Since the days of the coal-powered industrial revolution, manufacturing has become machine-dependent. As the fourth industrial revolution approaches, factories can harness the power of machine learning to reduce maintenance costs.
Visual inspection, where the output is entirely based on the inspector’s knowledge and intuition
2.
Instrument inspection, where conclusions are a combination of the specialist’s experience and the instrument’s read-outs
3.
Real-time condition monitoring that is based on constant monitoring with IoT and alerts triggered by predefined conditions
4.
AI-based predictive analytics, where the analysis is performed by self-learning algorithms that continuously tweak themselves to the changing conditions
As the study indicates, a good number of the companies surveyed by PwC (36%) are now on level 2 while more than a quarter (27%) are on level 1. Only 22% had reached level 3 and 11% level 4, which is basically level 3 on machine learning steroids. The PwC report states that only 3% use no predictive maintenance at all.
Staying on track
According to the PwC data, the rail sector is the most advanced sector of those surveyed with 42% of companies at level 4, compared to 11% overall.
One of the most prominent examples is Infrabel, the state-owned Belgian company, which owns, builds, upgrades and operates a railway network which it makes available to privately-owned transportation companies. The company spends more than a billion euro annually to maintain and develop its infrastructure, which contains over 3 600 kilometers of railway and some 12 000 civil infrastructure works like crossings, bridges, and tunnels. The network is used by 4 200 trains every day, transporting both cargo and passengers.
According to the PwC data, the rail sector is the most advanced sector of those surveyed with 42% of companies at level 4, compared to 11% overall.
The company faces both technical and structural challenges. Among them is its aging technical staff, which is shrinking.
At the same time, the density of railroad traffic is increasing – the number of daily passengers has increased by 50% since 2000, reaching 800 000. What’s more, the growing popularity of high-speed trains is exerting ever greater tension on the rails and other infrastructure.
Both the amount and the nature of the data collected render it impossible for a human to analyze, but a machine-learning powered AI solution handles it with ease. The devices are able to gather data in ultrasonic and vibration sensors and analyze them in real time. Contrary to experience-based analytics, using the devices requires little-to-no training and can be done on the go.
Endless possibilities
With the power of machine learning enlisted, handling the tremendous amounts of data generated by the sensors in modern factories becomes a much easier task. It allows the company to detect failures before they paralyze the company, thus saving time and money. What’s more, the data that is gathered can be used to further optimize the company’s performance, including by searching for bottlenecks and managing workflows.
Everything you need to know about demand forecasting – from the purpose and techniques to the goals and pitfalls to avoid.
Essential since the dawn of commerce and business, demand forecasting enters a new era of big-data rocket fuel.
What is demand forecasting?
The term couldn’t be clearer: demand forecasting forecasts demand. The process of predicting the future involves processing historical data to estimate the demand for a product. An accurate forecast can bring significant improvements to supply chain management, profit margins, cash flow and risk assessment.
What is the purpose of demand forecasting?
Demand forecasting is done to optimize processes, reduce costs and avoid losses caused by freezing up cash in stock or being unable to process orders due to being out of stock. In an ideal world, the company would be able to satisfy demand without overstocking.
Demand forecasting techniques
Demand forecasting is an essential component of every form of commerce, be it retail, wholesale, online, offline or multichannel. It has been present since the very dawn of civilization when intuition and experience were used to forecast demand.
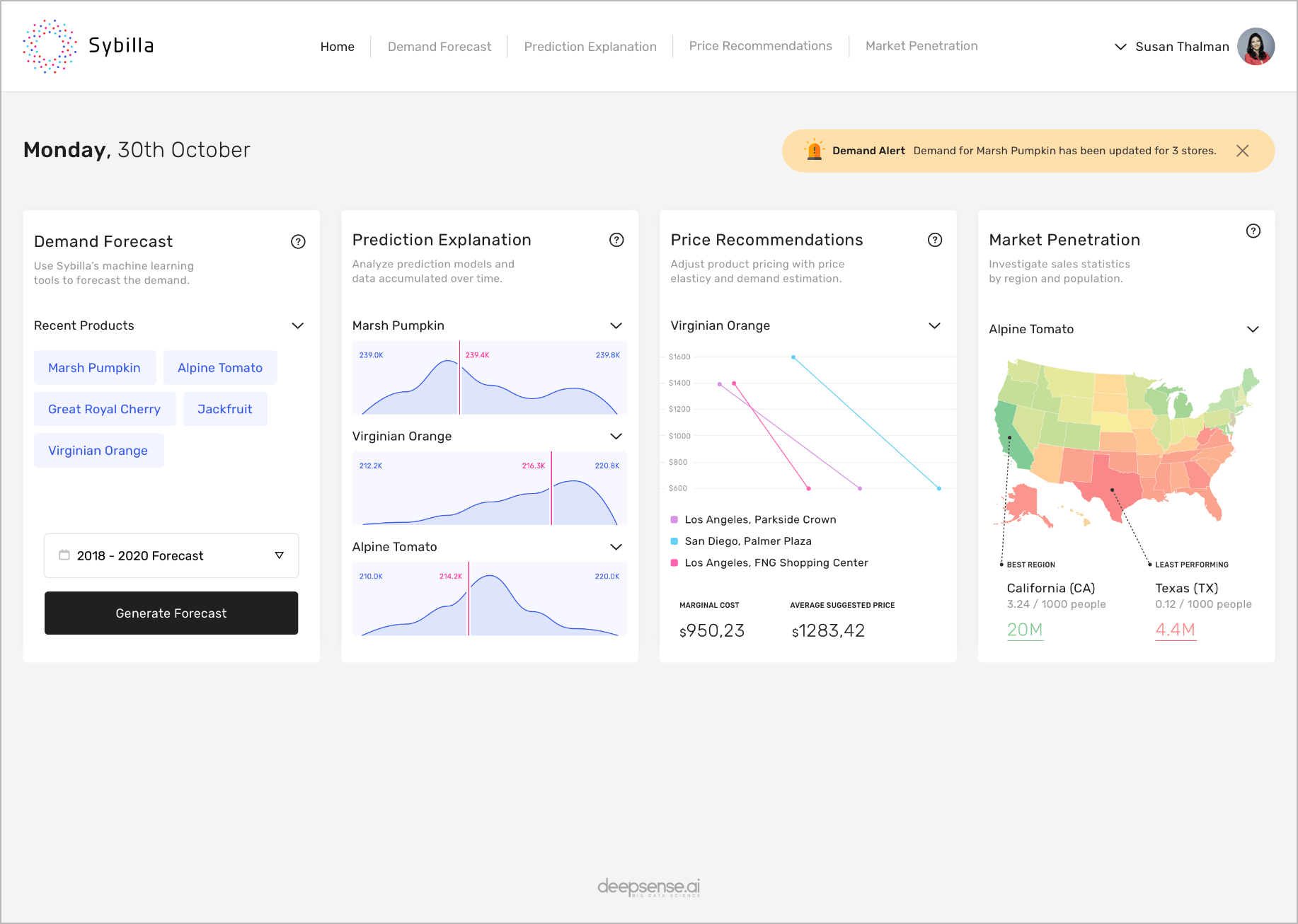
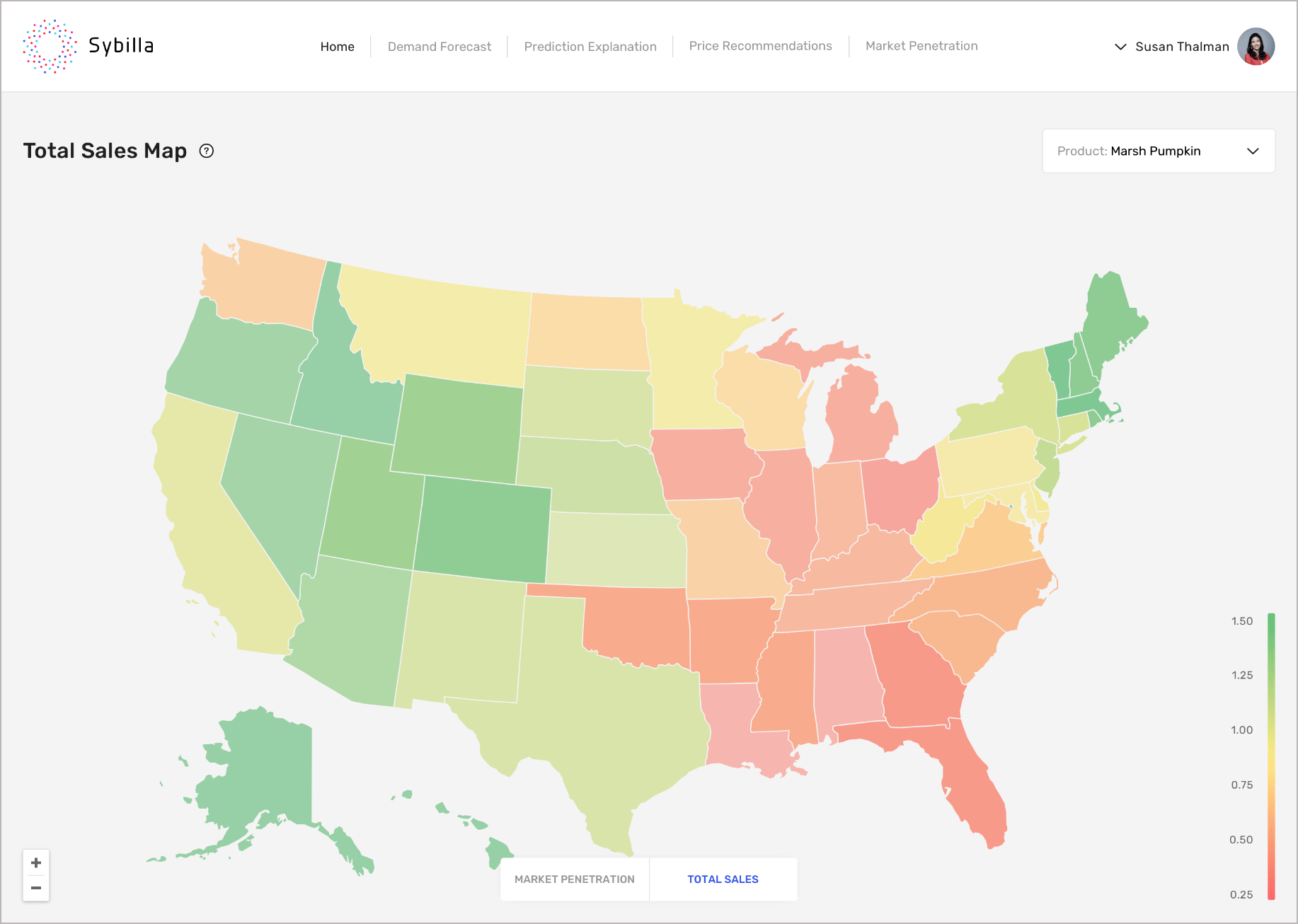
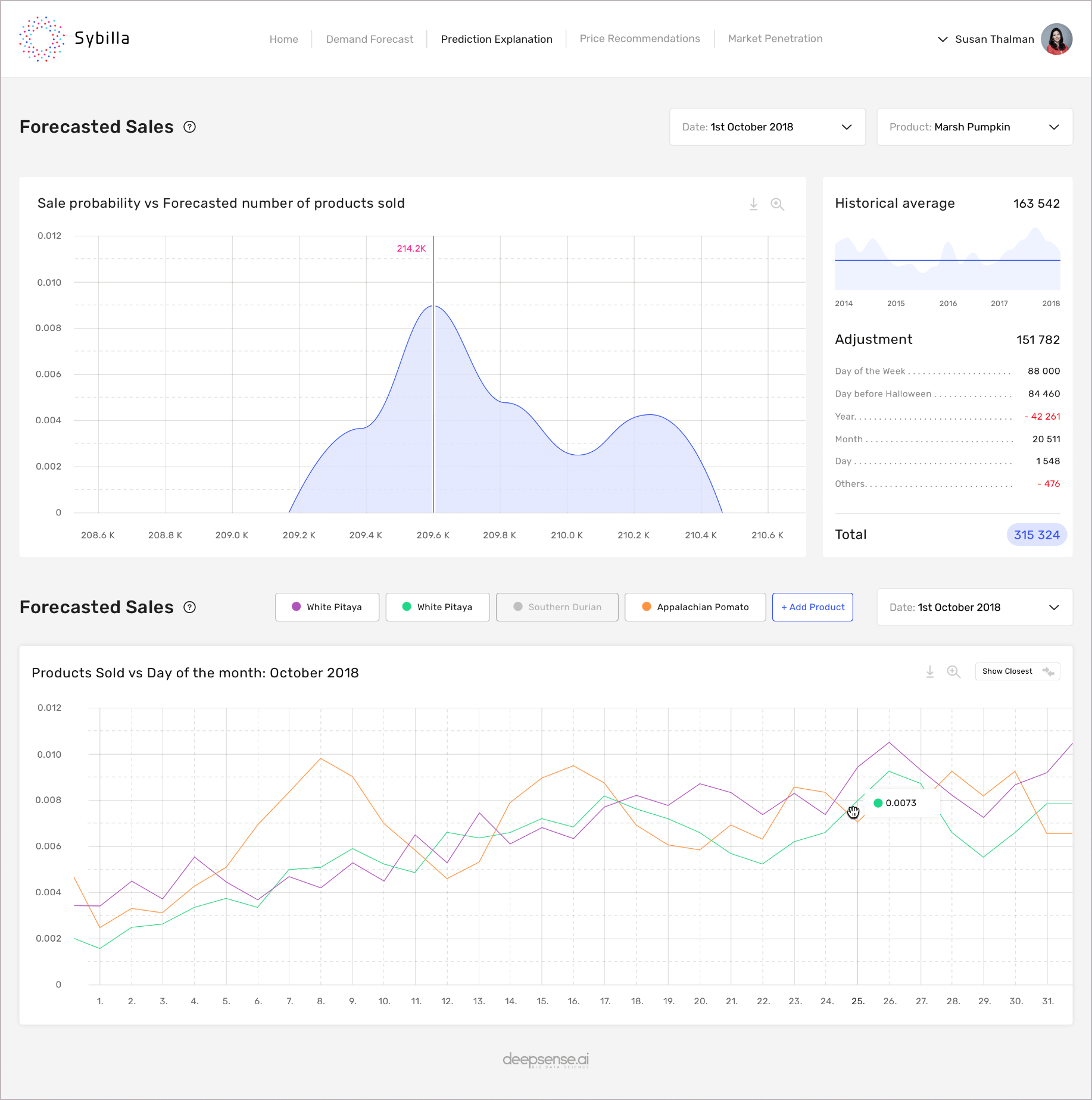
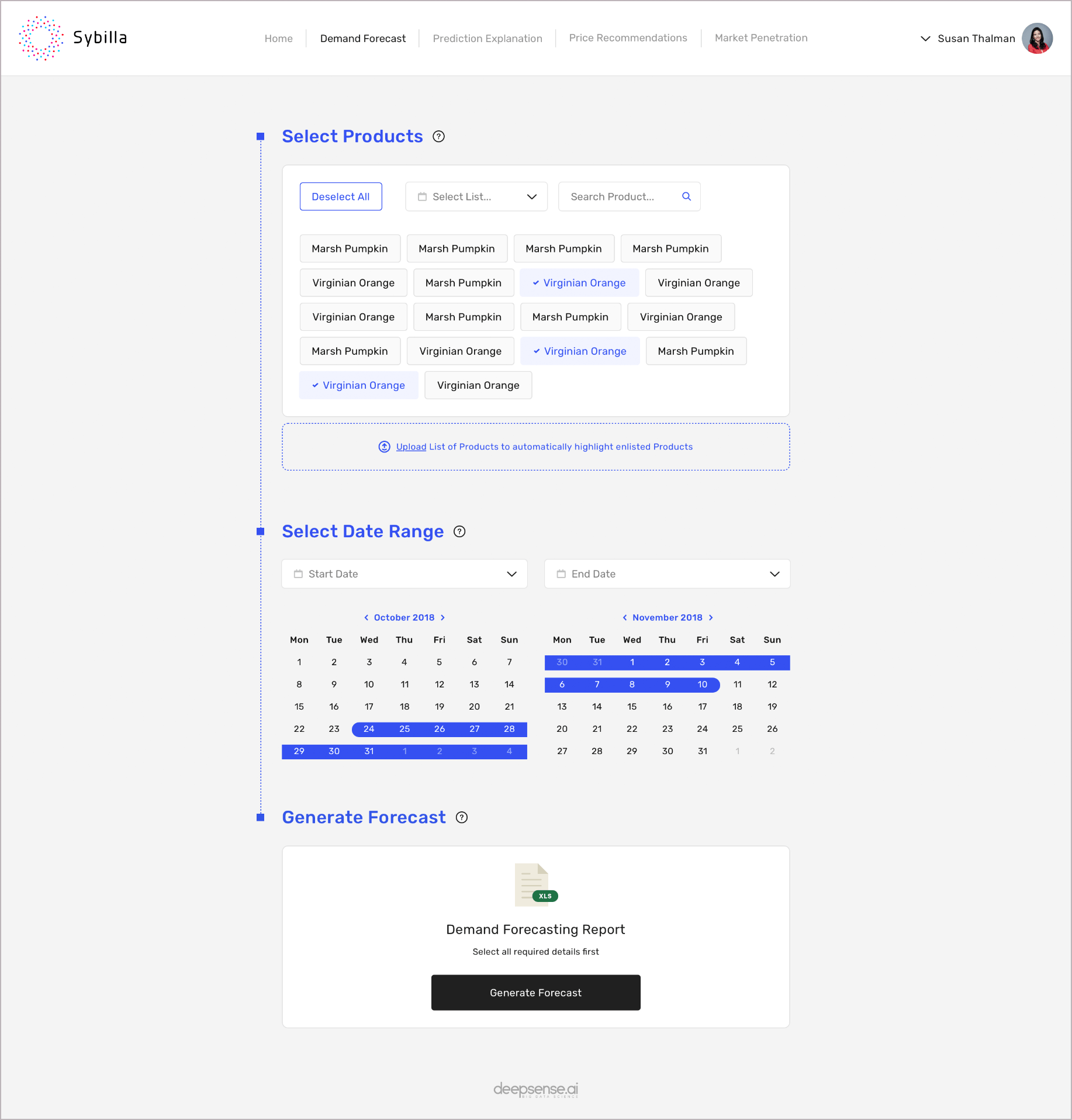
Sybilla – deepsense.ai’s demand forecasting tool
More recent techniques combine intuition with historical data. Modern merchants can dig into their data in a search for trends and patterns. At the pinnacle of these techniques, are demand forecasting machine learning models, including gradient boosting and neural networks, which are currently the most popular ones and outperform classic statistics-based methods.
The basis of more recent demand forecasting techniques is historical data from transactions. These are data that sellers collect and store for fiscal and legal reasons. Because they are also searchable, these data are the easiest to use.
Sybilla – deepsense.ai’s demand forecasting tool
How to choose the right demand forecasting method – indicators
As always, selecting the right technique depends on various factors, including:
The scale of operations – the larger the scale, the more challenging processing the data becomes.
The organization’s readiness – even the large companies can operate (efficiency aside) on fragmented and messy databases, so the technological and organizational readiness to apply more sophisticated demand forecasting techniques is another challenge.
The product – it is easier to forecast demand for an existing product than for a newly introduced one. When considering the latter, it is crucial to forming a set of assumptions to work on. Owning as much information about the product as possible is the first step, as it allows the company to spot the similarities between particular goods and search for correlations in the buying patterns. Spotting an accessory that is frequently bought along with the main product is one example.
