Running distributed TensorFlow on Slurm clusters
In this post, we provide an example of how to run a TensorFlow experiment on a Slurm cluster. Since TensorFlow doesn’t yet officially support this task, we developed a simple Python module for automating the configuration. It parses the environment variables set by Slurm and creates a TensorFlow cluster configuration based on them. We’re sharing this code along with a simple image recognition example on CIFAR-10. You can find it in our github repo.
But first, why do we even need distributed machine learning?
Distributed TensorFlow
When machine learning models are developed, training time is an important factor. Some experiments can take weeks or even months on a single machine. Shortening this time enables us to try out more approaches, test many similar models and use the best one. That’s why it’s useful to use multiple machines for faster training.
One of of TensorFlow’s strongest points is that it’s designed to support distributed computation. To use multiple nodes, you just have to create and start a tf.train.Server and use a tf.train.MonitoredTrainingSession.
Between Graph Replication
In our example we’re going be using a concept called ‘Between Graph Replication’. If you’ve ever run MPI jobs or used the ‘fork’ system call, you’ll be familiar with it.
In Distributed TensorFlow, Between Graph Replication means that when several processes are being run on different machines, each process (worker) runs the same code and constructs the same TensorFlow computational graph. However, each worker uses a discriminator (the worker’s I.D., for example) to execute instructions differently from the rest (e.g. process different batches of the training data).
This information is also used to make processes on some machines work as ‘Parameter Servers’. These jobs don’t actually run any computations – they’re only responsible for storing the weights of the model and sending them over the network to other processes.
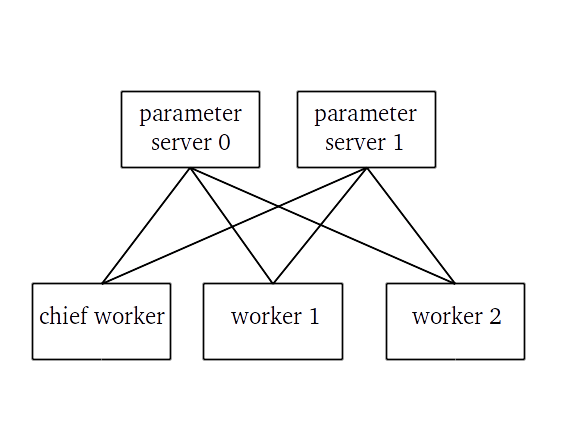
Connections between tasks in a distributed TensorFlow job with 3 workers and 2 parameter servers.
Apart from the worker I.D. and the job type (normal worker or parameter server), TensorFlow also needs to know the network addresses of other workers performing the computations. All this information should be passed as configuration for the tf.train.Server. However, keeping track of it all in addition to starting multiple processes on multiple machines with different parameters can be really tedious. That’s why we have cluster managers, such as Slurm.
Slurm
Slurm is a workload manager for Linux used by many of the world’s fastest supercomputers. It provides the means for running computational jobs on multiple nodes, queuing the jobs until sufficient resources are available and monitoring jobs that have been submitted. For more information about Slurm, you can read the official documentation here.
When running a Slurm job you can discover other nodes taking part by examining environment variables:
- SLURMD_NODENAME – name of the current node
- SLURM_JOB_NODELIST – number of nodes the job is using
- SLURM_JOB_NUM_NODES – list of all nodes allocated to the job
Our python module parses these variables to make using distributed TensorFlow easier. With the tf_config_from_slurm function you can automate this process. Let’s see how it can be used to train a simple CIFAR-10 model on a CPU Slurm cluster.
