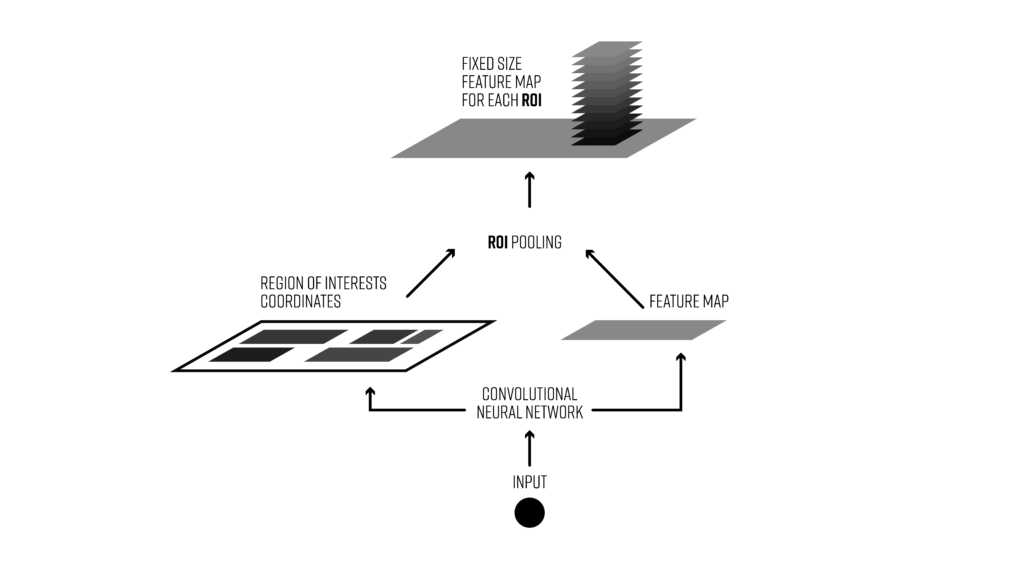
How to create a product recognition solution
Product recognition is a challenging area that offers great financial promise. Automatically detected product attributes in photos should be easy to monetize, e.g., as a basis for cross-selling and upselling.
However, product recognition is a tough task because the same product can be photographed from different angles, in different lighting, with varying levels of occlusion, etc. Also, different fine-grained product labels, such as ones in royal blue or turquoise, may prove difficult to distinguish visually. Fortunately, properly tuned convolutional neural networks can effectively resolve these problems.
In this post, we discuss our solution for the iMaterialist challenge announced by CVPR and Google and hosted on Kaggle in order to show our approach to product recognition.
The problem
Data and goal
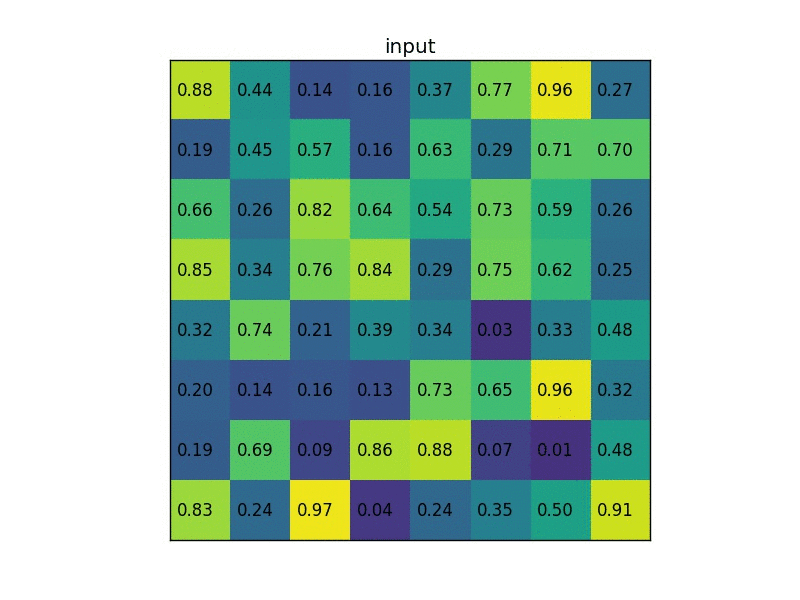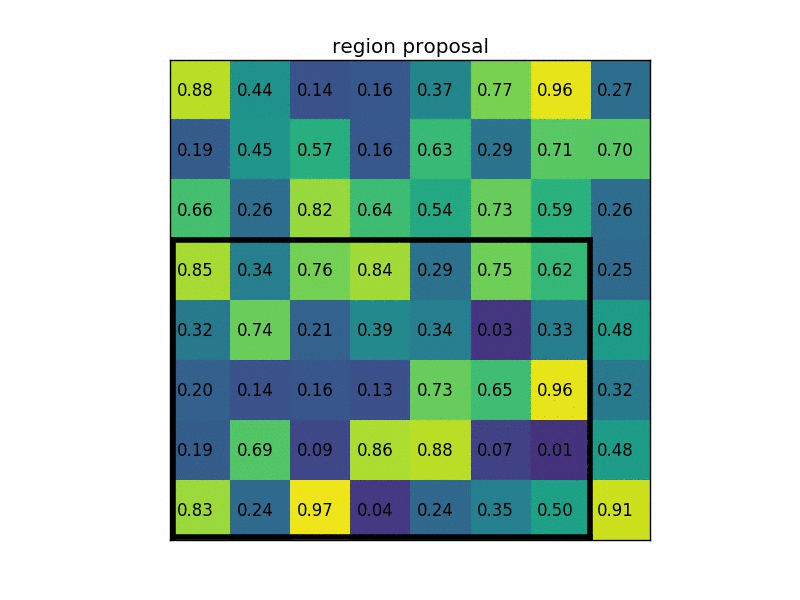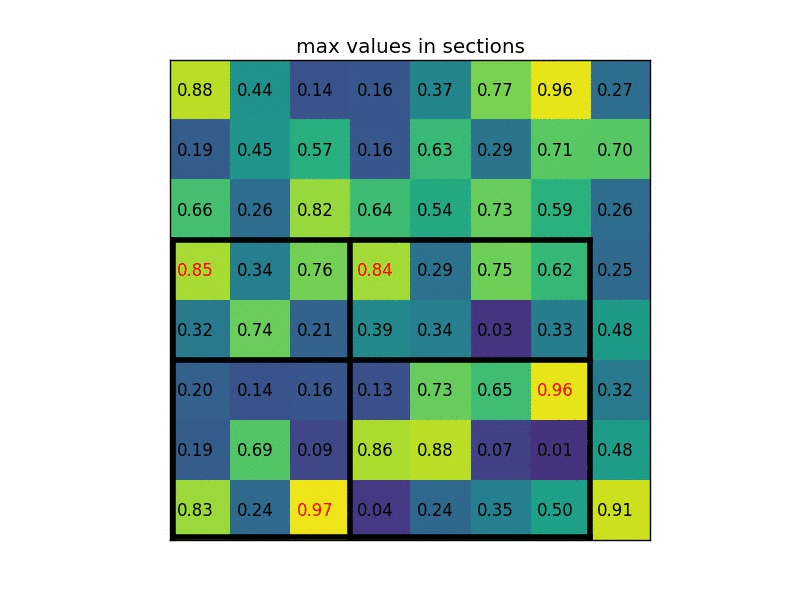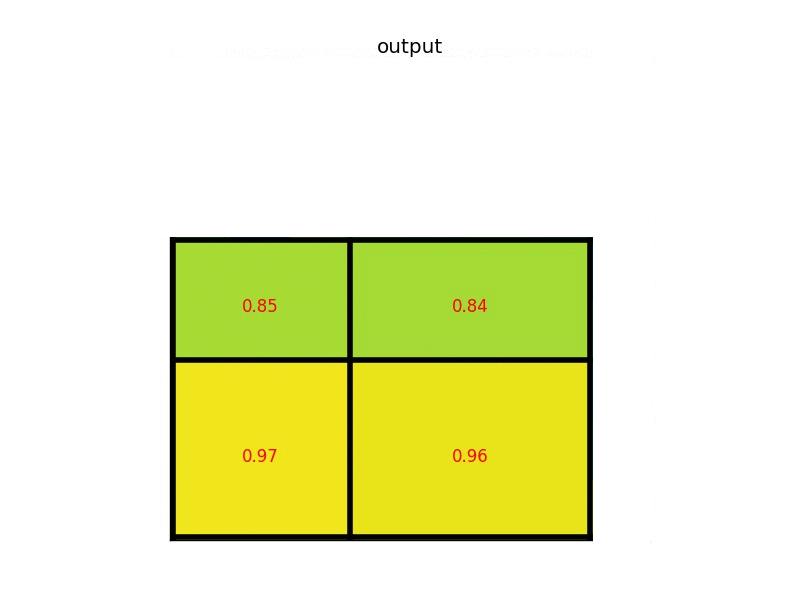
The iMaterialist organizer provided us with hyperlinks to more than 50,000 pictures of shoes, dresses, pants and outerwear. Some tasks were attached to every picture and some labels were matched to every task. Here are some examples:




Our goal was to match a proper label to every task for every picture from the test set. From the machine learning perspective this was a multi-label classification problem.