How AI-based demand forecasting can help a business
Demand forecasting and following sales forecasting is crucial to shaping a company’s logistics policy and preparing it for the immediate future. Among the main advantages of demand forecasting are:
Loss reduction – any demand that was not fulfilled should be considered a loss. Moreover, the company freezes its cash in stock, thus reducing liquidity.
Supply chain optimization – behind every shop there is an elaborate logistics chain that generates costs and needs to be managed. The bigger the organization, the more sophisticated and complicated its inventory management must be. When demand is forecast precisely, managing and estimating costs is easier.
Increased customer satisfaction – there is no bigger disappointment for consumers than going to the store to buy something only to return empty-handed. For a business, the worst-case scenario is for said consumers to swing over to the competition to make their purchase there. Companies reduce the risk of running out of stock–and losing customers–by making more accurate predictions.
Smarter workforce management – hiring temporary staff to support a demand peak is a smart way for a business to ensure it is delivering a proper level of service.
Better marketing and sales management – depending on the upcoming demand for particular goods, sales and marketing teams can shift their efforts to support cross- and upselling of complementary products,
Supporting expert knowledge – models can be designed to build predictions for every single product, regardless of how many there are. In small businesses, humans handle all predictions, but when the scale of the business and the number of goods rises, this becomes impossible. Machine learning models extend are proficient at big data processing.
How to start demand forecasting – a short guide
Building a demand forecasting tool or solution requires, first and foremost, data to be gathered.
While the data will eventually need to be organized, simply procuring it is a good first step. It is easier to structure and organize data and make them actionable than to collect enough data fast. The situation is much easier when the company employs an ERP or CRM system, or some other form of automation, in their daily work. Such systems can significantly ease the data gathering process and automate the structuring.
Sybilla – deepsense.ai’s demand forecasting tool
The next step is building testing scenarios that allow the company to test various approaches and their impact on business efficiency. The first solution is usually a simple one, and is a good benchmark for solutions to come. Every next iteration should be tested to see if it is performing better than the previous one.
Historical data is usually everything one needs to launch a demand forecasting project, and obviously, there are significantly less data on the future. But sometimes it is available, for example:
Short-term weather forecasts – the information about upcoming shifts in weather can be crucial in many businesses, including HoReCa and retail. It is quite intuitive to cross-sell sunglasses or ice cream on sunny days.
The calendar – Black Friday is a day like no other. The same goes for the upcoming holiday season or other events that are tied to a given date.
Sources of data that originate from outside the company make predictions even more accurate and provide better support for making business decisions.
Common pitfalls to avoid when building a demand forecasting solution
There are numerous pitfalls to avoid when building a demand forecasting solution. The most common of them include:
The data should be connected with the marketing and ads history – a successful promotion results in a significant change in data, so having information about why it was a success makes predictions more accurate. If machine learning was used to make the predictions, the model could have misattributed the changes and made false predictions based on wrong assumptions.
New products with no history – when new products are introduced, demand must still be estimated, but without the help of historical data. The good news here is that great strides have been made in this area, and techniques such as product DNA can help a company uncover similar products its past/current portfolio. Having data on similar products can boost the accuracy of prediction for new products.
The inability to predict the weather – weather drives demand in numerous contexts and product areas and can sometimes be even more important than the price of a product itself! (yes, classical economists would be very upset). The good news is that even if you are unable to predict the weather, you can still use it in your model to explain historical variations in demand.
Lacking information about changes – In an effort to support both short- and long-term goals, companies constantly change their offering and websites. When the information about changes is not annotated in the data, the model encounters sudden dwindles and shifts in demand with apparently no reason. In the reality, it is usually a minor issue like changing the inventory or removing a section from website.
Inconsistent portfolio information – predictions can be done only if the data set is consistent. If any of the goods in a portfolio have undergone a name or ID change, it must be noted in order not to confuse the system or miss out on a valuable insight.
Overfitting the model – a vicious problem in data science. A model is so good at working on the training dataset that it becomes inflexible and produces worse predictions when new data is delivered. Avoiding overfitting is down to the data scientists.