Distributed TensorFlow on Slurm
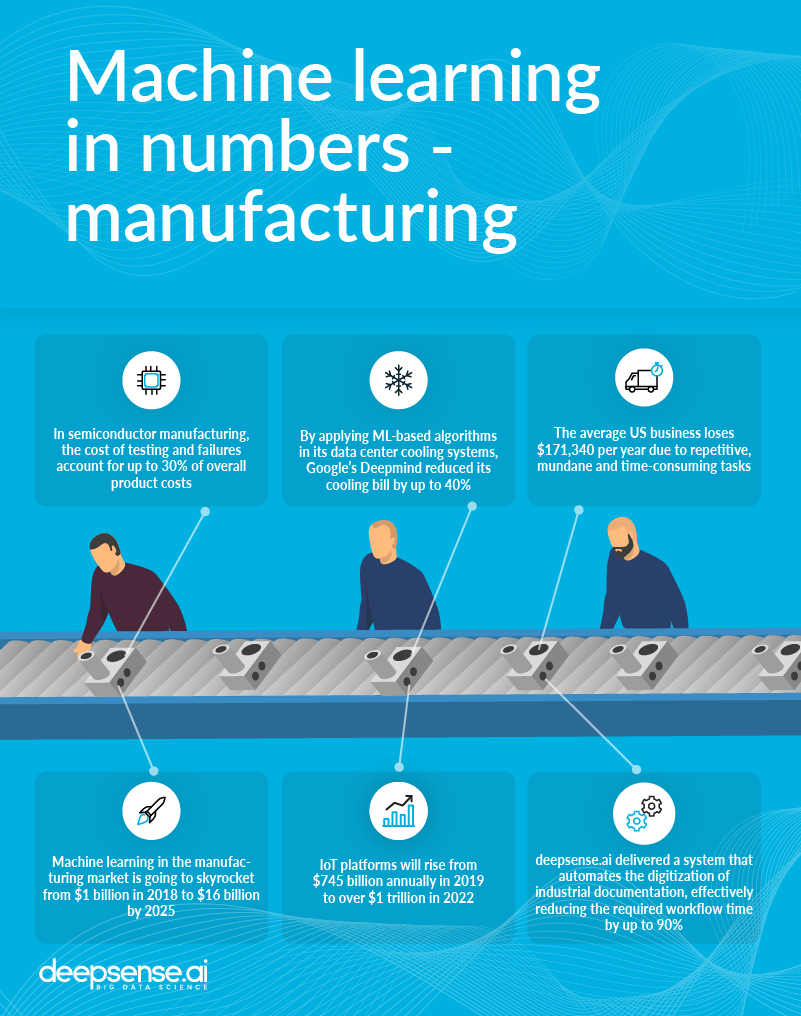
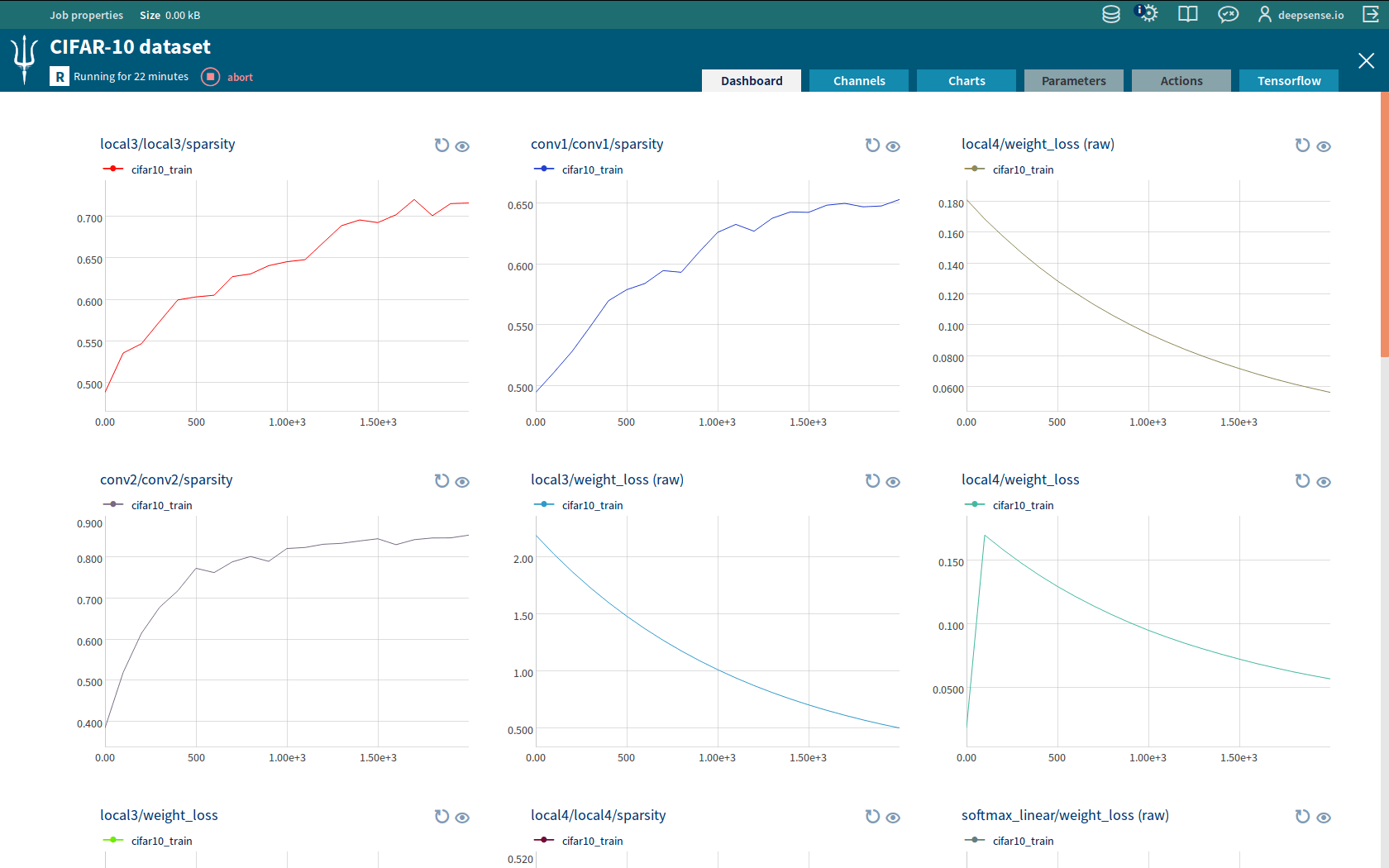
In this section we’re going to show you how to run TensorFlow experiments on Slurm. A complete example of training a convolutional neural network on the CIFAR-10 dataset can be found in our github repo, so you might want to take a look at it. Here we’ll just examine the most interesting parts.