There were 45 tasks in total (a dozen per cloth type) and we had to predict a label for all of them for every picture. However, tasks not attached to the particular test image were skipped during the evaluation. Actually, usually only a few tasks were relevant to a picture.
Problems with data
There were two main problems with data:
- We weren’t given the pictures themselves, but only the hyperlinks. Around 10% of them were expired, so our dataset was significantly smaller than the organizer had intended. Moreover, the hyperlinks were a potential source of a data leak. One could use text-classification techniques to take advantage of leaked features hidden in hyperlinks, though we opted not to do that.
- Some labels with the same meaning were treated by the organizer as different, for example “gray” and “grey”, “camo” and “camouflage”. This introduced noise in the training data and distorted the training itself. Also, we had no choice but to guess if a particular picture from the test set was labeled by the organizer as either “camo” or “camouflage”.
Evaluation
The evaluation score function was the average error over all test pictures and relevant tasks. A score value of 0 meant that all the relevant tasks for all the test pictures were properly labeled, while a score of 1 implied that no relevant task for any picture was labeled correctly. A random sample submission provided by the organizer yielded a score greater than 0.99. Hence we knew that a good result couldn’t be achieved by accident and we would need a model that could actually learn how to solve the problem.
Our solution
A bunch of convolutional neural networks
Our solution consisted of about 20 convolutional neural networks. We used the following architectures in several variants:
All of them were initialized with weights pretrained on the ImageNet dataset. Our models also differed in terms of the data preprocessing (cropping, normalizing, resizing, switching of color channels) and augmentation applied (random flips, rotations, color perturbations from Krizhevsky’s AlexNet paper). All the neural networks were implemented using the PyTorch framework.
Choosing the training loss function
Which loss function to choose for the training stage was one of the major problems we faced. 576 unique pairs of task/label occurred in the training data so the outputs of our networks were 576-dimensional. On the other hand, typically only a few labels were matched to a picture’s tasks. Therefore the ground truth vector was very sparse – only a few of its 576 coordinates were nonzero – so we struggled to choose the right training loss function.
Assume that \((z_1,…,z_{576})in mathbb{R}^{576}\) is a model output and
[y_i=left{begin{array}{ll}1, & text{if task/label pair }itext{ matches the picture,}, & text{elsewhere,}end{array}right.quadtext{for } i=1,2,ldots,576.]