Inflexible logistics chain – the more flexible the logistics process is, the better and more accurate the predictions will be. Even the best demand forecasting model is useless when the company’s logistics is a fixed process that allows no space for changes.
Sybilla – deepsense.ai’s demand forecasting tool
AI in demand forecasting: final thoughts
Demand and sales forecasting is a crucial part of any business. Traditionally it has been done by experts, based on know-how honed through experience. With the power of machine learning it is now possible to combine the astonishing scale of big data with the precision and cunning of a machine-learning model. While the business community must remain aware of the multiple pitfalls it will face when employing machine learning to predict demand, there is no doubt that it will endow demand forecasting with awesome power and flexibility.
Ready to harness the full potential of AI for your business? Opt for our AI consulting services, and let our experts guide you.
https://deepsense.ai/wp-content/uploads/2019/05/A-comprehensive-guide-to-demand-forecasting.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-05-28 11:24:422023-10-12 15:18:53A comprehensive guide to demand forecasting
The April edition of AI Monthly Digest looks at how AI is used in entertainment, for both research and commercial purposes.
After its recent shift from non-profit to for-profit, OpenAI continues to build a significant presence in the world of AI research. It is involved in two of five stories chosen as April’s most significant.
AI Music – spot the discord…
While machine learning algorithms are getting increasingly better at delivering convincing text or gaining superior accuracy in image recognition, machines struggle to understand the complicated patterns behind the music. In its most basic form, the music is built upon repetitive motifs that return based on sections of various length – it may be a recurrent part of one song or a leading theme of an entire movie, opera or computer game.
Machine learning-driven composing is comparable to natural language processing – the short parts are done well but the computer gets lost when it comes to keeping the integrity of the longer ones. April brought us two interesting stories regarding different approaches to ML-driven composition.
OpenAI developed MuseNet, a neural network that produces music in a few different styles. Machine learning algorithms were used to analyze the style of various classical composers, including Chopin, Bach, Beethoven and Rachmaninoff. The model was further fed rock songs by Queen, Green Day and Nine Inch Nails and pop music by Madonna, Adele and Ricky Martin, to name a few. The model learned to mimic the style of a particular artist and infuse it with twists. If the user wants to spice up the Moonlight Sonata with a drum, the road is open.
OpenAI has rolled out an early version of the model and it performs better when the user is trying to produce a consistent piece of music, rather than pair up a disparate coupling of Chopin and Nine Inch Nails-style synthesizers.
OpenAI claims that music is a great tool with which to evaluate a model’s ability to maintain long-term consistency, mainly thanks to how easy it is to spot discord.
…or embrace it
While OpenAI embraces harmony in music, Dadabots has taken the opposite tack. Developed by Cj Carr and Zack Zukowski, Databots model imitates rock, particularly metal bands. The team has put their model on YouTube to deliver technical death metal as an endless live stream – the Relentless Doppelganger.
While it is increasingly common to find AI-generated music on Bandcamp, putting a 24/7 death metal stream on YouTube is undoubtedly something new.
Fans of the AI-composed death metal have given the music rave reviews. As The Verge notes, the creation is “Perfectly imperfect” thanks to its blending of various death metal styles, transforming vocals into a choir and delivering sudden style-switching.
It appears that bare-metal has ushered in a new era in technical death metal.
Why does it matter?
Researchers behind the Relentless Doppelganger remark that developing music-making AI has mainly been based on classical music, which is heavily reliant on harmony, while death metal, among others, embraces the power of chaos. It stands to reason, then, that the music generated is not perfect when it comes to delivering harmony. The effect is actually more consistent with the genre’s overall sound. What’s more, Databots’ model delivers not only instrumentals, but also vocals, which would be unthinkable with classical music. Of course, the special style of metal singing called growl makes most of the lyrics incomprehensible, so little to no sense is actually required here.
From a scientific point of view, OpenAI delivers much more significant work. But AI is working its way into all human activity, including politics, social problems and policy and art. From an artistic point of view, AI-produced technical death metal is interesting.
It appears that when it comes to music, AI likes it brutal.
AI in gaming goes mainstream
Game development has a long and uneasy tradition of delivering computer players to allow users to play in single-player mode. There are many forms of non-ML-based AI present in video games. They are usually based on a set of triggers that initiate a particular action the computer player takes. What’s more, modern, story-driven games rely heavily on scripted events like ambushes or sudden plot twists.
This type of AI delivers an enjoyable level of challenge but lacks the versatility and viciousness of human players coming up with surprising strategies to deal with. Also, the goal of AI in single-player mode is not to dominate the human player in every way possible.
The real challenge in all of this comes from developing bots, or the computer-controlled players, to deliver a multiplayer experience in single-player mode. Usually, the computer players significantly differ from their human counterparts and any transfer from single to multiplayer ends with shock and an instant knock-out from experienced players.
A.N.N.A. is a neural network-based AI that is not scripted directly but created through reinforcement learning. This means developers describe an agent’s desired behaviour and then train a neural network to achieve it. Agents created in this way show more skilled and realistic behaviors, which are high on the wish list of Moto GP gamers.
Why does it matter?
Applying ML-based artificial intelligence in a mainstream game is the first step in delivering a more realistic and immersive game experience. Making computer players more human in their playing style makes them less exploitable and more flexible.
The game itself is an interesting example. It is common in RL-related research to apply this paradigm in strategic games, be it chess, GO or Starcraft II for research purposes. In this case, the neural network controls a digital motorcycle. Racing provides a closed game environment with a limited amount of variables to control. Thus, racing in a virtual world is a perfect environment to deploy ML-based solutions.
In the end, it isn’t the technology but rather gamers’ experience that is key. Will reinforcement learning bring a new paradigm of embedding AI in games? We’ll see once gamers react.
Bittersweet lessons from OpenAI Five
Defense of The Ancients 2 (DOTA 2) is a highly popular multiplayer online battle arena game with two teams, each consisting of five players fighting for control over a map. The game blends tactical, strategic and action elements and is one of the most popular online sports games.
OpenAI Five is the neural network that plays DOTA 2, developed by OpenAI.
The AI agent beat world champions from Team OG during the OpenAI Five Finals on April 13th. It was the first time an AI-controlled player has beaten a pro-player team during a live-stream.
Why does it matter?
Although the project seems similar to Deepmind’s AlphaStar, there are several significant differences:
The model was trained continuously for almost a year instead of starting from zero knowledge for each new experiment – the common way of developing machine learning models is to design the entire training procedure upfront, launch it and observe the result. Every time a novel idea is proposed, the learning algorithm is modified accordingly and a new experiment is launched starting from scratch to get a fair comparison between various concepts. In this case, researchers decided not to run training from scratch, but to integrate ideas and changes into the already trained model, sometimes doing elaborate surgery on their artificial neural network. Moreover, the game received a number of updates during the training process. Thus, the model was forced at some points not to learn a new fact, but to update its knowledge. And it managed to do so. The approach enabled the team to massively reduce the computing power over the amount it had invested in training previous iterations of the model.
The model effectively cooperated with human players – The model was available publicly as a player, so users could play with it, both as ally and foe. Despite being trained without human interaction, the model was effective both as an ally and foe, clearly showing that AI is a potent tool to support humans in performing their tasks — even when that task is slaying an enemy champion.
The research done was somewhat of a failure – The model performs well, even if building it was not the actual goal. The project was launched to break a previously unbroken game by testing and looking for new approaches. The best results were achieved by providing more computing power and upscaling the neural network. Despite delivering impressive results for OpenAI, the project did not lead to the expected breakthroughs and the company has hinted that it could be discontinued in its present format. A bitter lesson indeed.
Blurred computer vision
Computer vision techniques deliver astonishing results. They have sped up the diagnosing of diabetic retinopathy, built maps from satellite images and recognized particular whales from aerial photography. Well-trained models often outperform human experts. Given that they don’t get tired and never lose their focus, why shouldn’t they?
But there remains room for improvement for machine vision, as researchers from KU Leuven University in Belgium report. They delivered an image that fooled an algorithm, rendering the person holding a card with an image virtually invisible to a machine learning-based solution.
Why does it matter?
As readers of William Gibson’s novel Zero Hour will attest, images devised to fool AI are nothing new. Delivering a printable image to confound algorithm highlights a serious interest among malicious players interfering with AI.
Examples may include images produced to fool AI-powered medical diagnostic devices for fraudulent reasons or sabotaging road infrastructure to render it useless for autonomous vehicles.
AI should not be considered a black box and algorithms are not unbreakable. As always, reminders of that are welcome, especially as responsibility and transparency are among the most significant AI trends for 2019.
https://deepsense.ai/wp-content/uploads/2019/05/AI-Monthly-Digest-8-–-new-AI-applications-for-music-and-gaming.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-05-09 11:34:462024-02-06 19:08:42AI Monthly Digest #8 – new AI applications for music and gaming
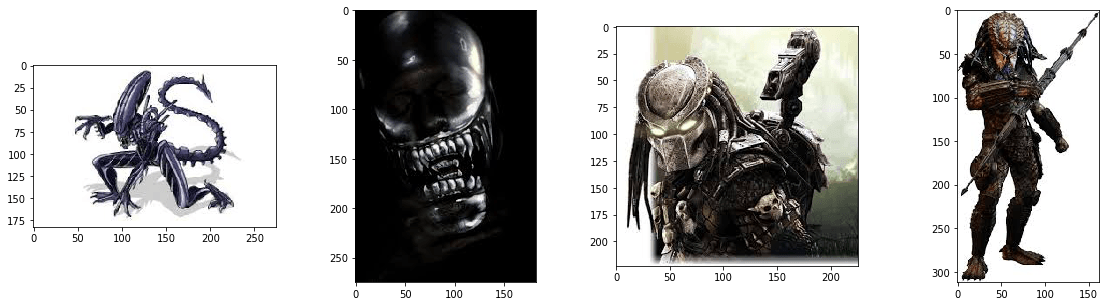
In our previous post, we gave you an overview of the differences between Keras and PyTorch, aiming to help you pick the framework that’s better suited to your needs. Now, it’s time for a trial by combat. We’re going to pit Keras and PyTorch against each other, showing their strengths and weaknesses in action. We present a real problem, a matter of life-and-death: distinguishing Aliens from Predators!
Image taken from our dataset. Both Predator and Alien are deeply interested in AI.