Most of the code responsible for training the model comes from this TensorFlow tutorial. The modifications allow the code to be run in a distributed setting on the CIFAR-10 dataset. Let’s examine the changes one by one.
Starting the Server
import tensorflow as tf
from tensorflow_on_slurm import tf_config_from_slurm
cluster, my_job_name, my_task_index = tf_config_from_slurm(ps_number=1)
cluster_spec = tf.train.ClusterSpec(cluster)
server = tf.train.Server(server_or_cluster_def=cluster_spec,
job_name=my_job_name, task_index=my_task_index)
if my_job_name == 'ps':
server.join()
sys.exit(0)
Here we import our Slurm helper module and use it to create and start the tf.train.Server. The tf_config_from_slurm function returns the cluster spec necessary to create the server along with the task name and task index of the current job. The ‘ps_number’ parameter specifies how many parameter servers to set up (we use 1). All other nodes will be working as normal workers and everything gets passed to the tf.train.Server constructor.
Afterwards we immediately check whether the current job is a parameter server. Since all the work in a parameter server (ps) job is handled by the tf.train.Server (which is running in a separate thread), we can just call server.join() and not execute the rest of the script.
Placing the Variables on a parameter server
def weight_variable(shape):
with tf.device("/job:ps/task:0"):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
with tf.device("/job:ps/task:0"):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
These two functions are used when defining the model parameters. Note the “with tf.device(“/job:ps/task:0”)” statements telling TensorFlow that the variables should be placed on the parameter server, thus enabling them to be shared between the workers. The “0” index denotes the I.D. of the parameter server used to store the variable. Here we’re only using one server, so all the variables are placed on task “0”.
Optimizer
loss = tf.reduce_mean(cross_entropy)
opt = tf.train.AdamOptimizer(1e-3)
opt = tf.train.SyncReplicasOptimizer(opt, replicas_to_aggregate=len(cluster['worker']),
total_num_replicas=len(cluster['worker']))
is_chief = my_task_index == 0
sync_replicas_hook = opt.make_session_run_hook(is_chief)
train_step = opt.minimize(loss, global_step)
Instead of using the usual AdamOptimizer, we’re wrapping it with the SyncReplicasOptimizer. This enables us to prevent the application of stale gradients. In distributed training, the network communication may introduce communication delays which make it harder to train the model.
Creating the session
sync_replicas_hook = opt.make_session_run_hook(is_chief)
sess = tf.train.MonitoredTrainingSession(master=server.target,
is_chief=is_chief,
hooks=[sync_replicas_hook])
batch_size = 64
max_epoch = 10000
In distributed settings we’re using the tf.train.MonitoredTrainingSession instead of the usual tf.Session. This ensures the variables are properly initialized. It also allows you to restore a previously saved model and control how the summaries and checkpoints are written to disk.
Training
During the training, we split the batches between workers so everyone has their own unique batch subset to train on:
for i in range(max_epoch):
batch = mnist.train.next_batch(batch_size)
if i % len(cluster['worker']) != my_task_index:
continue
_, train_accuracy, xentropy = sess.run([train_step, accuracy, cross_entropy],
feed_dict={x: batch[0], y_: batch[1],
keep_prob: 0.5})
Summary
We hope this example was helpful in your experiments with TensorFlow on Slurm clusters. If you’d like to reproduce it or use our Slurm helper module in your experiments, don’t hesitate to clone our github repo.