- As this was a multi-label classification problem, choosing the popular crossentropy loss function:
\([sum_{i=1}^{576}-y_ilog p_i,quad text{where } p_i=frac{exp(z_i)}{sum_{j=1}^{576}exp(z_j)},]\)
wouldn’t be a good idea. This loss function tries to distinguish only one class from others. - Also, for the ‘element-wise binary crossentropy’ loss function:
\([sum_{i=1}^{576}-y_ilog q_i-(1-y_i)log(1-q_i),quad text{where } q_i=frac{1}{1+exp(-z_i)},]\)
the sparsity caused the models to end up constantly predicting no labels for any picture. - In our solution, we used the ‘weighted element-wise crossentropy’ given by:
\([sum_{i=1}^{576}-bigg(frac{576}{sum_{j=1}^{576}y_j}bigg)cdot y_ilog q_i-(1-y_i)log(1-q_i),quad text{where } q_i=frac{1}{1+exp(-z_i)}.]\)
This loss function focused the optimization on positive cases.
Ensembling
Predictions from particular networks were averaged, all with equal weights. Unfortunately, we didn’t have enough time to perform any more sophisticated ensembling techniques, like xgboost ensembling.
Other techniques tested
We also tested other approaches, though they proved less successful:
- Training the triplet network and then training xgboost models on features extracted via embedding (different models for different tasks).
- Mapping semantically equivalent labels like “gray” and “grey” to a common new label and remapping those to the original ones during postprocessing.
Neptune
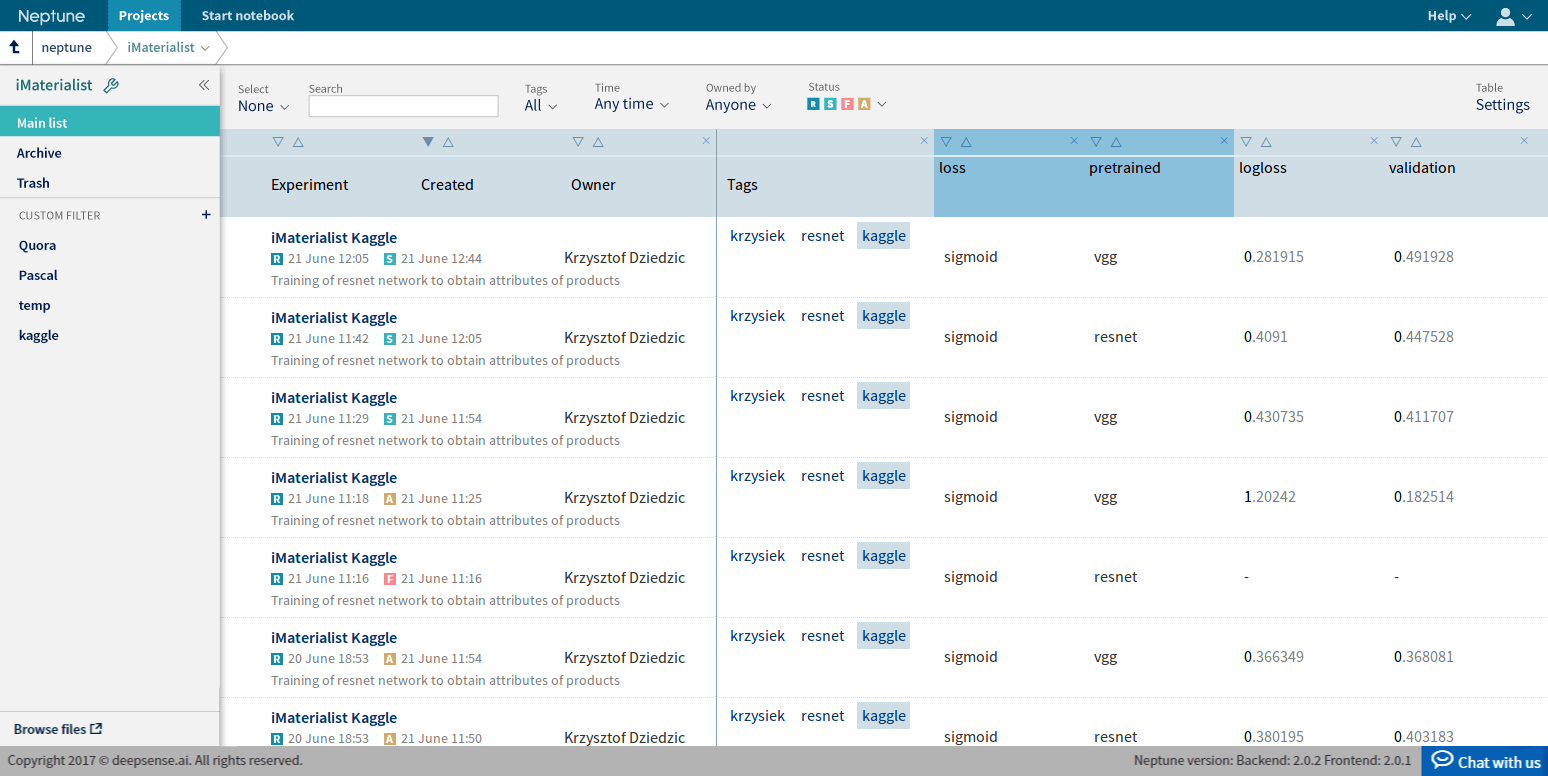
