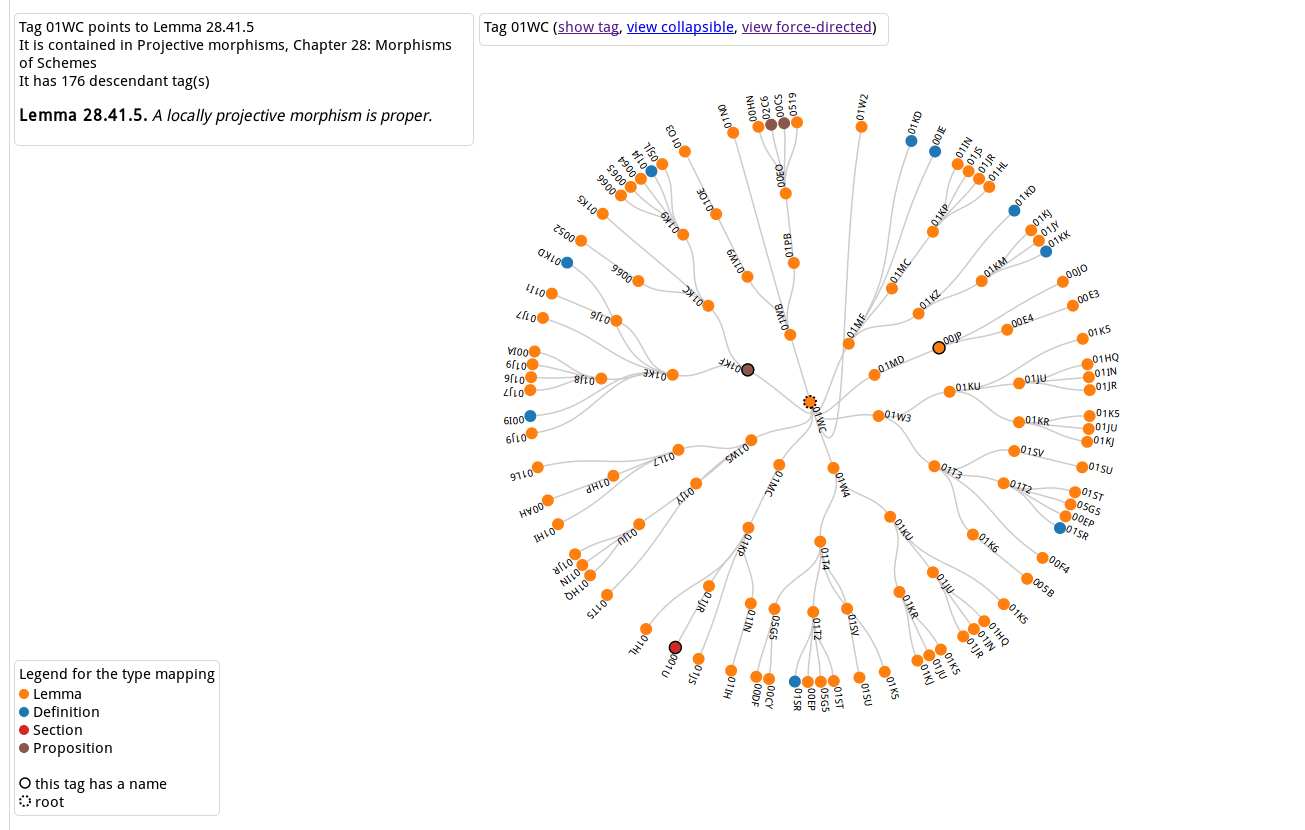
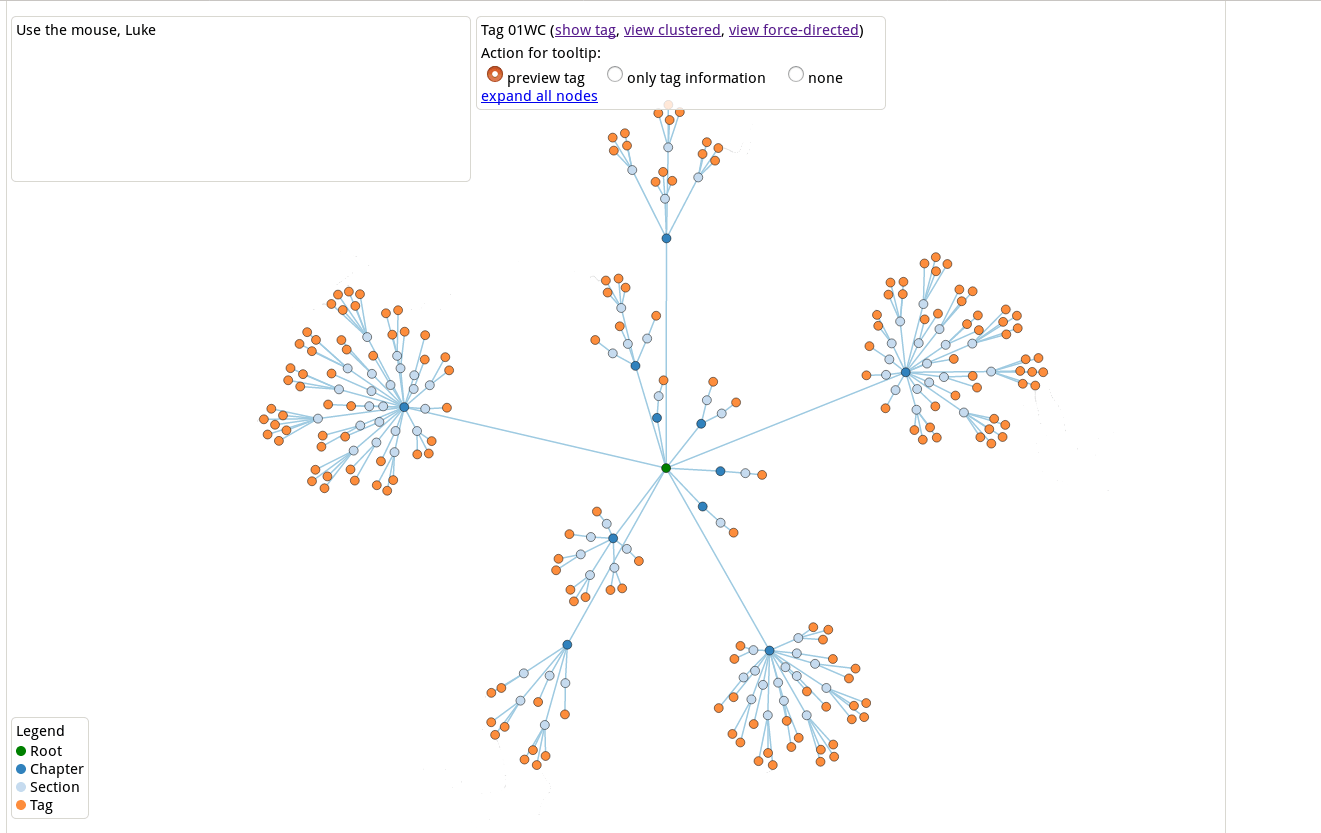
Fig. 2: One of the lemmas in the Stacks Project. Each lemma has a unique tag (here 01WC), which never changes, even though the number of the lemma may change. Each lemma has a proof and we can access its dependency graphs:
Figs. 3 and 4: Two dependency graphs for Lemma 01WC, which show the structure of the proof together with all the lemmas, propositions and definitions which were used along the way.
Conclusion
Summing up, we propose to treat the Stacks Project as a source of data for NLP research and eventual translation into one of the Interactive Theorem Provers. The first step in the DeepAlgebra program is to build a dictionary (syntactic parser with Types/variables) and then test it on the Stacks Project. This way we would build an “ontology” of algebraic geometry. If that works out, we can verify, modify and test it on arXiv (Algebraic Geometry submissions). We will report on our progress in automated reasoning in future texts.