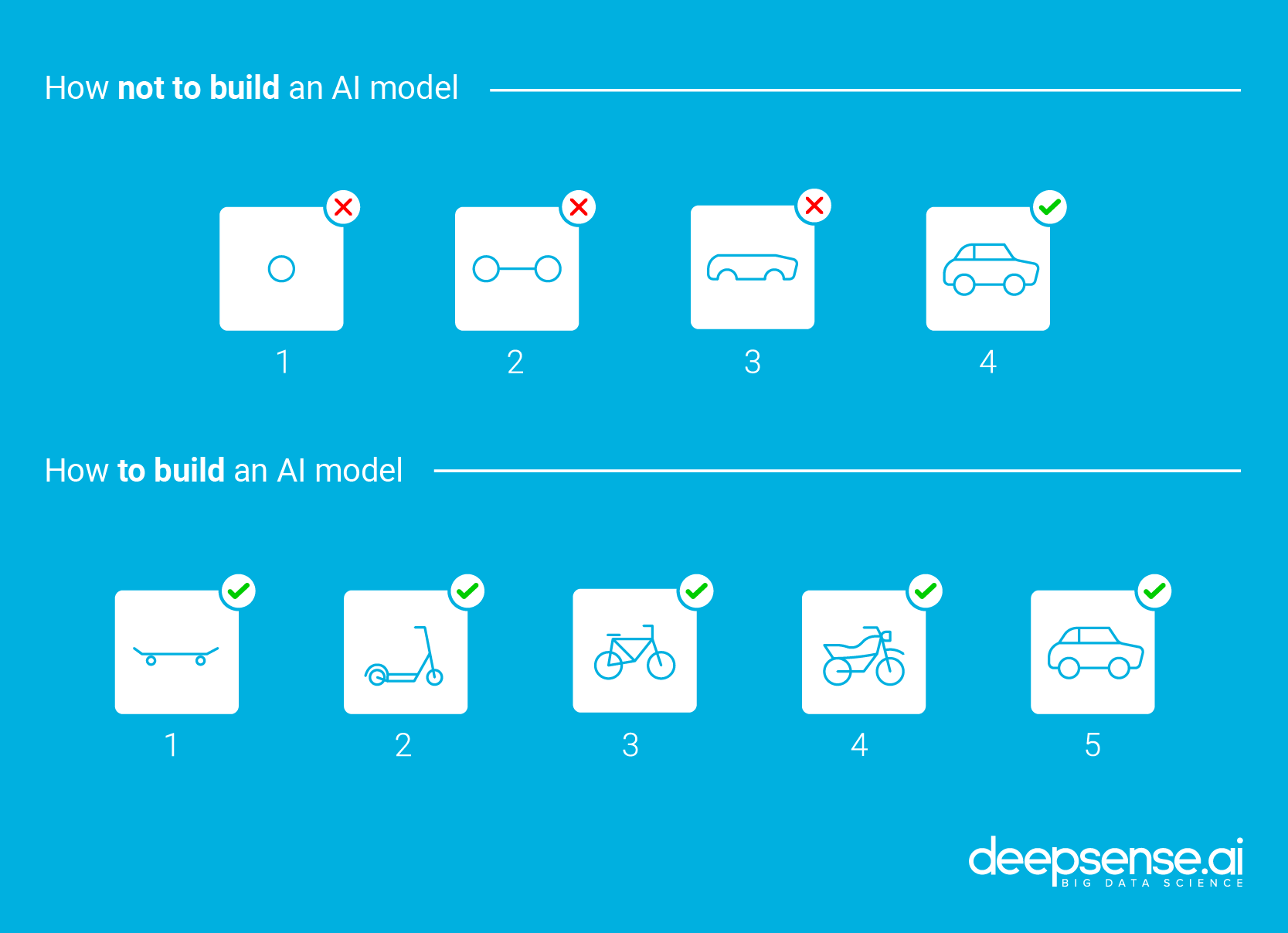
We perform image classification, one of the computer vision tasks deep learning shines at. As training from scratch is unfeasible in most cases (as it is very data hungry), we perform transfer learning using ResNet-50 pre-trained on ImageNet. We get as practical as possible, to show both the conceptual differences and conventions.
Wait, what’s transfer learning? And why ResNet-50?
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.– Andrej Karpathy (Transfer Learning – CS231n Convolutional Neural Networks for Visual Recognition)
Transfer learning is a process of making tiny adjustments to a network trained on a given task to perform another, similar task. In our case we work with the ResNet-50 model trained to classify images from the ImageNet dataset. It is enough to learn a lot of textures and patterns that may be useful in other visual tasks, even as alien as this Alien vs. Predator case. That way, we use much less computing power to achieve much better result.
In our case we do it the simplest way:
keep the pre-trained convolutional layers (so-called feature extractor), with their weights frozen,
remove the original dense layers, and replace them with brand-new dense layers we will use for training.
So, which network should be chosen as the feature extractor?
ResNet-50 is a popular model for ImageNet image classification (AlexNet, VGG, GoogLeNet, Inception, Xception are other popular models). It is a 50-layer deep neural network architecture based on residual connections, which are connections that add modifications with each layer, rather than completely changing the signal.
ResNet was the state-of-the-art on ImageNet in 2015. Since then, newer architectures with higher scores on ImageNet have been invented. However, they are not necessarily better at generalizing to other datasets (see the Do Better ImageNet Models Transfer Better? arXiv paper).
Ok, it’s time to dive into the code.
Let the match begin!
We do our Alien vs. Predator task in seven steps:
Prepare the dataset
Import dependencies
Create data generators
Create the network
Train the model
Save and load the model
Make predictions on sample test images
We supplement this blog post with Python code in Jupyter Notebooks (Keras-ResNet50.ipynb, PyTorch-ResNet50.ipynb). This environment is more convenient for prototyping than bare scripts, as we can execute it cell by cell and peak into the output.
All right, let’s go!
0. Prepare the dataset
We created a dataset by performing a Google Search with the words “alien” and “predator”. We saved JPG thumbnails (around 250×250 pixels) and manually filtered the results. Here are some examples:
We split our data into two parts:
Training data (347 samples per class) – used for training the network.
Validation data (100 samples per class) – not used during the training, but needed in order to check the performance of the model on previously unseen data.
Keras requires the datasets to be organized in folders in the following way:
If you want to see the process of organizing data into directories, check out the data_prep.ipynb file. You can download the dataset from Kaggle.
1. Import dependencies
First, the technicalities. We assume that you have Python 3.5+, Keras 2.2.2 (with TensorFlow 1.10.1 backend) and PyTorch 0.4.1. Check out the requirements.txt file in the repo.
So, first, we need to import the required modules. We separate the code in Keras, PyTorch and common (one required in both).
COMMON
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
KERAS
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import ResNet50
from keras.applications.resnet50 import preprocess_input
from keras import Model, layers
from keras.models import load_model, model_from_json
PYTORCH
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
We can check the frameworks’ versions by typing keras.__version__ and torch.__version__, respectively.
2. Create data generators
Normally, the images can’t all be loaded at once, as doing so would be too much for the memory to handle. At the same time, we want to benefit from the GPU’s performance boost by processing a few images at once. So we load images in batches (e.g. 32 images at once) using data generators. Each pass through the whole dataset is called an epoch.
We also use data generators for preprocessing: we resize and normalize images to make them as ResNet-50 likes them (224 x 224 px, with scaled color channels). And last but not least, we use data generators to randomly perturb images on the fly:
Performing such changes is called data augmentation. We use it to show a neural network which kinds of transformations don’t matter. Or, to put it another way, we train on a potentially infinite dataset by generating new images based on the original dataset.
Almost all visual tasks benefit, to varying degrees, from data augmentation for training. For more info about data augmentation, see as applied to plankton photos or how to use it in Keras. In our case, we randomly shear, zoom and horizontally flip our aliens and predators.
In Keras, you get built-in augmentations and preprocess_input method normalizing images put to ResNet-50, but you have no control over their order. In PyTorch, you have to normalize images manually, but you can arrange augmentations in any way you like.
There are also other nuances: for example, Keras by default fills the rest of the augmented image with the border pixels (as you can see in the picture above) whereas PyTorch leaves it black. Whenever one framework deals with your task much better than the other, take a closer look to see if they perform preprocessing identically; we bet they don’t.
3. Create the network
The next step is to import a pre-trained ResNet-50 model, which is a breeze in both cases. We freeze all the ResNet-50’s convolutional layers, and only train the last two fully connected (dense) layers. As our classification task has only 2 classes (compared to 1000 classes of ImageNet), we need to adjust the last layer.
Here we:
load pre-trained network, cut off its head and freeze its weights,
add custom dense layers (we pick 128 neurons for the hidden layer),
set the optimizer and loss function.
KERAS
conv_base = ResNet50(include_top=False,
weights='imagenet')
for layer in conv_base.layers:
layer.trainable = False
x = conv_base.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(128, activation='relu')(x)
predictions = layers.Dense(2, activation='softmax')(x)
model = Model(conv_base.input, predictions)
optimizer = keras.optimizers.Adam()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
PYTORCH
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.resnet50(pretrained=True).to(device)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 2)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters())
We load the ResNet-50 from both Keras and PyTorch without any effort. They also offer many other well-known pre-trained architectures: see Keras’ model zoo and PyTorch’s model zoo. So, what are the differences?
In Keras we may import only the feature-extracting layers, without loading extraneous data (include_top=False). We then create a model in a functional way, using the base model’s inputs and outputs. Then we use model.compile(…) to bake into it the loss function, optimizer and other metrics.
In PyTorch, the model is a Python object. In the case of models.resnet50, dense layers are stored in model.fc attribute. We overwrite them. The loss function and optimizers are separate objects. For the optimizer, we need to explicitly pass a list of parameters we want it to update.
Frame from ‘AVP: Alien vs. Predator’: Predators’ wrist computer. We’re pretty sure Predator could use it to compute logsoftmax.
In PyTorch, we should explicitly specify what we want to load to the GPU using .to(device) method. We have to write it each time we intend to put an object on the GPU, if available. Well…
Layer freezing works in a similar way. However, in The Batch Normalization layer of Keras is broken (as of the current version; thx Przemysław Pobrotyn for bringing this issue). That is – some layers get modified anyway, even with trainable = False.
Keras and PyTorch deal with log-loss in a different way.
In Keras, a network predicts probabilities (has a built-in softmax function), and its built-in cost functions assume they work with probabilities.
In PyTorch we have more freedom, but the preferred way is to return logits. This is done for numerical reasons, performing softmax then log-loss means doing unnecessary log(exp(x)) operations. So, instead of using softmax, we use LogSoftmax (and NLLLoss) or combine them into one nn.CrossEntropyLoss loss function.
4. Train the model
OK, ResNet is loaded, so let’s get ready to space rumble!
Frame from ‘AVP: Alien vs. Predator’: the Predators’ Mother Ship. Yes, we’ve heard that there are no rumbles in space, but nothing is impossible for Aliens and Predators.
Now, we proceed to the most important step – model training. We need to pass data, calculate the loss function and modify network weights accordingly. While we already had some differences between Keras and PyTorch in data augmentation, the length of code was similar. For training… the difference is massive. Let’s see how it works!
Here we:
train the model,
measure the loss function (log-loss) and accuracy for both training and validation sets.
KERAS
history = model.fit_generator(
generator=train_generator,
epochs=3,
validation_data=validation_generator)
PYTORCH
def train_model(model, criterion, optimizer, num_epochs=3):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(image_datasets[phase])
epoch_acc = running_corrects.double() / len(image_datasets[phase])
print('{} loss: {:.4f}, acc: {:.4f}'.format(phase,
epoch_loss,
epoch_acc))
return model
model_trained = train_model(model, criterion, optimizer, num_epochs=3)
In Keras, the model.fit_generator performs the training… and that’s it! Training in Keras is just that convenient. And as you can find in the notebook, Keras also gives us a progress bar and a timing function for free. But if you want to do anything nonstandard, then the pain begins…
Predator’s shuriken returning to its owner automatically. Would you prefer to implement its tracking ability in Keras or PyTorch?
PyTorch is on the other pole. Everything is explicit here. You need more lines to construct the basic training, but you can freely change and customize all you want.
Let’s shift gears and dissect the PyTorch training code. We have nested loops, iterating over:
epochs,
training and validation phases,
batches.
The epoch loop does nothing but repeat the code inside. The training and validation phases are done for three reasons:
Some special layers, like batch normalization (present in ResNet-50) and dropout (absent in ResNet-50), work differently during training and validation. We set their behavior by model.train() and model.eval(), respectively.
We use different images for training and for validation, of course.
The most important and least surprising thing: we train the network during training only. The magic commands optimizer.zero_grad(), loss.backward() and optimizer.step() (in this order) do the job. If you know what backpropagation is, you appreciate their elegance.
We take care of computing the epoch losses and prints ourselves.
5. Save and load the model
Saving
Once our network is trained, often with high computational and time costs, it’s good to keep it for later. Broadly, there are two types of savings:
saving the whole model architecture and trained weights (and the optimizer state) to a file,
saving the trained weights to a file (keeping the model architecture in the code).
It’s up to you which way you choose.
Here we:
save the model.
KERAS
# architecture and weights to HDF5
model.save('models/keras/model.h5')
# architecture to JSON, weights to HDF5
model.save_weights('models/keras/weights.h5')
with open('models/keras/architecture.json', 'w') as f:
f.write(model.to_json())
Frame from ‘Alien: Resurrection’: Alien is evolving, just like PyTorch.