We managed all of our experiments using Neptune, deepsense.ai’s Machine Learning Lab. Thanks to that, we were easily able to track the tuning of our models, compare them and recreate them.
Results
We achieved a score of 0.395, which means that we correctly predicted more than 60% of all the labels matched to relevant tasks.
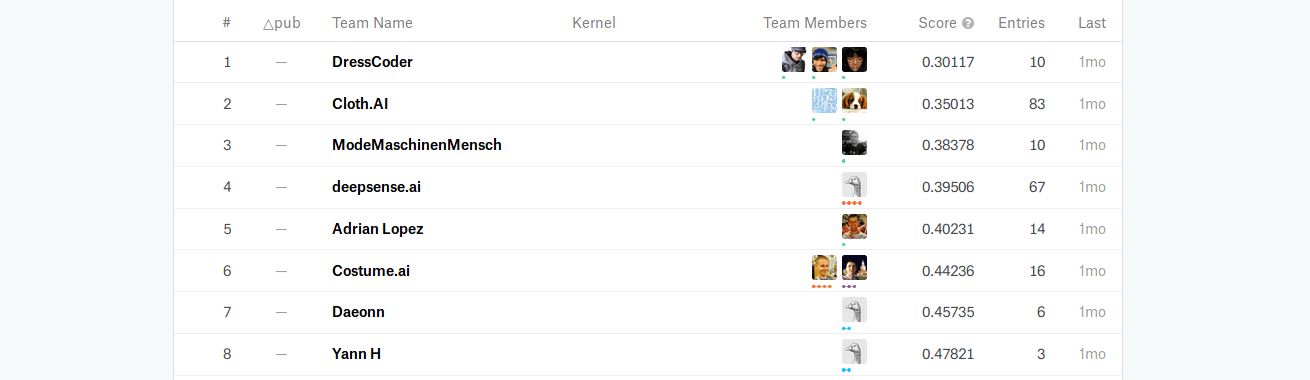
We are pleased with this result, though we could have improved on it significantly if the competition had lasted longer than only one month.
Summary
Challenges like iMaterialist are a good opportunity to create product recognition models. The most important tools and tricks we used in this project were:
- Playing with training loss functions. Choosing the proper training loss function was a real breakthrough as it boosted accuracy by over 20%.
- A custom training-validation split. The organizer provided us with a ready-made training-validation split. However, we believed we could use more data for training so we prepared our own split with more training data while maintaining sufficient validation data.
- Using the PyTorch framework instead of the more popular TensorFlow. TensorFlow doesn’t provide the official pretrained models repository, whereas PyTorch does. Hence working in PyTorch was more time-efficient. Moreover, we determined empirically that, much to our surprise, the same architectures yielded better results when implemented in PyTorch than in TensorFlow.
We hope you have enjoyed this post and if you have any questions, please don’t hesitate to ask!