Museum Treasures – AI at the National Museum in Warsaw
Object recognition is common for street and satellite photos, diagram analysis and text recognition. After the DS team, including several deepsense.ai data scientists, took first place in the National Museum in Warsaw’s HackArt hackathon, designing a “Museum Treasures” game, the technique may soon be used to popularize art and culture, too.
In May 2018, the National Museum in Warsaw organized its HackArt hackathon. The task was to combine seemingly disparate fields: museology, art history and artificial intelligence. The goal of HackArt was to create tools: AI-based applications, bots and plug-ins that could help solve challenges the museum set.
The idea
Our focus was on the target group of parents and children, and on answering the questions of:
- How to encourage families to visit the museum
- How to make the visit interesting for children
- How to build interest, among children and their parents, in the museum’s resources.
Somewhere along the way the idea of scavenger hunts came up, along with augmented reality games of record-breaking popularity, including Ingress and PokemonGO. Ingress players visiting a city fight for portals to another world. In PokemonGo, players look for pokemon in the least expected places.
That’s how the idea for the “Museum Treasures” game came about: A game in which children and parents get a map with fragments of paintings belonging to particular categories (animals or trees, for example). Armed with their maps, they then find the paintings that contain the fragments. The game’s formula was simple, but we wanted it also to be individualized and constantly changing. It was essential that parents with children be able to play it multiple times and that families searching for the treasures in the museum follow a number of “paths”. How could we go about doing that? The solution ended up using AI.
The execution
Artificial intelligence allows for the automation of many activities, especially tedious and time-consuming ones. Object recognition in street and satellite photos, diagram analysis, text recognition and analysis – there are countless applications. Now the automatic recognition of what can be found in paintings hanging in a museum can be added to the list.
Everyone participating in the hackathon had access to 200 photos of museum pieces. Our solution was to create a database of specific fragments of images – animals, trees, houses, feet, you name it – which could be used to create the various paths of a treasure hunt by category. The database would be extensive, and elements from new exhibitions could be added to it once they were digitalized. The only limitation in selecting the fragments to be used was in this case the set of elements which the object detection model we intended to use could recognize.
Image analysis
Take, for example, the image of Antoni Brodowski “Parys in a hat”. How would the object detection model work in this case?

In the image, we will recognize, for example, the head, the hand, the cap and the human, together with the areas where these elements appear (coordinates x, y of the rectangle) and the probability (the certainty with which the model found the element, p). A dictionary of fragments is thus created:
{category_1: image_id, detected fragment, (x, y), probability p}