One line of code is enough in both frameworks. In Keras you can either save everything to a HDF5 file or save the weights to HDF5 and the architecture to a readable json file. By the way: you can then load the model and run it in the browser.
Currently, PyTorch creators recommend saving the weights only. They discourage saving the whole model because the API is still evolving.
Loading
Loading models is as simple as saving. You should just remember which saving method you chose and the file paths.
Here we:
load the model.
KERAS
# architecture and weights from HDF5
model = load_model('models/keras/model.h5')
# architecture from JSON, weights from HDF5
with open('models/keras/architecture.json') as f:
model = model_from_json(f.read())
model.load_weights('models/keras/weights.h5')
In Keras we can load a model from a JSON file, instead of creating it in Python (at least when we don’t use custom layers). This kind of serialization makes it convenient for transfering models.
PyTorch can use any Python code. So pretty much we have to re-create a model in Python.
Loading model weights is similar in both frameworks.
6. Make predictions on sample test images
All right, it’s finally time to make some predictions! To fairly check the quality of our solution, we ask the model to predict the type of monsters from images not used for training. We can use the validation set, or any other image.
Here we:
load and preprocess test images,
predict image categories,
show images and predictions.
COMMON
validation_img_paths = ["data/validation/alien/11.jpg",
"data/validation/alien/22.jpg",
"data/validation/predator/33.jpg"]
img_list = [Image.open(img_path) for img_path in validation_img_paths]
KERAS
validation_batch = np.stack([preprocess_input(np.array(img.resize((img_size, img_size))))
for img in img_list])
pred_probs = model.predict(validation_batch)
PYTORCH
validation_batch = torch.stack([data_transforms['validation'](img).to(device)
for img in img_list])
pred_logits_tensor = model(validation_batch)
pred_probs = F.softmax(pred_logits_tensor, dim=1).cpu().data.numpy()
COMMON
fig, axs = plt.subplots(1, len(img_list), figsize=(20, 5))
for i, img in enumerate(img_list):
ax = axs[i]
ax.axis('off')
ax.set_title("{:.0f}% Alien, {:.0f}% Predator".format(100*pred_probs[i,0],
100*pred_probs[i,1]))
ax.imshow(img)
Prediction, like training, works in batches (here we use a batch of 3; though we could surely also use a batch of 1). In both Keras and PyTorch we need to load and preprocess the data. A rookie mistake is to forget about the preprocessing step (including color scaling). It is likely to work, but result in worse predictions (since it effectively sees the same shapes but with different colors and contrasts).
In PyTorch there are two more steps, as we need to:
convert logits to probabilities,
transfer data to the CPU and convert to NumPy (fortunately, the error messages are fairly clear when we forget this step).
And this is what we get:
It works!
And how about other images? If you can’t come up with anything (or anyone) else, try using photos of your co-workers. :)
Conclusion
As you can see, Keras and PyTorch differ significantly in terms of how standard deep learning models are defined, modified, trained, evaluated, and exported. For some parts it’s purely about different API conventions, while for others fundamental differences between levels of abstraction are involved.
Keras operates on a much higher level of abstraction. It is much more plug&play, and typically more succinct, but at the cost of flexibility.
PyTorch provides more explicit and detailed code. In most cases it means debuggable and flexible code, with only small overhead. Yet, training is way-more verbose in PyTorch. It hurts, but at times provides a lot of flexibility.
Transfer learning is a big topic. Try tweaking your parameters (e.g. dense layers, optimizer, learning rate, augmentation) or choose a different network architecture.
Have you tried transfer learning for image recognition? Consider the list below for some inspiration:
Pick Keras or PyTorch, choose a dataset and let us know how it went in the comments section below :)
https://deepsense.ai/wp-content/uploads/2019/04/keras-vs-pytorch-avp-transfer-learning.jpg3371140Piotr Migdalhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPiotr Migdal2018-10-03 17:21:202024-12-30 14:48:04Keras vs. PyTorch: Alien vs. Predator recognition with transfer learning
March saw some major events concerning top figures of the ML world, including OpenAI, Yann LeCun, Geoffrey Hinton and Yoshua Bengio.
The past month was also the backdrop for inspiring research on how machines think and how different they can be from humans when provided with the same conditions and problem to solve.
OpenAI goes from non-profit to for-profit
OpenAI was initially the non-profit organization focused on pushing the boundaries of artificial intelligence in the same manner the open-source organizations are able to deliver the highest-class software. The Mozilla Foundation and the Linux Foundation, the non-profit powerhouses behind the popular products, are the best examples.
Yet unlike the popular software with development powered by human talent, AI requires not only brilliant minds but also a gargantuan amount of computing power. The cost of reproducing the GPT-2 model is estimated to be around $50,000 – and that’s only one experiment to conduct. Getting the job done requires a small battalion of research scientists tuning hyperparameters, debugging and testing the approaches and ideas.
Staying on technology’s cutting edge pushed the organization toward the for-profit model to fund the computing power and attracting top talent, as the company notes on its website.
Why does it matter?
First of all, OpenAI was a significant player on the global AI map despite being a non-profit organization. Establishing a for-profit arm creates a new strong player that can develop commercial AI projects.
Moreover, the problem lies in the need for computing power, marking the new age of development challenges. In a traditional software development world, a team of talented coders is everything one would need. When it comes to delivering the AI-models, that is apparently not enough.
The bitter lesson of ML’s development
OpenAI’s transition could be seen as a single event concerning only one organization. It could be, that is, if it wasn’t discussed by the godfathers of modern machine learning.
Richard Sutton is one of the most renowned and influential researchers of reinforcement learning. In a recent essay, he remarked that most advances in AI development are powered by access to computing power, while the importance of expert knowledge and creative input from human researchers is losing significance.
Moreover, numerous attempts have been made to enrich machine learning with expert knowledge. Usually, the efforts were short-term gains with no bigger significance when seen in the broader context of AI’s development.
Why does it matter?
The opinion would seem to support the general observation that computing power is the gateway to pushing the boundaries of machine learning and artificial intelligence. That power combined with relatively simple machine learning techniques frequently challenges the established ways of solving problems. The RL-based agents playing GO, chess or Starcraft are only top-of-mind examples.
Yann LeCun, Geoffrey Hinton and Yoshua Bengio awarded the Turing Award
The Association for Computing Machinery, the world’s largest organization of computing professionals, announced that this year’s Turing Award went to three researchers for their work on advancing and popularizing neural networks. Currently, the researchers split their time between academia and the private sector, with Yann LeCun being employed by Facebook and New York University, Geoffrey Hinton working for Google and the University of Toronto, and Yoshua Bengio splitting his time between the University of Montreal and his company Element AI.
Why does it matter?
Named after Alan Turing, a giants of mathematics and the godfather of modern computer science, the Turing Award has been called IT’s Nobel Prize. While the lack of such a prize in IT is obvious — IT specialists get the Turing Award.
Nvidia creates a wonder brush – AI that turns a doodle into a landscape
Nvidia has shown how an AI-powered editor swiftly transforms simple, childlike images into near-photorealistic landscapes. While the technology isn’t exactly new, this time the form is interesting. It uses Generative Adversarial Networks and amazes with the details it can muster – if the person drawing adds a lake near a tree, the water will reflect it.
Why does it matter?
Nvidia does a great job in spreading the knowledge about machine learning. Further applications in image editing will no doubt be forthcoming, automating the work of illustrators and graphic designers. But for now, it is amazing to behold.
So do you think like a computer?
While machine learning models are superhumanly effective in image recognition, if they fail, their predictions are usually at least surprising. Until recently, it was believed that people are unable to predict how a computer will interpret an image when not in the right way. Moreover, the totally inhuman way of recognizing the image is prone to mistakes – it is possible to prepare an artificial image that can effectively fool the AI behind the image recognition and, for example, convince the model that a car is in fact a bush.
The confusion about the machines identifying objects usually comes from the fact that most AI models are narrow AI. The systems are designed to work in a closed environment and solve a narrow problem, like identifying cars or animals. Consequently, the machine has a narrow catalog of entities to name.
To check if humans are able to understand how the machine is making its mistakes, the researchers provided volunteers with images that had already fooled AI models together with the names the machines were able to choose from for those images. In those conditions, people provided the same answers as the machines 75% of the time.
Why does it matter?
A recent study from John Hopkins University shows that computers become increasingly human even in their mistakes and that surprising outcomes are the consequence of extreme narrowness of the artificial mind. A typical preschooler has an incomparably larger vocabulary and amount of experience collected than even the most powerful neural network, so the likelihood of a human finding a more accurate association for the image are many times larger.
Again, the versatility and flexibility of the human mind is the key to its superiority.
https://deepsense.ai/wp-content/uploads/2019/04/AI-monthly_digest_7.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-04-11 13:29:282024-02-06 19:11:34AI Monthly Digest #7 – machine mistakes, and the hard way to profit from non-profit
To fully leverage the potential of artificial intelligence in business, access to computing power is key. That doesn’t mean, however, that supercomputers are necessary for everyone to take advantage of the AI revolution.
In January 2019 the world learned of the AI model known as AlphaStar, which had vanquished the world’s reigning Starcraft II champion. Training the model by having it square off against a human would have required around 400 years of non-stop play. But thanks to enormous computing power and some neural networks, AlphaStar’s creators needed a mere two weeks.
AlphaStar and similar models of artificial intelligence can be compared to a hypothetical chess player that achieves a superhuman level by playing millions of opponents—a number humans, due to our biological limitations, cannot endeavor to meet. So that they need not spend years training their models, programmers provide them access to thousands of chessboards and allow them to play huge numbers of games at the same time. This parallelization can be achieved by properly building the architecture of the solution on a supercomputer, but it can also be much simpler: by ordering all these chess boards as instances (machines) in the cloud.
Building such models comes with a price tag few can afford as easily as do Google-owned AlphaStar and AlphaGo. And given these high-profile experiments, it should come as no surprise that the business world still believes technological experiments require specialized infrastructure and are expensive. Sadly, this perception extends to AI solutions.
A study done by McKinsey and Company—“AI adoption advances, but foundational barriers remain”—brings us the practical confirmation of this thesis. 25% of the companies McKinsey surveyed indicated that a lack of adequate infrastructure was a key obstacle to developing AI in their own company. Only the lack of an AI strategy and of people and support in the organization were bigger obstacles – that is, fundamental themes preceding any infrastructure discussions.
So how does one reap the benefits of artificial intelligence and machine learning without having to run multi-million dollar projects? There are three ways.
Precisely determine the scope of your AI experiments. A precise selection of business areas to test models and clearly defined success rates is necessary. By scaling down the case being tested to a minimum, it is possible to see how a solution works while avoiding excessive hardware requirements.
Use mainly cloud resources, which generate costs only when used and, thanks to economies of scale, keep prices down.
Create a simplified model using cloud resources, thus combining the advantages of the first two approaches.
Feasibility study – even on a laptop
Even the most complicated problem can be tackled by reducing it to a feasibility study, the maximum simplification of all elements and assumptions. Limiting unnecessary complications and variables will remove the need for supercomputers to perform the calculations – even a decent laptop will get the job done.
An example of a challenge
In a bid to boost its cross-sell/up-sell efforts, a company that sells a wide variety of products in a range of channels needs an engine that recommends to customers its most interesting products.
A sensible approach to this problem would be to first identify a specific business area or line, analyze the products then select the distribution channel. The channel should provide easy access to structured data. The ideal candidate here is online/e-commerce businesses, which could limit the group of customers to a specific segment or location and start building and testing models on the resulting database.
Such an approach would enable the company to avoid the gathering, ordering, standardizing and processing huge amounts of data that complicate the process and account for most of the infrastructure costs. But preparing a prototype of the model makes it possible to efficiently enter the testing and verification phase of the solution’s operation.
So narrowed down, the problem can be solved by even a single date scientist equipped with a good laptop. Another practical application of this approach comes via Uber. Instead of creating a centralized analysis and data science department, the company hired a machine learning specialist for each of its teams. This led to small adjustments being made to automate and speed up daily work in all of its departments. AI is perceived here not as another corporate-level project, but as a useful tool employees turn to every day.
This approach fits into the widely used (and for good reason) agile paradigm, which aims to create value iteratively by collecting feedback as quickly as possible and include it in the ‘agile’ product construction process (see the graphic below).
When is power really necessary?
Higher computing power is required in the construction of more complex solutions whose tasks go far beyond the standard and which will be used on a much larger scale. The nature of the data being processed can pose yet another obstacle, as the model deepsense.ai developed for the National Oceanic and Atmospheric Administration (NOAA) will illustrate.
The company was tasked by the NOAA with recognizing particular Atlantic Right whales in aerial photographs. With only 450 individual whales left, the species is on the brink of extinction, and only by tracking the fate of each animal separately is it possible to protect them and provide timely help to injured whales.
Is that Thomas and Maddie in the picture?
The solution called for three neural networks that would perform different tasks consecutively – finding the whale’s head in the photo, cropping and framing the photo, and recognizing exactly which individual was shown.
These tasks required surgical precision and consideration of all of the data available—as you’d rightly image—from a very limited number of photos. Such demands complicated the models and required considerable computing power. The solution ultimately automated the process of identifying individuals swimming throughout the high seas, limiting the human work time from a few hours spent poring over the catalog of whale photos to about thirty minutes for checking the results the model returned.
Reinforcement learning (RL) is another demanding category of AI. RL models are taught through interactions with their environment and a set of punishments and rewards. This means that neural networks can be trained to solve open problems and operate in variable, unpredictable environments based on pre-established principles, the best example being controlling an autonomous car.
In addition to the power needed to train the model, autonomous cars require a simulated environment to be run in, and creating that is often even more demanding than the neural network itself. Researchers from deepsense.ai and Google Brain are working on solving this problem through artificial imagination, and the results are more than promising.
Travel in the cloud
Each of the above examples requires access to large-scale computing power. When the demand for such power jumps, cloud computing holds the answer. The cloud offers three essential benefits in supporting the development of machine learning models:
A pay-per-use model keeps costs low and removes barriers to entry – with a pay-per-use model, as the name suggests, the user pays only for resources used, thus driving down costs significantly. Cloud is estimated to be as much as 30% cheaper to implement and maintain than an ownership infrastructure. After all, it removes the need to invest in equipment that can handle complicated calculations. Instead, you pay only for a ‘training session’ for a neural network. After completing the calculations, the network is ready for operation. Running machine learning-based solutions isn’t all that demanding. Consider, for example, that AI is used in mobile phones to adjust technical settings and make photos the best they can be. With support for AI models, you can even handle a processor on your phone.
Easy development and expansion opportunities – transferring company resources to the cloud brings a wide range of complementary products within reach. Cloud computing makes it possible to easily share resources with external platforms, and thus even more efficiently use the available data through the visualization and in-depth analysis those platforms offer. According to a RightScale report, State of the Cloud 2018, as an organization’s use of the cloud matures, its interest in additional services grows. Among enterprises describing themselves as cloud computing “beginners,” only 18 percent are interested in additional services. The number jumps to 40 percent among the “advanced” cohort. Whatever a company’s level of interest, there is a wide range of solutions supporting machine learning development awaiting them – from simple processor and memory hiring to platforms and ready-made components for the automatic construction of popular solutions.
Permanent access to the best solutions – by purchasing specific equipment, a company will be associated with a particular set of technologies. Companies looking to develop machine learning may need to purchase special GPU-based computers to efficiently handle the calculations. At the same time, equipment is constantly being developed, which may mean that investment in a specific infrastructure is not the optimal choice. For example, Google’s Tensor Processing Unit (TPU) may be a better choice than a GPU for machine learning applications. Cloud computing allows every opportunity to employ the latest available technologies – both in hardware and software.
Risk in the skies?
The difficulties that have put a question mark over migrating to the cloud are worth elaborating here. In addition to the organizational maturity mentioned earlier and the fear of high costs, the biggest problem is that some industries and jurisdictions may prevent full control over one’s own data. Not all data can be freely sent (even for a moment) to foreign data centers. Mixed solutions that simultaneously use both cloud and the organization’s own infrastructure are useful here. Data are divided into those that must remain in the company and those that can be sent to the cloud.
In Poland, this problem will be addressed by the recently appointed Operator Chmury Krajowej (National Cloud Operator), which will offer cloud computing services fully implemented in data centers located in Poland. This could well convince some industries and the public sector to open up to the cloud.
Matching solutions
Concerns about the lack of adequate computational resources a company needs if it wants to use machine learning are in most cases unjustified. Many models can be built using ordinary commodity hardware that is already in the enterprise. And when a system is to be built that calls for long-term training of a model and large volumes of data, the power and infrastructure needed can be easily obtained from the cloud.
Machine learning is currently one of the hottest business trends. And for good reason. Easy access to the cloud democratizes computing power and thus also access to AI – small companies can use the enormous resources available every bit as quickly as the market’s behemoths. Essentially, there’s a feedback loop between cloud computing and machine learning that cannot be ignored.
The article was originally published in Harvard Business Review.
https://deepsense.ai/wp-content/uploads/2019/04/With-your-head-in-the-clouds-–-how-to-harness-the-power-of-artificial-intelligence.jpg3371140Paweł Osterreicherhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngPaweł Osterreicher2019-04-04 13:15:542021-01-05 16:46:03With your head in the clouds – how to harness the power of artificial intelligence
With a ground-breaking AlphaStar performance, January kickstarted 2019 AI-related research and activities.
The January edition of AI Monthly digest brings a marvel to behold–AlphaStar beating human champions at the real-time strategy game StarCraft. To find out why that’s important, read the full story.
AlphaStar beats top world StarCraft II pro players
AlphaStar, a DeepMind-created agent, beat two world-famous professional players in StarCraft II. The agent was using a Protoss race and playing against another Protoss. The game itself can also play Zerg and Terrans, but AlphaStar is trained only to play Protoss vs. Protoss matches.
The machine defeated Dario “TLO” Wunsch, a Zerg specialist playing Protoss for the occasion, 5-0 in the first five-match round. It then made quick work of professional Protoss player Grzegorz “MaNa” Komnicz beating the champion 5:0.
A noticeable advantage AlphaStar had against both players was its access to the entire StarCraft II map at once. It is still obscured by the fog of war, but the agent doesn’t have to mimic the human’s camera moves. DeepMind prepared one other agent to address this issue and plays using a camera interface, but it lost to MaNa 0:1.
To make the matches fair, the DeepMind team reduced the Actions Per Minute (APM) ratio to a human level and ensured the machine had no advantage in terms of reaction time. Nonetheless, it was clear at crucial moments that AlphaStar had bursts of APM far above human abilities. DeepMind is aware of this and will probably do something about it in the future. For now, however, we will be content to focus on what we have seen.
How the matches went
Unlike human players, AlphaStar had employed some unorthodox yet not necessarily wrong strategies – avoiding walling the entrance to the base with buildings was the most conspicuous one. What’s more, the model used significantly more harvesting drones than pro players normally use.
Beyond its superiority in micromanagement (the art of managing a single unit and using its abilities on the battlefield), the agent didn’t display any clearly non-human strategies or abilities. However, AlphaStar was seen at its finest when it managed to win the match by managing a large number of Stalkers, the unit that is normally countered by Immortals in a rock-paper-scissors manner. As MaNa, the human player confronting the agent, noted, he had never encountered a player with such abilities. As such, the gameplay was clearly on a superhuman level, especially considering the fact that MaNa executed the counter-tactic, which failed due to AlphaStar’s superior micromanagement.
How the Deepmind team did it
The initial process of training the agent took ten days – three of supervised learning built on the basis of replays of top StarCraft II players. The team then infused the agent with reinforcement learning abilities (an approach similar to our team’s cracking Montezuma’s Revenge) and created the “AlphaStar” league to build multiple agents competing against each other. league witnessed a similar cycle with some strategies emerging and being later countered.
After that, the team selected five agents for a match with TLO. To further polish their skills, the agents were trained for another week before the match with the MaNa. As a Protoss specialist, MaNa posed a greater challenge than TLO, a Zerg-oriented player who was learning Protoss tactics only to square off against AlphaStar.
Courtesy of Blizzard, the developer of StarCraft II, Deepmind was delivered a significantly faster version of StarCraft II. This version enabled each agent in AlphaStar league to experience up to 200 years of real-time gameplay in just two weeks.
Why it matters
The AI community has grown accustomed to witnessing agents cracking Atari Classics and popular board games like chess or Go. Both environments provide a diverse set of challenges, with chess being a long-term fully observable strategy game and Atari delivering real-time experience with limited data.
StarCraft combines all manner of challenge by forcing players to follow the long-term strategy without knowledge of an opponent’s strategy and movement until it is in the line of sight of its own units (normally the battlefield is covered by the “fog of war”). Each encounter may show that a strategy needs to be fixed or adapted, as many units and strategies tend to work in a rock-paper-scissors manner, enabling players to play in a tactic-counter-tactic circle. Problem-solving in real time while sticking to a long-term strategy, constantly adapting to a changing environment and optimizing one’s efforts are all skills that can be later extrapolated to solve more challenging real-world problems.
Thus, while playing computer games is fun, the research they enable is very serious. It also lays bare the contrast between human and machine abilities. The computer was able to beat a human player after about four hundred years of constant playing. The human expert, meanwhile, was twenty-five years old, had started playing StarCraft at the age of six and had to sleep or go to school while not playing StarCraft.
Nevertheless, impressive and inspiring.
Understanding the biological brain using a digital one
According to Brain Injury Alliance Wisconsin, approximately 10% of individuals are touched by brain injuries and 5.3 million Americans (a little more than 2% of the US population) live with the effects of a brain injury. Every 23 seconds someone suffers a brain injury in the US.
Such injuries add up to $76.5 billion in annual costs once treatment, transportation and the range of indirect costs like lost productivity are considered.
While brain trauma may sometimes be responsible for the loss of speech, strokes and motor neurone disease are also to blame. Although patients lose the ability to communicate, they often remain conscious. Stephen Hawking is perhaps the most famous such person. Hawking used a speech generator, which he controlled with the muscles in his cheek. The generators can also be controlled with the eyes.
Applying neural networks to interpret the signals within the brain enabled the scientists to reconstruct speech. Summarizing the efforts, Science magazine points out that the effects are more than promising.
Alzheimer’s disease is another challenge that may be tackled with neural networks. There are no medications that heal the disease, but applying the treatment early enough makes it manageable. With Alzheimer’s, the earlier the diagnosis is made, the more effective the treatment will be. The challenge is in the diagnosis, which often comes too late for the disease to be reversible.
By feeding the neural networks with glucose PET scans, researchers from the University of California delivered a system that can diagnose the early symptoms of Alzheimer’s disease up to six years earlier than doctors do.
Why it matters
The human brain is one of the most complex devices in the universe, so understanding how it works is obviously a great challenge. Applying neural networks to treat brain-related diseases may come with a bit of irony – we need an outer, artificial brain to outthink the way our own is working.
Democratizing the AI – the Finnish way
Machine learning and artificial intelligence, in general, tend to be depicted as a black box, with no way to get to know “what the machine is thinking”. At the same time, it is often shown as a miraculous problem-solver, pulling working solutions out of seemingly nothing like a magician procuring a rabbit from a hat. But this too is a misconception.
Like every tool before it, neural networks need to be understood if they are to yield the most valuable outcomes. That’s one reason Finland aims to train its population in AI techniques and machine learning. Starting with 1% of its population (or roughly 55,000 people), the country aims to boost its society and economy by being a leader in the practical application of AI.