Object detection models (among many other kinds of models) can be found in the open-source code repositories on GitHub. Depending on your needs and situation, a model can be taught from scratch using the data available, or, alternatively, pre-trained, ready-made models can be used. We chose the latter approach, because training a model requires a set of photos and labels. The labels in this case would define the category of elements and coordinates of their occurrence for each photo. Because we lacked such labels, we went with an object detection model from the Tensorflow Models (Google Vision API) repository, which allows quick detection and searches on 545 categories.
The code that enables objects to be found in images from a set is located on the stared/hackart-you-in-artwork repository. Below you will see a fragment that likewise makes it possible to detect objects in an image, and to then be saved as a json file. The code for each photo (from the list of photos to be processed) launches a neural network that recognizes the objects in the picture. As a result, we receive thousands of frame proposals along with the class and probability of the occurrence of this class in the area in question. We rejected results that were too uncertain, while adding the remaining ones to the dictionary to use in further stages of working with data. The fragment of code pictured here displays our results on the image and saves them to files, thanks to which we can visually verify the results obtained.
results = dict()
for image_path in tqdm(list(TEST_IMAGE_PATHS)):
base_name = image_path.split('/')[-1][:-4]
image = Image.open(image_path)
image_np = load_image_into_numpy_array(image)
image_np_expanded = np.expand_dims(image_np, axis=0)
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores,
detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
image_np = cv2.cvtColor(image_np, cv2.COLOR_BGR2RGB)
objects = []
for s, c, b in zip(scores[0], classes[0], boxes[0]):
if s > THRESH:
b = list(b)
objects.append({"prob": s,
"name": str(category_index[c]['name']),
"xmin": b[0], "ymin": b[1],
"xmax": b[2], "ymax": b[3]})
results[image_path.split('/')[-1]] = objects
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
min_score_thresh=THRESH,
use_normalized_coordinates=True,
line_thickness=8)
cv2.imwrite('%s.jpg' % base_name, image_np)
counter = counter+1
print(results)
with open('oidv3.json', 'w') as f:
json.dump(results, f)
Source: https://github.com/stared/hackart-you-in-artwork/blob/master/aux/scripts_karol/evaluate_on_images.py
Outline of how the game works
Preparing the dictionary of fragments and their categories was only part of the task. At the same time, the work of developing the application demo awaited us. We had to focus on basic functionalities to be able to build the skeleton of the solution:
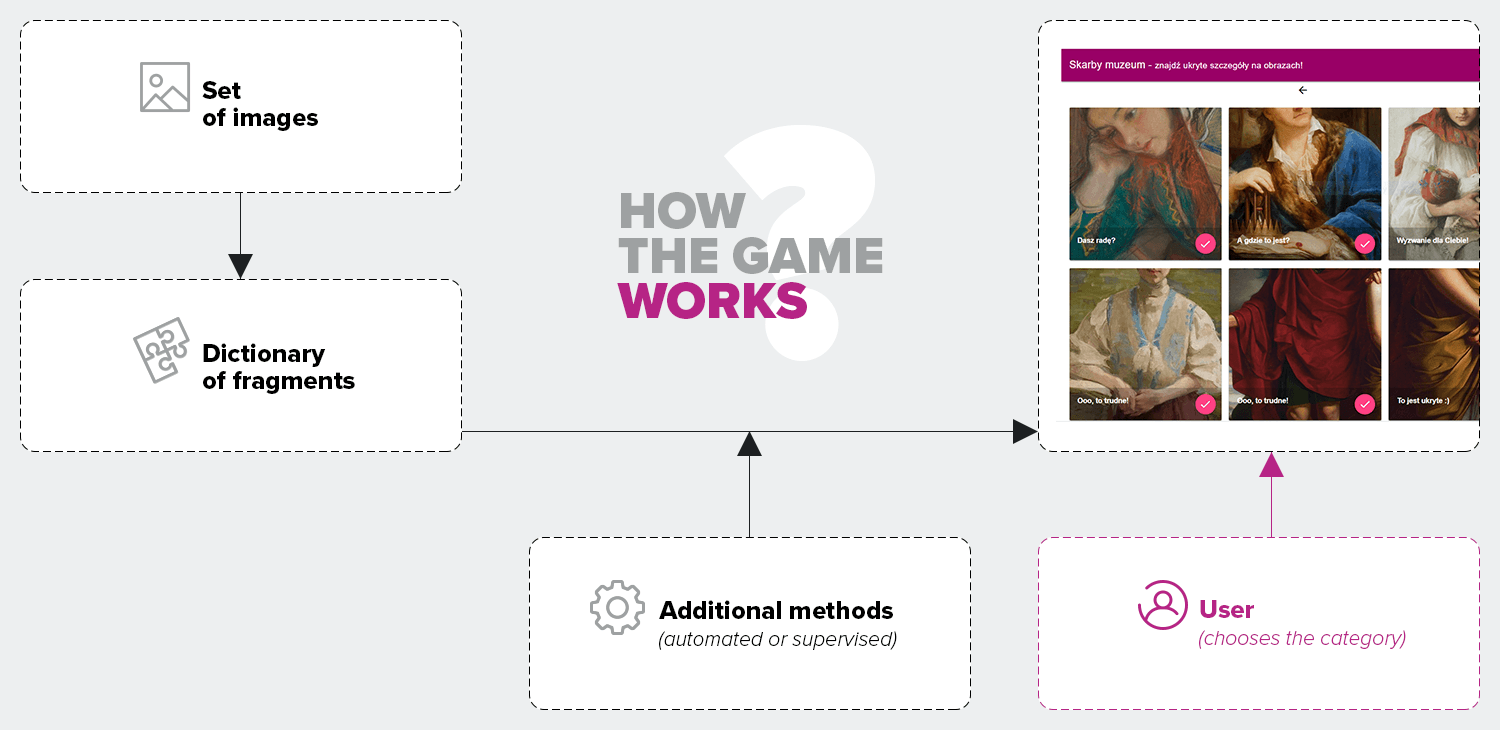
The application was intended to work automatically. After entering a new set of photos, a dictionary of categories was created (with additional filters to improve the quality of the items received), from which the user is then presented with 5 categories to choose from. During the hackathon we had a limited set of photos (→ lower credibility of automatically generated elements) and time constraints, so we supervised some of the tasks. For example, we checked the quality of the elements generated and merged several categories into one: cat, dog, fish, … → animals.
We created a web application and used Vue.js to create it. We assumed the following about the “Museum Treasures” game:
- It could be played in an “analog” version: downloading a pdf with fragments of images and information about which room they could be found in → a designated “path” through the rooms; in this case, the player doesn’t need to use a smartphone or tablet, which may be important for parents and school trips.
- it could also be played electronically: using a smartphone or tablet, with analogous information as above.
In both cases, the user first selects the category, and then receives a list of fragments (unique, random set) that must be found in the paintings.
During the hackathon we were able to create the basic version of the application, which allows users to select categories and shows the relevant fragments. We did not have time to hammer out map- and pdf-related functionalities.

Nor, during the event, did we have metadata about the location of the images from the collection, though these data can be added at a later stage of the work. The result of our efforts was a demo version.
To seehow the app works, check out the video below:
Further development ideas
In its basic form, “Museum Treasures” has players look for images, but in further development verification, rewarding and gamification could be added to enrich the experience. Defining the rules of the game, goals and motivation was very important and involved determining the age of the players. The challenges that await a five-year-old will differ from those 12-year-olds will take on. We believed the game could also be interesting for adults, as paths could likewise be created for mature users. We had several ideas for introducing these elements and developing them further. You can read a few of them below.
| Verification | |
| Metadata | To confirm that a painting has been found, the player enters information about the painter, the year the work was done, etc. These type of data can easily be entered into the dictionary, and questions can be generated based on them. |
| photos | A more advanced form of verification involves requiring the participant to take a picture – an image or note down information. The application could be enriched with a module comparing the image photographed with the fragment source. This solution is much more technically complex. There may also be occasions when photography is of poor quality and can’t be verified. |
| Clues | |
| metadata | Hints about the painter |
| Generating descriptions with AI | Using algorithms to generate photo captions defining the context of what is found in the picture. This could be an interesting extra, though such captions don’t always work properly as clues. |
The prize for correctly retrieving the images could be stickers or other small gadgets and a badge that could be awarded on social media.
The game can also be developed for group work. Ultimately, schools could use it. One of the ideas also assumes gamification:
- two groups follow separate paths, with their times compared at the end,
- two groups follow paths that end up at the same place, thus allowing the players to meet at the end of the game (and talk about who came in first).
The games could also be offered to adults: Races based on categories such as “Lips, lips” or “Buttocks over the centuries” are often very popular among adults.
Future plans
We’re currently working on getting our pilot solution up and running. It will be based on one of the museum’s exhibits – a collection of 19th century paintings. We would like to create a basic version of the game, which would then be tested for its level of difficulty, among other factors.