Initially a grassroots movement, the initiative gained the support of the government and Finland’s largest employers.
Why it matters
The biggest barrier in using AI and machine learning-powered techniques is uncertainty and doubt. Considering that people are afraid of things they don’t understand, spreading the knowledge about machine learning will support the adoption and reduce societal reluctance to adapting these tools. Moreover, understanding the mechanisms powering ML-based tools will give users a greater understanding of just what the tools are and are not capable of.
New state-of-the-art in robotic grasping
The issues Artificial Intelligence prompts frequently ignite philosophical debate and add interesting insight and inspiration. This recent paper on robot grasping is short of neither insights nor inspiration.
[bctt tweet=”The idea behind the use of reinforcement learning to control robotic arms is simple – hard-coding all the possible situations the robot may encounter is virtually impossible, but building a policy to follow is much easier” via=”no”]
What’s more, building the controller for the robotic arm requires the mountains of data coming from the sensors to be cross-combined. Every change – be it lighting, color or position of an object — can confuse the controller and result in failure.
Thus, the research team built a neural network that processes the input into the “canonical” version, stripped of the insignificant details like shades or graphical patterns – so that grasping is the only thing that matters. Ushering in a new state of the art in robotic grasping, the results are impressive.
Why do the results matter?
There are two reasons these results are important. First, building the controllers of robotic arms is now simpler. Robots that can move in non-supervised, non-hardcoded ways and grasp objects will be used in astonishing ways to improve human lives–for example, as assistants for the disabled or by augmenting the human workforce in manufacturing.
The second breakthrough is how researchers achieved their improvements. Instead of building more powerful neural networks to improve the input processing, the researchers downgraded the data into a homogenous, simplified “canonical” version of the reality. It seems that when it comes to robotic perception, Immanuel Kant was right. There are “things that exist independently of the senses or perception”, but they are unknowable–at least for a robotic observer. Only operating within a simplified reality enables the robot to perform the task.
Keep informed on state-of-the-art machine learning
With the rapidly changing ML landscape, it is easy to lose track of the latest developments. A lecture given by MIT researcher Lex Fridman is a good way to start. The video can be seen here:
https://deepsense.ai/wp-content/uploads/2019/02/AI-Monthly-digest-5-–-AlphaStar-beats-human-champions-robots-learn-to-grasp-and-a-Finnish-way-to-make-AI-a-commodity.png3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-02-08 13:46:182024-10-14 14:47:42AI Monthly digest #5 – AlphaStar beats human champions, robots learn to grasp and a Finnish way to make AI a commodity
With social media users numbering in the billions, all hailing from various backgrounds and bringing diverse moral codes to today’s wildly popular platforms, a space for hate speech has emerged. Internet service providers have responded by employing AI-powered solutions to address this insidious problem.
Hate speech is a serious issue. It undermines the principles of democratic society and the rules of public debate. Legal views on the matter vary. On the internet, every statement that transgresses the standards for hate speech established by a given portal (Facebook, Twitter, Wikipedia etc.) may be banned from publication. To get around such bans, numerous groups have launched platforms to exchange their thoughts and ideas. Stricter definitions of hate speech are common. They make users feel safe, which is paramount for social media sites as the presence of users is often crucial to income. And that’s where building machine learning models spotting the hate speech comes in.
What is hate speech?
The definition of hate speech varies by country and may apply to various aspects of language. Laws prohibit directing hateful speech and defamatory language toward another’s religion, ethnicity or sexuality. Many countries penalize anyone who agitates violence or genocide. Additionally, many legislatures ban symbols of totalitarian regimes and limit the freedom of assembly when ideologies like fascism or communism are involved.
In its most common form, hate speech attacks a person or group based on race, religion, ethnicity, national origin, disability, gender or sexual orientation. As regards what’s legal, the devil, as usual, is in the details. Finding the balance between freedom of speech and the protection of minority rights makes it difficult to produce a strict definition of hate speech. However, the problem has certainly grown with the rise of social media companies. The 2.27 bln active users of Facebook, who come from various backgrounds and bring diverse moral codes to the platform, have unwittingly provided a space for hate speech to emerge. Due to the international and flexible nature of the Internet, battling online hate speech is a complex task involving various parties.
Finally, there is a proven link between offensive name-calling and higher rates of suicide within migrant groups.
Why online hate speech is a problem
As a study from Pew Research Center indicates, 41% of American adults have experienced some form of online harassment. The most common is offensive name calling (experienced by 27%) and purposeful embarrassment (22%). Moreover, a significant number of American adults have experienced physical threats, sustained harassment, stalking and sexual harassment (10%, 7%, 7% and 6% respectively).
Hate speech itself has serious consequences for online behavior and general well-being. 95% of Americans consider it a serious problem. At 27%, more than one in four Americans have reported deciding not to post something when encountering hate speech toward another user. 13%, meanwhile, have stopped using a certain online platform after witnessing harassment. Ironically, protected as a form of free speech, hate speech has resulted in muting more than a quarter of internet users.
Who should address the issue
Considering both vox populi and practice, online platforms are to tackle the problem of user’s hate speech. According to the Pew Research Center report cited above, 79% of Americans say that online service and social network providers are responsible for addressing harassment. In Germany, companies may face a fine of up to 50m euro if they fail to remove within 24 hours illegal material, including fake news and hate speech.
Hate speech is not always as blatant as calling people names. It can come in many subtler forms, posing as neutral statements or even care. That’s why building more sophisticated AI models that can recognize even the subtlest forms of hate speech is called for.
How those models should be built
When building a machine learning-powered hate speech detector, the first challenge is to build and label the dataset. Given that the differences between hate speech and non-hate speech are highly contextual, constructing the definition and managing the dataset is a huge challenge. The context may depend on:
The context of the discussion – historical texts full of outdated expressions may be automatically (yet falsely) classified as hate speech
Example: Mark Twain’s novels use insulting language; citing them may set off hate speech bells.
How the language is used – in many countries, hate speech used for artistic purposes is tolerated.
Example: Hip-hop often uses misogynistic language while heavy metal (especially the more extreme sub-genres) is rife with anti-religious lyrics.
The relationship of the speaker to the group being hated – the members of a group are afforded more liberties with using aggressive or insulting language when addressing other members of that group than are those who are not a part of it.
Example: the term “sans-cullottes” was originally coined to ridicule the opponents of conservatives. It literally meant “people with no trousers” and was aimed at the working class, members of whom wore long trousers instead of the fashionable short variety. The term went on to enter the vernacular of the working classes in spite of its insulting origins.
Irony and sarcasm pose yet another challenge. According to Poe’s law, without smileys or other overt signs from the writer, ironic statements made online are indistinguishable from serious ones. In fact, the now-ubiquitous emoticons were invented by professors at Carnegie Mellon University to avoid mistakes.
When the dataset is ready, building a blacklist of the most common epithets and hate-related slurs may be helpful, as automation-based blacklist models are effective 60% of the time in spotting online hate speech (based on our in-house benchmarks). Building both supervised and unsupervised learning models to spot the new combinations of harmful words or finding existing ones may raise that effectiveness further. Hate speech is dynamic and thus evolves rapidly as new forms and insulting words emerge. By keeping an eye on conversations and general discourse, machine learning models can spot suspicious new phrases and alert administration.
A formula of hate
An automated machine learning model is able to spot the patterns of hate speech based on word vectors and the positions of words with certain connotations. Thus, it is easier to spot emerging hate speech that went undetected earlier, as current politics or social events may trigger new forms of online aggression.
Unfortunately, people spreading hate have shown serious determination to overcome automated systems of spotting hate speech by combining common ways of fooling machines (like using acronyms and euphemisms) and perpetuate hate.
Challenges and concerns
One of the main concerns in building machine learning models is finding a balance between the model’s vigilance and the number of false positives it returns. Considering the uneasy relations between hate speech and freedom of speech, producing too many false positives may be considered by users an attempt at censorship.
Another challenge is to build the dataset and label the data to train the model to recognize hate speech. As machines themselves are truly neutral, the person responsible for the dataset may be biased or at least influenced to profile the hate speech recognition model. Thus, the model may be built to purposefully produce false-positives in order to reduce the prevalence of certain views in a discussion.
https://deepsense.ai/wp-content/uploads/2019/02/How-artificial-intelligence-can-fight-hate-speech-in-social-media-platforms.png3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-01-24 14:38:322021-01-05 16:46:29How artificial intelligence can fight hate speech in social media
As the recently launched AI Monthly digest shows, significant improvements, breakthroughs and game-changers in machine learning and AI are months or even weeks away, not years. It is, therefore, worth the challenge to summarize and show the most significant AI trends that are likely to unfold in 2019, as machine learning technology becomes one of the most prominent driving forces in both business and society.
According to a recent Deloitte study, 82% of companies that have already invested in AI have gained a financial return on their investment. For companies among all industries, the median return on investment from cognitive technologies is 17%.
AI is transforming daily life and business operations in a way seen during previous industrial revolutions. Current products are being enhanced (according to 44% of respondents), internal (42%) and external (31%) operations are being optimized and better business decisions are being made (35%).
With that in mind, it is better to see the “Trend” as a larger and more significant development than a particular technology or advancement. That’s why chatbots or autonomous cars are not so much seen as particular trends, but rather as separate threads in the fabric that is AI.
That distinction aside, here are five of the most significant and inspiring artificial intelligence trends to watch in 2019.
1. Chatbots and virtual assistants ride the lightning
The ability to process natural language is widely considered a hallmark of intelligence. In 1950, Alan Turing proposed his famous test to determine if a particular computer is intelligent by asking the ordinary user to determine if his conversational partner is a human or a machine.
The famous test was initially passed in 1966 by ELIZA software, though it had nothing to do with natural language processing (NLP) – it was just a smart script that seemed to understand text. Today’s NLP and speech recognition solutions are polished enough not only to simulate understanding but also to produce usable information and deliver business value.
While still far from perfect, NLP has gained a reputation among businesses embracing chatbots. PwC states that customers prefer to talk with companies face-to-face but chatbots are their second preferred channel, slightly outperforming email. With their 24/7 availability, chatbots are perfect for emergency response (46% of responses in the PwC case study), forwarding conversations to the proper employee (40%) and placing simple orders (33%). Juniper Research predicts that chatbots will save companies up to $8bln annually by 2022.
NLP is also used in another hot tech trend–virtual assistants. According to Deloitte, 64% of smartphone owners say they use their virtual assistant (Apple Siri, Google’s Assistant) compared to 53% in 2017.
Finally, Gartner has found that up to 25% of companies will have integrated a virtual customer assistant or a chatbot into their customer service by 2020. That’s up from less than 2% in 2017.
2. Reducing the time needed for training
Academic work on AI often focuses on reducing the time and computing power required to train a model effectively, with the goal of making the technology more affordable and usable in daily work. The technology of artificial neural networks has been around for a while (theoretical models were designed in 1943), but it works only when there are enough cores to compute machine learning models. One way to ensure such cores are present is to design more powerful hardware, though this comes with limitations. Another approach is to design new models and improve existing ones to be less computing hungry.
AlphaGo, the neural network that vanquished human GO champion Lee Sidol, required 176 GPUs to be trained. AlphaZero, the next iteration of the neural network GO phenom, gained skills that had it outperforming AlphaGo in just three days using 4 TPUs.
Expert augmented learning is one of most interesting ways to reduce the effort required to build reinforcement-based models or at least ones that are reinforcement learning-enhanced. Contrary to policy-blending, expert augmented learning allows data scientists to channel their knowledge not only from another neural network but also from a human expert or another machine. Researchers at deepsense.ai have recently published a paper on using transfer learning to break Montezuma’s Revenge, a game that reinforcement learning agents had long struggled to break.
Another way to reduce the time needed to train a model is to optimize the hardware infrastructure required. Google Cloud Platform has offered a cloud-based tailored environment for building machine learning models without the need for investing in on-prem infrastructure. Graphics card manufacturer Nvidia is also pushing the boundaries, as GPUs tend to be far more effective in machine learning than CPUs.
Yet another route is to scale and redesign the architecture of neural networks to use existing resources in the most effective way possible. With its recently developed GPipe infrastructure, Google has been able to significantly boost the performance of Generative Adversarial Networks on an existing infrastructure. By using GPipe, researchers were able to improve the performance of ImageNet Top-1 Accuracy (84.3% vs 83.5%) and Top-5 Accuracy (97.0% vs 96.5%), making the solution the new state-of-the-art.
3. Autonomous vehicles’ speed rising
According to PwC estimates, 40% of mileage in Europe could be covered by autonomous vehicles by 2030. Currently, most companies are still developing the technology behind these machines. We are proud to say that deepsense.ai is contributing to the push. The process is driven mostly by the big social and economic benefits involved in automating as many driving processes as possible.
According to the US Department of Transportation, 63.3% of the $1,139 billion of goods shipped in 2017 were moved on roads. Had autonomous vehicles been enlisted to do the hauling, the transport could have been organized more efficiently, and the need for human effort vastly diminished. Machines can drive for hours without losing concentration. Road freight is globally the largest producer of emissions and consumes more than 70% of all energy used for freight. Every optimization made to fuel usage and routes will improve both energy and time management.
The good news here is that there are already advanced tests of the technology. Volvo has recently introduced Vera, the driverless track aimed at short-haul transportation in logistics centers and ports. Its fleet of cars is able to provide a constant logistics stream of goods with little human involvement.
In a related bid, US grocery giant Kroger recently started tests of unmanned delivery cabs, sans steering wheel and seats, for daily shopping. Bolder still are those companies (including Uber) testing their autonomous vehicles on the roads of real towns, while others build models running in sophisticated simulators.
With Kroger, Uber and Google leading the way, other companies are sure to fall into line behind them, forming one of most important AI trends 2019.
4. Machine learning and artificial intelligence will be democratized and productionized
There would be no machine learning without data scientists, of which there remain precious few, at least of the skilled variety. Job postings for data scientists rose 75% between 2015 and 2018 at indeed.com while job searches for this position rose 65%. According to Glassdoor data, data scientist was the hottest job in 2018. Due to the popularization of big data, artificial intelligence and machine learning, the demand for data science professionals will continue to rise. And that not only enterprise but also scientific researchers seek their skills certainly bodes well for the profession.
Despite being associated with high-tech companies, machine learning techniques are becoming more common in solving science-related problems. In the last quarter of 2018, Deepmind unveiled a tool to predict the way proteins fold. Another project enabled scientists to derive the laws of physics from fictional universes. According to O’Reilly data, 51% of surveyed organizations already use data science teams to develop AI solutions for internal purposes. The adoption of AI tools will no doubt be one of the most important AI trends in 2019, especially as business and tech giants are not the only organizations using AI in their daily work.
5. AI responsibility and transparency
Last but not least, as the impact of machine learning on business grows, so too does the social and legal impact. On the heels of the first fatal accident involving an autonomous car, the question of who is responsible for crashes and the famous trolley problem are getting more important.
At issue here, first and foremost, is hidden bias in data sets, a problem for any company using AI to power-up daily operations. That includes Amazon, which had put AI in charge of preprocessing resumes. Trained with 10 years worth of various resumes, the system was unintentionally biased against women applying for tech positions. With the rising adoption of machine learning models in various industries, the transparency of artificial intelligence will be on the rise. The issue of countering bias unconsciously developed within datasets and taken by machine learning models as truth incarnate is being discussed seriously by tech giants like Salesforce. The machine learning community has also taken up the problem: there is a Kaggle competition aimed at building unbiased and cultural context-agnostic image recognition models to use in computer vision.
Finally, as I alluded earlier, the question of who is responsible for actions taken by AI-powered devices and the famous trolley problem are both moving to the fore. If a self-driving car had a choice, should it hit an elderly person or a child? Focus on saving the life of a driver or a person walking by? According to a global study, the answers depend heavily on the culture the responder grew up in. When facing the extreme situation of a car accident today, it is the driver who is solely responsible for his or her choices. When the car is autonomous, however, and controlled by a virtual agent, all the choices are made by a neural network, which raises some very unsettling questions.
Of course, such problems are not confined to the realm of autonomous vehicles. Machine learning-powered applications are getting more and more attention as a tool for supporting medical treatment. Medical data is expected to rise at an exponential rate, with a compound annual growth rate of 36%. Considering the high level of standardization within diagnostic data, medical data is ripe for utilizing machine learning models, which can be employed to augment and support the treatment process.
When thinking about AI trends 2019, bank on more transparent and socially responsible models being built.
The take-away – the social context will be central to AI trends 2019
No longer are AI and machine learning confined to pure tech; they now have an impact on entire businesses and the whole of society. The common comparison with the steam engine revolution is an apt one – machine learning models will digitally transform both big and small business in ways never before seen.
Given that, picking AI trends 2019 only by selecting technology would be to miss a vital aspect of ongoing changes. That is, they are as ubiquitous as they are far-reaching.
https://deepsense.ai/wp-content/uploads/2019/02/ai-trends-2019.png3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-01-09 13:56:112023-07-05 02:13:59Five top artificial intelligence (AI) trends for 2019
December brought both year-end summaries and impressive research work pushing the boundaries of AI.
Contrary to many hi-tech trends, artificial intelligence is a popular term in society and there are many (not always accurate) views on the topic. The December edition of AI Monthly digest both shares the news about the latest developments and addresses doubts about this area of technology. Previous editions of AI Monthly digest:
Machines are getting better at image recognition and natural language processing. But several fields remain unpolished, leaving considerable room for improvement. One of these fields is music theory and analytics.
Music has different timescales, as some parts repeat at scale of seconds while others extend throughout an entire composition and sometimes beyond. Moreover, music composition employs a great deal of repetition.
Google’s Magenta-designed model leverages the relative attention to spot how far two tokens (motifs) are, and produced convincing and quite relaxing pieces of piano music. The music it generated generally evokes Bach more than Bowie, though.
Researchers provided samples of both great and flawed performances. Although AI-composed samples still refer to classical music, there are more jazz-styled improvisations.
Further information about studies on artificial music can be found on Magenta’s Music Transformer website. Why does it matter?
Music and sound is another type of data machine learning can analyze. Pushing research on music further will deepen our knowledge of music and styles in a way that AI made Kurt Vonnegut’s dream of analyzing literature a reality.
Furthermore, the music industry may be the next to leverage data and the knowledge and talents of computer scientists. Apart from tuning the recommendation engines for streaming services, they may contribute more to the creation of music. A keyboard is after all a musical instrument.
2. The machine style manipulator
Generating fake images from real ones is a thing. Generative Adversarial Networks enhance their training abilities by analyzing real images, generating fake ones and then training to be as good as possible in determining which is real and what is shown in the images.
The challenge neural networks and those who design them fact is in producing convincing images of people, cars, or anything else that is to be recognized by the networks. In a recent research paper, the group behind the “one hour of fake celebrity faces” project introduced a new neural network architecture that separates high-level attributes and stochastic variations. In the case of human images, the high-level attribute may be a pose while freckles or the hairdo are stochastic variations.
In a recent video, researchers show the results of applying a style-based generator and manipulating styles later to produce different types of images.
The results are impressive – researchers were able to produce convincing images of people from various ethnic backgrounds. By controlling different levels of styles, researchers were able to tune up everything on image – from gender and ethnicity to the shape of glasses worn. Why does it matter?
That’s basically the next state-of-the-art in GAN networks, the best-performing image recognition technology used. Producing fancy-looking fake images of faces and houses can significantly improve the performance of image recognition models. Ultimately, however, this technology may be a life saver, especially when applied in medical diagnosis, for example in diabetic retinopathy.
3. AI failures – errare (not only) humanum est
2018 saw significant improvements in machine learning techniques and artificial intelligence proved even further how useful it is. However, using it in day-to-day human life will not be without its challenges.
In his 1896 novel “An Outcast of the Islands”, Joseph Conrad wrote “It’s only those who do nothing that make no mistakes”. This idea can also be applied to theoretically mistake-proof machines. Apart from inspiring successes, 2018 also witnessed some significant machine learning failures:
Amazon’s gender-biased AI recruiter – the machine learning model designed to pre-process the resumes sent to the tech giant overlooked female engineers due to bias in the dataset. The reason was obvious – the tech industry is male-dominated. As algorithms have neither common sense nor social skills, it assumed that women are just not a good match for the tech positions the company was trying to fill. Amazon ditched the flawed recruiting tool, yet the questions about hidden bias in datasets remain.
World Cup predictions gone wrong – The World Cup gave us another bitter lesson, this time for predictive analytics. While the model built to predict brackets may have been sophisticated, it failed entirely. According to its predictions, Germany should have met Brazil in the finals. Instead, the German team didn’t manage to get out of its group while Brazil bent the knee before South Korea. The final came down to France versus Croatia, an unthinkable combination, both for machine learning and football enthusiasts around the world. The case was further described in our blogpost about failure in predictive analytics.
More examples of AI failures can be found in the Synced Review Medium blogpost. Why does it matter?
Nobody’s perfect. Including machines. That’s why users and designers need to be conscious of the need to make machine learning models transparent. What’s more, it is the next voice to ensure that machine learning model results are validated – a step that is tempting to overlook for early adopters.
4. Smartphone-embedded AI may detect the first signs of depression
A group of researchers from Stanford University has trained a model with pictures and videos of people who are depressed and people who are not. The model analyzed all the signals the subjects sent, including tone of voice, facial expressions and general behaviour. These were observed during interviews conducted by an avatar controlled by a real physician. The model proved effective in detecting depression more than 80% of the time. The machine was able to recognize slight differences between people suffering from depression and people who were not. Why does it matter? According to WHO, depression is the leading cause of disability worldwide. If not cured, it can lead to suicide, the second most common cause of death among 15-29-year-olds.
One barrier to helping people suffering from depression is inaccurate assessment. There are regions in the world where less than 10% of people have access to proper treatment. What’s more, mental illness is often stigmatized, and treatment is both costly and hard to access. These factors, and the fact that early symptoms are easily overlooked, lead many patients to avoid looking for care and medical support.
The experiment is a step toward building an automated and affordable system for spotting signs of depression early on, when the chance for a cure is highest.
5. So just how can AI hurt us?
Machine learning is one of the most exciting technologies of the twenty-first century. But science fiction and common belief have provided no lack of doomsday scenarios of AI harming people or even taking over the world. Dispelling the myths and disinformation and providing knowledge should be a mission all AI-developing companies. If you’re new to the discussion, here’s an essay addressing the threat of AI. Why does it matter?
Leaving the doubts unaddressed may result in bias and prejudice when making decisions, both business and private ones. The key to making the right decisions is to be informed on all aspects of the issue. Pretending that Stephen Hawking’s and Elon Musk’s warnings about the cataclysmic risks AI poses were pointless would indeed be unwise.
On the other hand, the essay addresses less radical fears about AI, like hidden bias in datasets leading to machine-powered discrimination or allowing AI to go unregulated.
That’s why the focus on machine morality and the transparency of machine learning models is so important and comes up so frequently in AI Monthly digest.
Summary
December is the time to go over the successes and failures of the past year, a fact that applies equally to the machine learning community. Facing both the failures and challenges provides an opportunity to address common issues and make the upcoming work more future-proof.
https://deepsense.ai/wp-content/uploads/2019/02/AI-Monthly-digest-4-artificial-intelligence-and-music-a-new-GAN-standard-and-fighting-depression.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2019-01-07 16:07:132021-01-05 16:46:40AI Monthly digest #4 – artificial intelligence and music, a new GAN standard and fighting depression